从网络请求回来的数据格式可能是.xml文件格式,常见的有:DOM树结构,下面讲述如何解析。具体可以参考博客文章:http://www.cnblogs.com/shenliang123/archive/2012/05/11/2495252.html
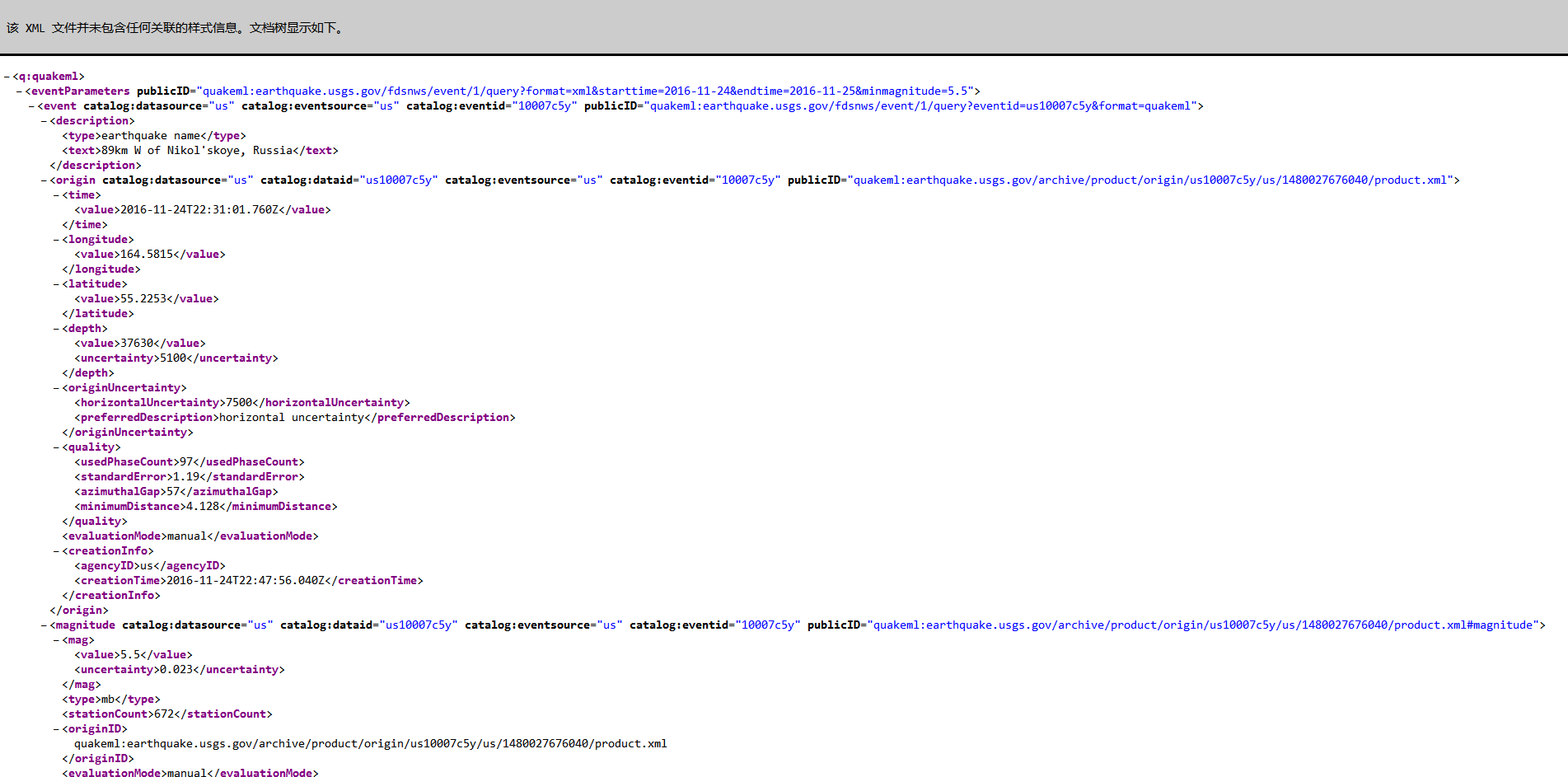
解析方式如下:
if (responseCode == httpURLConnection.HTTP_OK) {
LogUtil.d(TAG, "refreshEarthquakes::HttpURLConnection.HTTP_OK");
InputStream in = httpURLConnection.getInputStream();
DocumentBuilderFactory dbf = DocumentBuilderFactory
.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document dom = db.parse(in);
Element docEle = dom.getDocumentElement();
quakeData.clear();
// xml文件的<event>标签的个数
NodeList nl = docEle.getElementsByTagName("event");
LogUtil.d(TAG,
"refreshEarthquakes::nl.getLength=" + nl.getLength());
if (nl != null && nl.getLength() > 0) {
// 若对应有1个或多个<event>元素,遍历单个<event>元素;每一个<event>都生成一个Quake实例
for (int i = 0; i < nl.getLength(); i++) {
// 对应一个<event>标签元素
Element entry = (Element) nl.item(i);
// 获取到名称
String quakeName = entry.getElementsByTagName("text")
.item(0).getTextContent();
LogUtil.d(TAG, "name=" + quakeName);
// 获取时间
String quakeTime = entry.getElementsByTagName("time")
.item(0).getTextContent();
LogUtil.d(TAG, "quakeTime=" + quakeTime);
// 获取等级
Node magNode = entry.getElementsByTagName("mag")
.item(0);
String magnitude = magNode.getChildNodes().item(0)
.getTextContent();
double value = Double.parseDouble(magnitude);
// 获取其下的子节点
LogUtil.d(TAG, "magnitude = " + magnitude);
// 生成一个Quake实例
final Quake quake = new Quake(quakeTime, quakeName,
null, value, null);
handler.post(new Runnable() {
@Override
public void run() {
addNewQuake(quake);
}
});
}
}
}
根据标签名获取到节点树,比如上述的节点名:text(但必须保证该节点名是唯一的);另一种方式:通过节点名获取到其下的NodeList实例,也就是获取到节点列表,再获取到内容即可。
