一、基本信息
1、本次作业的地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
2、项目Git地址:https://gitee.com/ntucs/PairProg/tree/SE034_035/
二、项目分析
(1)程序运行模块(方法、函数)介绍
①任务一:给定一段英文字符串文件,统计其中各个英文单词的出现频率,将结果输入result.txt文件
# filename: WordCount.py # 注意:代码风格 import argparse import re import cProfile import pstats from string import punctuation def process_file(dst): # 读文件到缓冲区 try: # 打开文件 d = open(dst, "r") except IOError as s: print(s) return None try: # 读文件到缓冲区 bvffer = d.read() except: print('Read File Error!') return None d.close() return bvffer def process_transform(bvffer): # 将文本中的大写转换为小写且进行非法字符的转换 if bvffer: bvffer = bvffer.lower() # 将文本中的大写字母转换为小写 for ch in '{}!"#%()*+-,-./:;<=>?&@“”[]^_|': bvffer = bvffer.replace(ch, " ") # 将文本中非法字符转化为空格 words = bvffer.split() # 用空格分割字符串 return words def process_rowCount(bvffer): # 计算文章的行数 if bvffer: count = 1 for word in bvffer: # 开始计数 if word == ' ': count = count + 1 print("lines:{:}".format(count)) f = open('result.txt', 'w') print("lines:{:}".format(count),file=f) f.close() def process_wordNumber(words): # 通过正则表达式证明是否符合单词标准,计算单词个数且返回单词字典 if words: wordNew = [] words_select = '[a-z]{4}(w)*' for i in range(len(words)): word = re.match(words_select, words[i]) # 如果不匹配,返回NULL类型 if word: wordNew.append(word.group()) print("words:{:}".format(len(wordNew))) f = open('result.txt', 'a') print("words:{:}".format(len(wordNew)),file=f) f.close() return wordNew def process_stopwordSelect(words, stopwords): word_freq = {} # 统计每个单词的频率,存放在字典word_freq for word in words: # 开始计数,将转换好的words中踢除stopwords.txt中的单词 if word in stopwords: continue else: word_freq[word] = word_freq.get(word, 0) + 1 # 将符合的单词进行计数统计 return word_freq def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 频率高的 print("<{:}>:{:}".format(item[0], item[1])) f = open('result.txt','a') print("<{:}>:{:}".format(item[0], item[1]), file=f) f.close() def main(): #dst_Aimtxt = 'src/Gone_with_the_wind.txt' dstSecond = 'src/stopword.txt' parser = argparse.ArgumentParser() parser.add_argument('dst') args = parser.parse_args() dst = args.dst bvfferOne = process_file(dst) # 读目标txt文件 bvfferSecond = process_file(dstSecond) # 读stopword.txt文件 process_rowCount(bvfferOne) # 读目标txt文件的文章有多少行 bvffertransformOne = process_transform(bvfferOne) # 将目标txt文件中的文章文体及字符转换 bvffertransformSecond = process_transform(bvfferSecond) # 将stopword.txt文件中的文章文体及字符转换 wordNew = process_wordNumber(bvffertransformOne) # 计算目标txt文件中单词的个数 word_freq = process_stopwordSelect(wordNew, bvffertransformSecond) # 输出转换好的words中踢除stopwords.txt中的前10个单词 output_result(word_freq) if __name__ == "__main__": # 把分析结果保存到文件中 cProfile.run("main()", filename="result.wordcount") # 创建Stats对象 p = pstats.Stats("result.wordcount") # 按调用的次数进行排序,打印前10行 p.strip_dirs().sort_stats("calls").print_stats(10) # 按照运行时间和函数名进行排序,打印前10行 p.strip_dirs().sort_stats("cumulative", "name").print_stats(10) # 如果想知道有哪些函数调用了process_transform p.print_callers(0.5, "process_transform") # 如果想知道有哪些函数调用了process_rowCount p.print_callers(0.5, "process_rowCount") # 如果想知道有哪些函数调用了process_wordNumber p.print_callers(0.5, "process_wordNumber") # 如果想知道有哪些函数调用了process_stopwordSelect p.print_callers(0.5, "process_stopwordSelect") # 如果想知道有哪些函数调用了process_twoPhrase p.print_callers(0.5, "process_twoPhrase") # 如果想知道有哪些函数调用了process_threePhrase p.print_callers(0.5, "process_threePhrase") # 如果想知道有哪些函数调用了output_result p.print_callers(0.5, "output_result") # 查看process_buffer()函数中调用了哪些函数 #p.print_callees("process_buffer")
(1.1)统计文件的有效行数。
通过文章中换行最后都会出现字符” “来进行统计的。
def process_rowCount(bvffer): # 计算文章的行数 if bvffer: count = 1 for word in bvffer: # 开始计数 if word == ' ': count = count + 1 print("lines:{:}".format(count))
(1.2)统计文件的单词总数。
通过正则表达式来证明是否符合单词的标准,最后输出一个全是符合单词标准的List表
【正则表达式参考:https://blog.csdn.net/mark555/article/details/22379757
和 https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/1700215】
def process_wordNumber(words): # 通过正则表达式证明是否符合单词标准,计算单词个数且返回单词字典 if words: wordNew = [] words_select = '[a-z]{4}(w)*' for i in range(len(words)): word = re.match(words_select, words[i]) # 如果不匹配,返回NULL类型 if word: wordNew.append(word.group()) print("words:{:}".format(len(wordNew)))
(1.3)统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
在统计单词的出现频率的时候,我们还加入了停词表stopword.txt,计数转换好且都符合单词标准的List表,并且剔除stopword.txt中的单词频率。
def process_stopwordSelect(words, stopwords): word_freq = {} # 统计每个单词的频率,存放在字典word_freq for word in words: # 开始计数,将转换好的words中踢除stopwords.txt中的单词 if word in stopwords: continue else: word_freq[word] = word_freq.get(word, 0) + 1 # 将符合的单词进行计数统计 return word_freq
②任务一:通过停词表stopword.txt去剔除一些无用的单词(例如“there”、“was”等);统计高频词组。
我们已经在任务一上已经将停词表应用了,下面着重讲诉统计高频词组。我们在统计高频词组时候是在任务一的基础上将统计高频词组进行封装,下面只展示封装部分。
我们的想法是:将转换为小写、去除非法字符且都满足单词标准的单词两两组合或者三个三个组合,最后达到统计的效果。
def process_twoPhrase(words): useless_twoPhrase =['they were','would have','there were','have been','that would'] words_group = [] for i in range(len(words) - 1): str = '%s %s' % (words[i], words[i + 1]) words_group.append(str) word_freq = {} for word in words_group: if word in useless_twoPhrase: continue else: word_freq[word] = word_freq.get(word, 0) + 1 # 将词组进行计数统计 return word_freq def process_threePhrase(words): words_group = [] for i in range(len(words) - 2): str = '%s %s %s' % (words[i], words[i + 1], words[i + 2]) words_group.append(str) word_freq = {} for word in words_group: word_freq[word] = word_freq.get(word, 0) + 1 # 将词组进行计数统计 return word_freq
(2)程序算法的时间、空间复杂度分析。
(2.1)程序算法的时间
①任务一:

②任务二:

(2.2)空间复杂度分析
就process_twoPhrase()这个函数而言,里面有两个for循环,而且for循环内部也没有循环。我们可以大致估计空间复杂度为O(N+n)。
(3)程序运行案例截图。
①任务一:
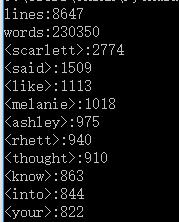
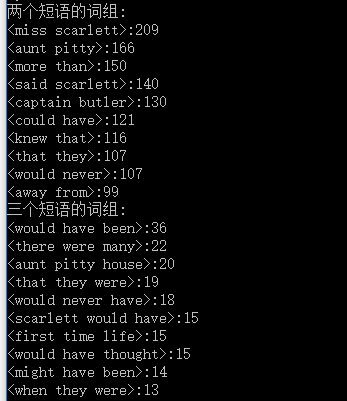
②任务二:
三、性能分析
(1)调用的函数次数进行排序,输出前10行

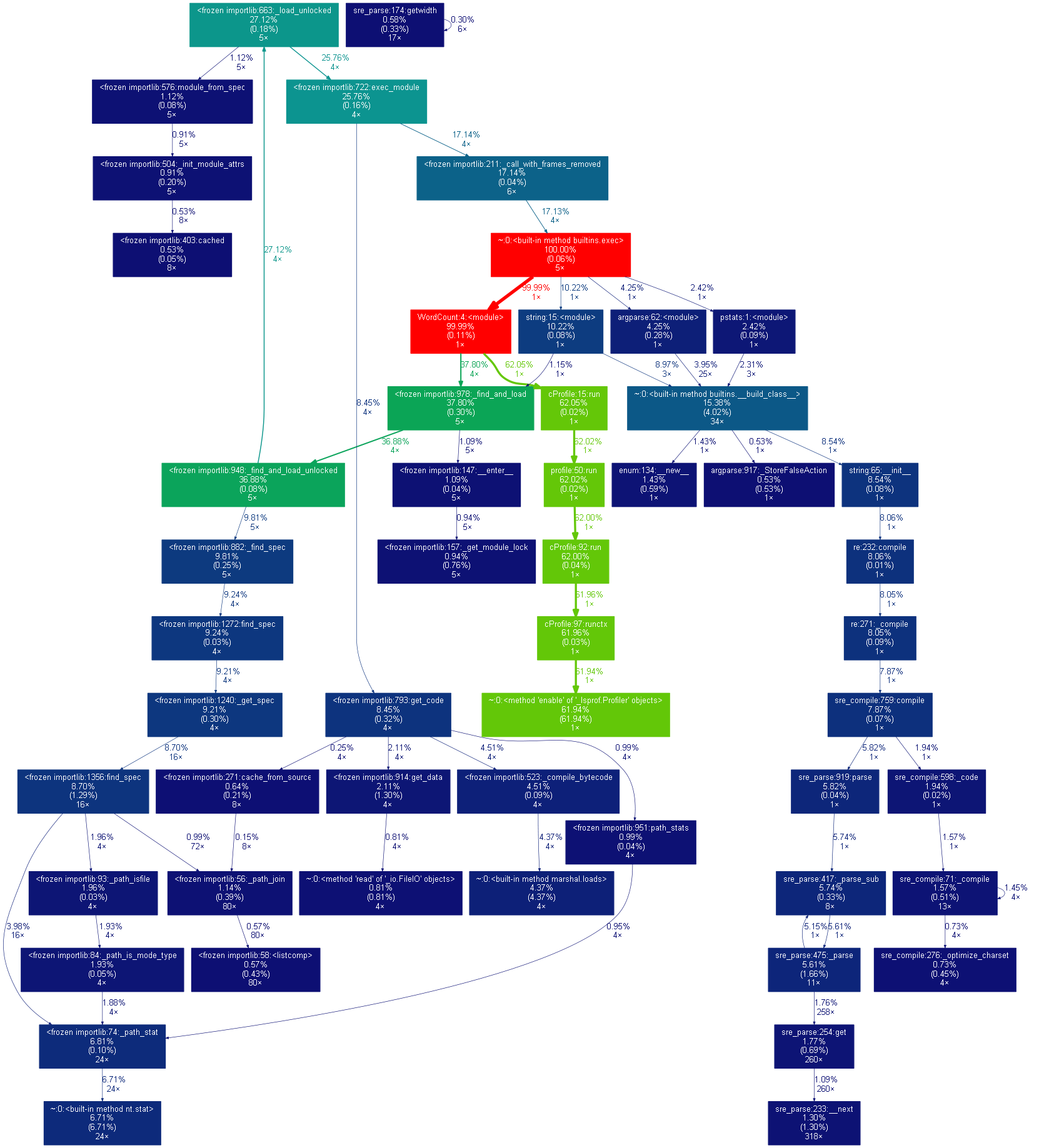
(2)性能图表
四、结对编程开销时间及照片
(1)结对编程开销时间花费了一周时间左右。
(2)结对编程照片

五、事后分析与总结
(1)对某个问题的讨论决策过程
我们在统计高频词组的时候,当时讨论了两种统计高频词组的方法:一、单词两两结合,三个三个结合;二、利用正则表达式进行统计。接着,我们还讨论是不是在统计高频词组的时候是否也需要停词表。
(2)评价对方
陈原对周怡峰的评价:周怡峰在编程方面基础非常不错,而且在合作的过程中积极为项目做巨大的贡献,在查阅资料与学习方面不遗余力。非常有自己的想法,为我们的编程带来了很多动力和乐趣,与之合作非常愉快。
周怡峰对陈原的评价:陈原编写了大部分的代码,在学习能力方面十分出色,从阅读python书籍到可以编写代码用了4-5天的时间,积极思考问题,我不会的地方会提供帮助。在写博客时也非常追求完美,希望下次合作。
(3)评价整个过程:关于结对过程的建议
对于结对编程,我们应该在结束之后积极思考它与我们单独编程有什么区别。这次锻炼也给我们提供了一次很好的经历,在结对编程中我们都要积极参与,这样我们才能积极积累很多经验,也学到了很多,希望我们以后能有更多的机会进行结对编程。