基于双目深度估计的深度学习技术研究
英文标题: A Survey on Deep Learning Techniques for Stereo-based Depth Estimation
论文地址: https://arxiv.org/abs/2006.02535
0.摘要
从彩色图像中估计深度是一个长期存在的不适定问题(ill-posed problem),其已经在计算机视觉、图形学和机器学习领域中被研究了数十年。在现有技术中,由于与人类的双目系统有着紧密联系,立体匹配是应用最广泛的技术之一。在传统方法中,基于立体视觉的深度估计通过在多张图片上、匹配手工提取的特征来解决。尽管进行了广泛的研究,这些传统方法仍然受复杂纹理区域、较大的难以区别的区域以及遮挡的影响。由于在解决各种2D和3D视觉问题上获得的成功,使用深度学习解决基于立体视觉的深度估计问题的方法受到了广泛的关注,在2014年-2019年之间,该领域发表了150多篇论文。这种新的方法已经展示出了其在性能上的巨大飞跃,使自动驾驶、增强现实(AR)之类的应用成为可能。在本文中,我们提供了这一全新的并且不断发展的研究领域的全面调查,总结了最常用的流程(pipeline),并且讨论了它们的优点和局限性。在回顾了它们迄今为止已经取得的成就后,我们还推测了基于深度学习和立体视觉的深度估计研究在未来可能的前景。
1.介绍
从单张或者多张彩色图像中估计深度是一个长期存在的不适定问题,其在很多领域都有应用,比如机器人、自动驾驶、物体识别、场景理解、3D建模和动画、增强现实、工业控制以及医疗诊断。这个问题已经被广泛研究了数十年。在文献中提到的所有方法里面,立体匹配是传统上研究最多的一种,因为它与人类的双目有着紧密联系。
第一代基于立体视觉的深度估计方法通常在精准校准过的相机拍摄的多张图片上,依赖像素匹配。尽管这些方法可以取得不错的效果,但是它们在很多方面都会受到限制。比如,它们不能处理遮挡、特征缺少、或者具有重复图案的复杂纹理区域。有趣的是,作为人类,我们很善于利用先验知识解决此类不适定的逆问题(inverse problem)。比如,我们可以轻松推断物体的大概尺寸、它们的相对位置、甚至它们到我们眼睛的相对距离。我们之所以可以做到这些,是因为所有以前见过的物体和场景让我们能够获得先验知识,并且建立关于三维世界长啥样的思维模型。第二代方法试图将问题转化为学习任务来利用这些先验知识。随着计算机视觉中深度学习技术[1]的出现以及大型数据集的日益普及,已经带来了能够恢复丢失维度(即深度维度)的第三代方法。尽管这些方法最近才出现,但是它们已经在与计算机视觉和图形学相关的各种任务上,展示出了令人兴奋和鼓舞的结果。
在本文中,我们提供了最近使用深度学习并基于立体视觉的深度估计方法的全面、结构化综述。这些方法使用由分布在不同空间位置的彩色相机拍摄的两张或者多张图片。我们收集了2014年1月-2019年12月之间,发表于计算机视觉、计算机图形学和机器学习的前沿会议和期刊中的150多篇论文。我们的目标是帮助读者全面了解这个新兴领域,回顾其在过去几年中获得的巨大发展。
本文的主要贡献如下:
- 据我们所知,本文是第一篇调查了使用深度学习、基于立体视觉的深度估计方法的文章。我们对超过150篇论文进行了全面回顾,这些论文在过去6年中发表于主要的会议和期刊上。
- 我们对所有最新方法进行了全面的分类。我们首先介绍了常用流程(pipelines),然后讨论了每种流程下面的所有方法之间的异同。
- 我们对问题的各个方面进行了全面的回顾和有见地的分析,包括训练数据集、网络结构、以及它们在重建性能、训练策略和泛化能力的效果。
- 对于一些关键方法,我们使用了公开的数据集和自身的图片测试其性能与表现,并对其进行了详细的总结。使用后者(即自身的图片)是为了测试这些方法在全新场景下的性能。
本文余下部分安排如下:第2节提出了问题并制定了分类的方法。第3节概述了可以用于训练和测试基于双目视觉的深度重建算法的数据集。第4节重点介绍了如何使用深度学习在图像之间匹配像素的工作。第5节回顾了立体匹配的端到端的方法,而第6节讨论了如何将这些方法扩展到多视图立体视觉中。第7节重点介绍了训练过程,包括损失函数和监督程度的选择。第8节讨论了关键方法(或者叫主要方法)的性能。最后,第9节讨论了潜在的未来研究方向,第10节总结了本文的主要贡献。
3.数据集
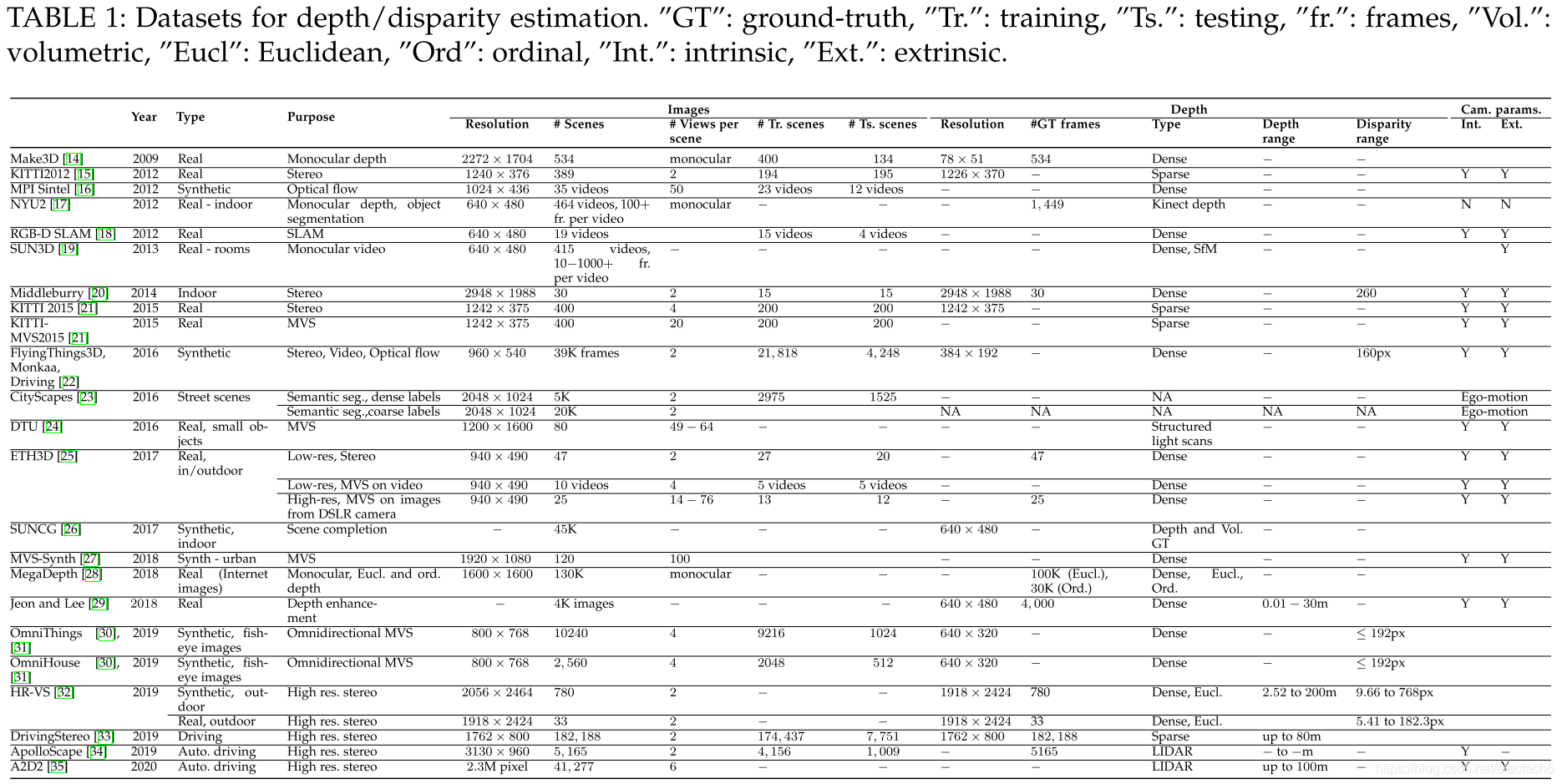
表1. 深度/视差估计的数据集
4.立体视觉匹配深度
表2. 基于深度学习的立体视觉匹配方法的分类与比较
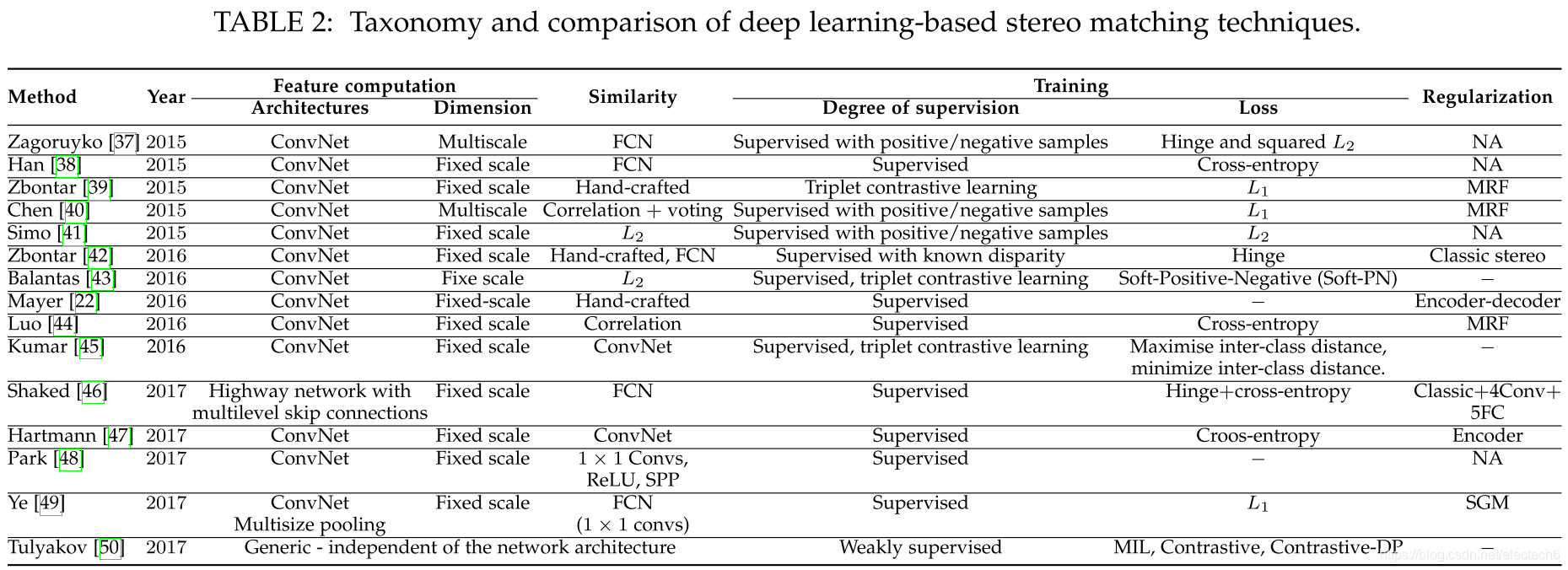
图1. 立体视觉匹配流程的组件
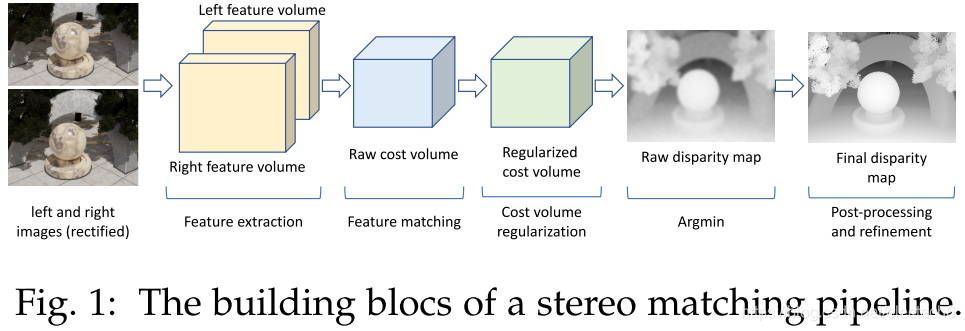
图2. 特征学习框架

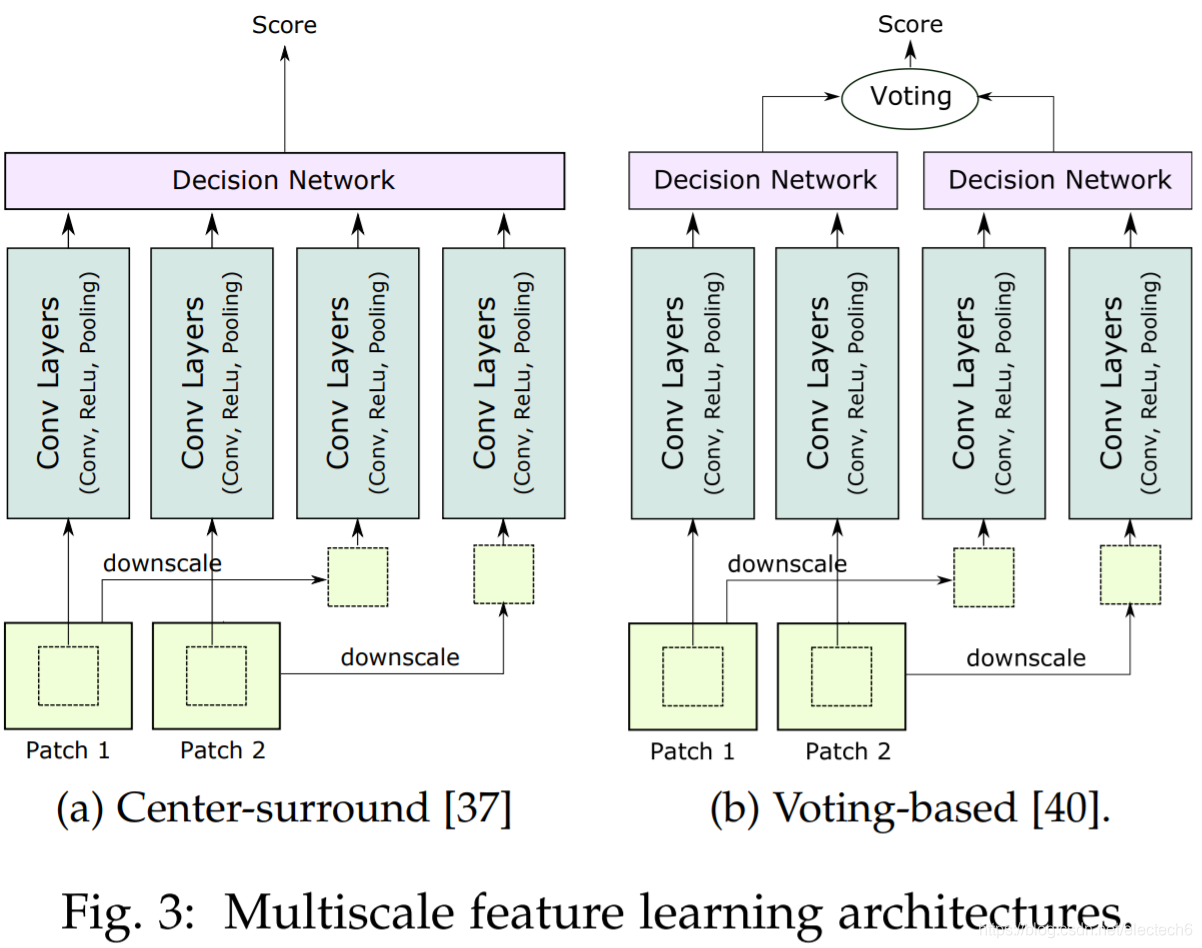
图3. 多尺度特征学习框架
5. 立体视觉的端到端深度
图4. 使用端到端深度学习并基于立体视觉的视差估计的网络结构分类
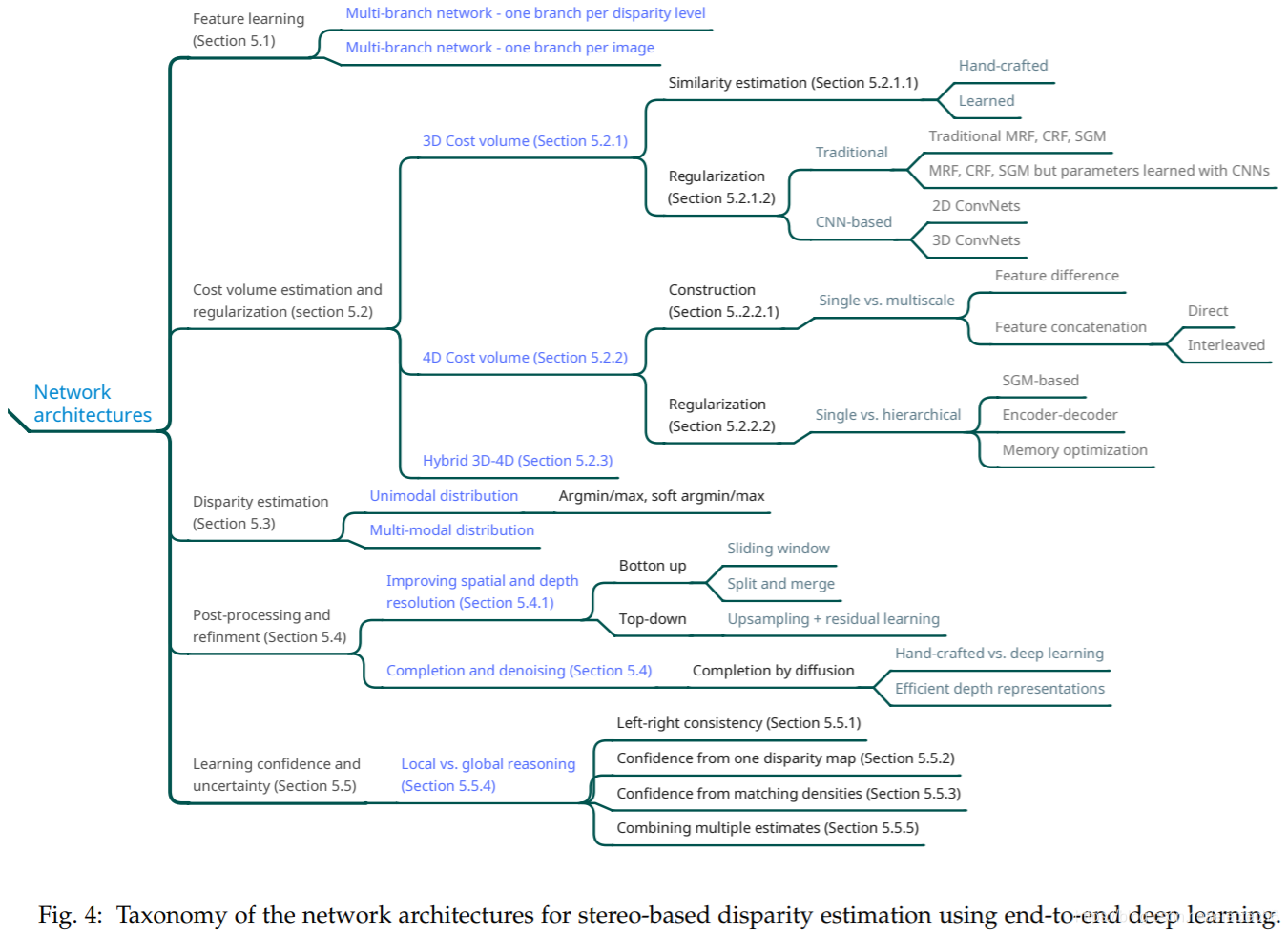
表3. (主要的)28种基于端到端深度学习的视差估计方法的分类与比较
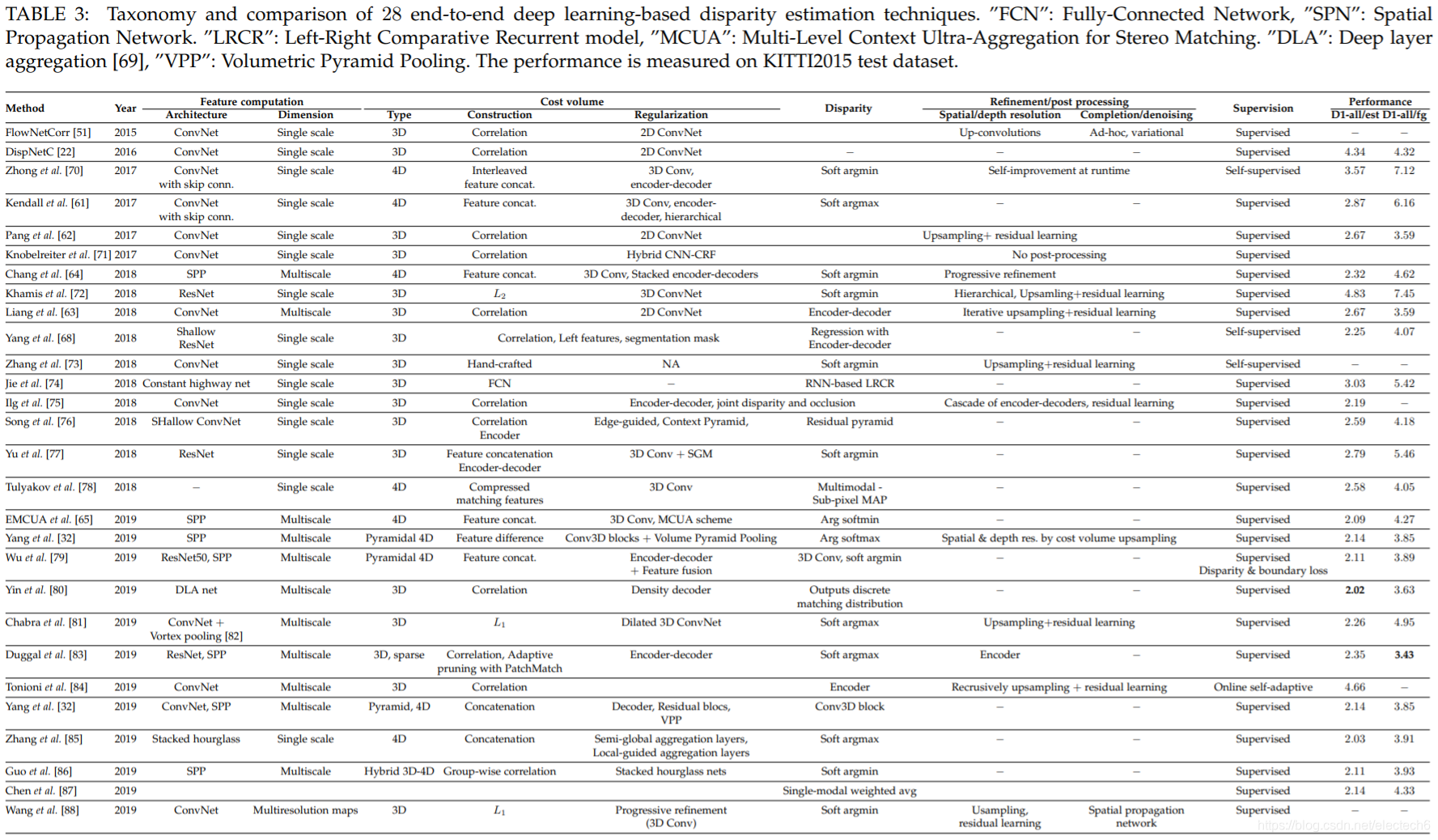
图6. 多视图立体视觉方法的分类
7. 端到端立体视觉训练方法
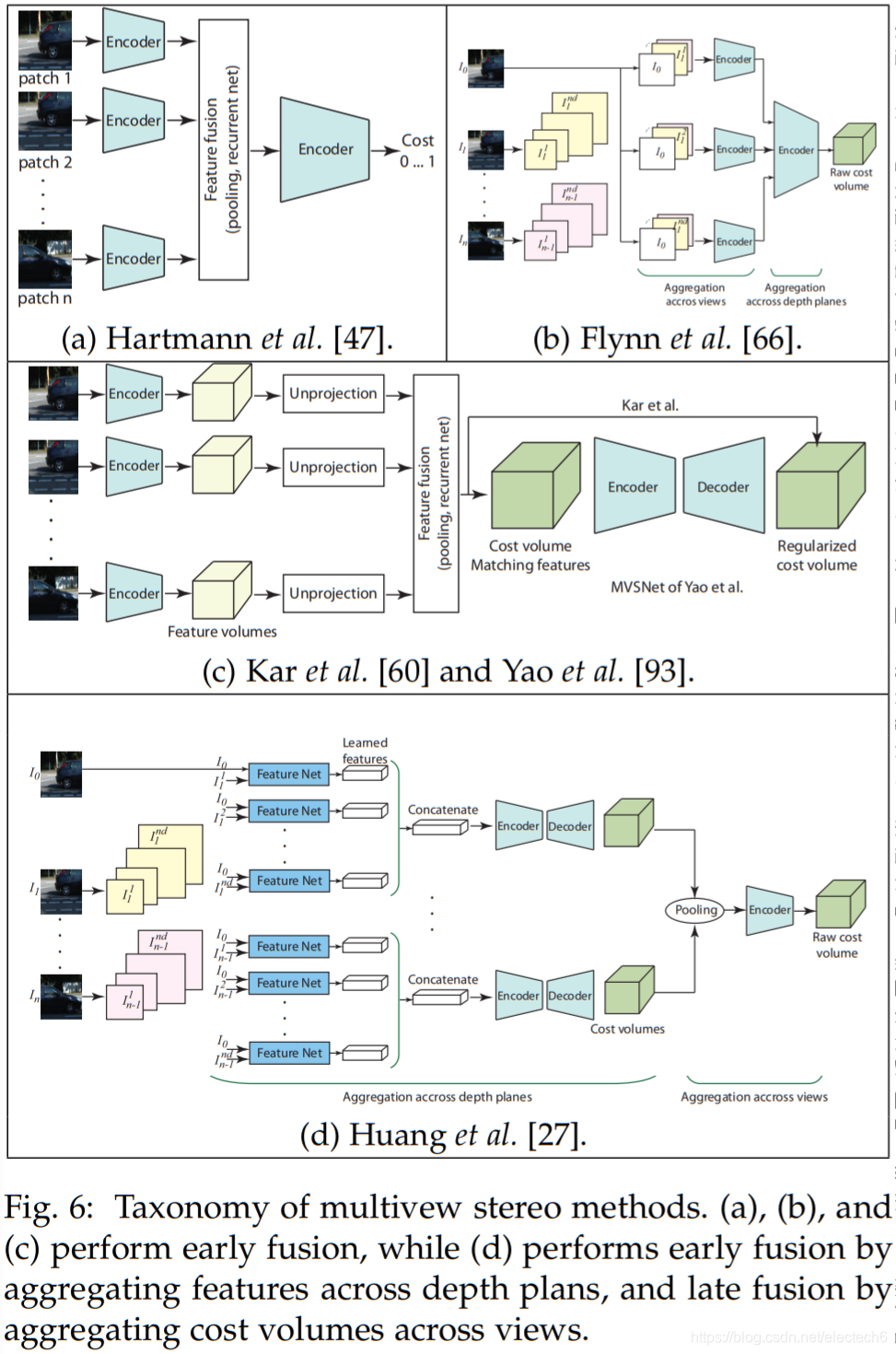
表4. (主要的)13种基于深度学习的MVS方法的分类与比较
8. 讨论与比较
表5. 以640x480大小的图片作为输入,运行时的计算时间与内存消耗
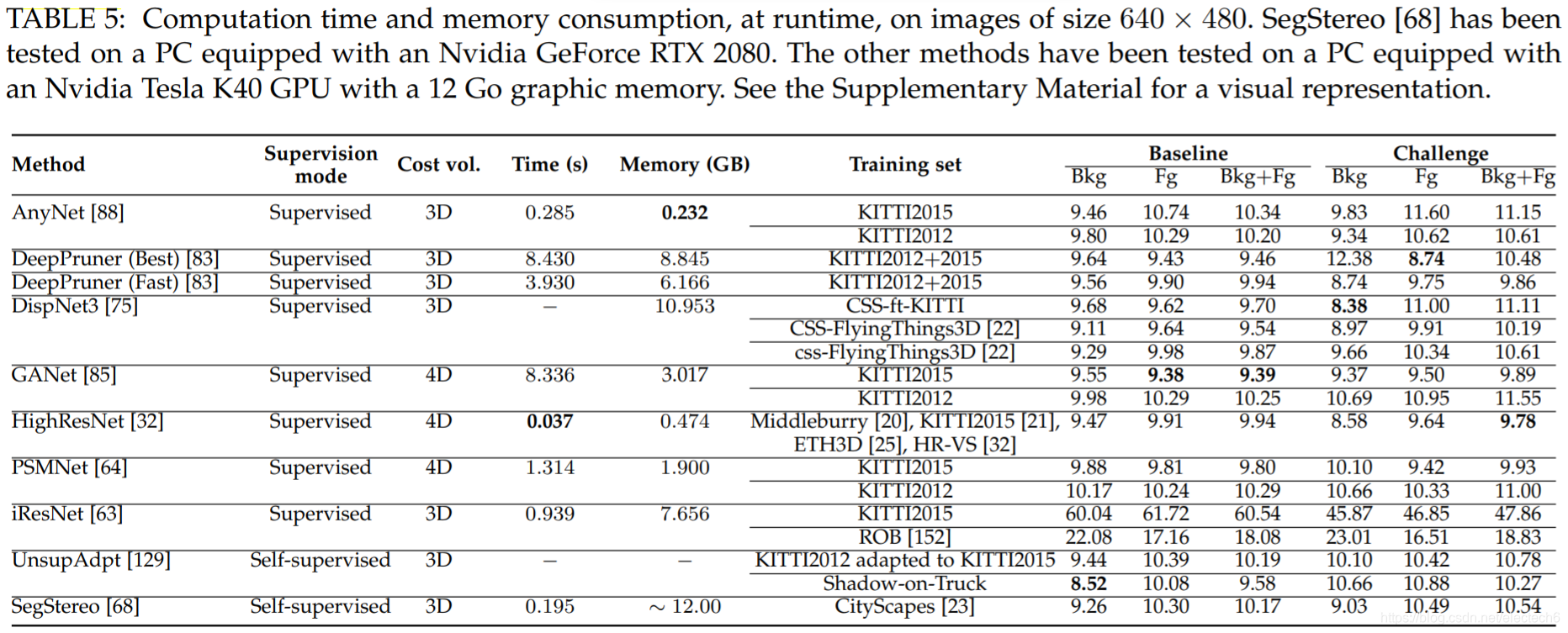
图10. 全部的Bad-n误差
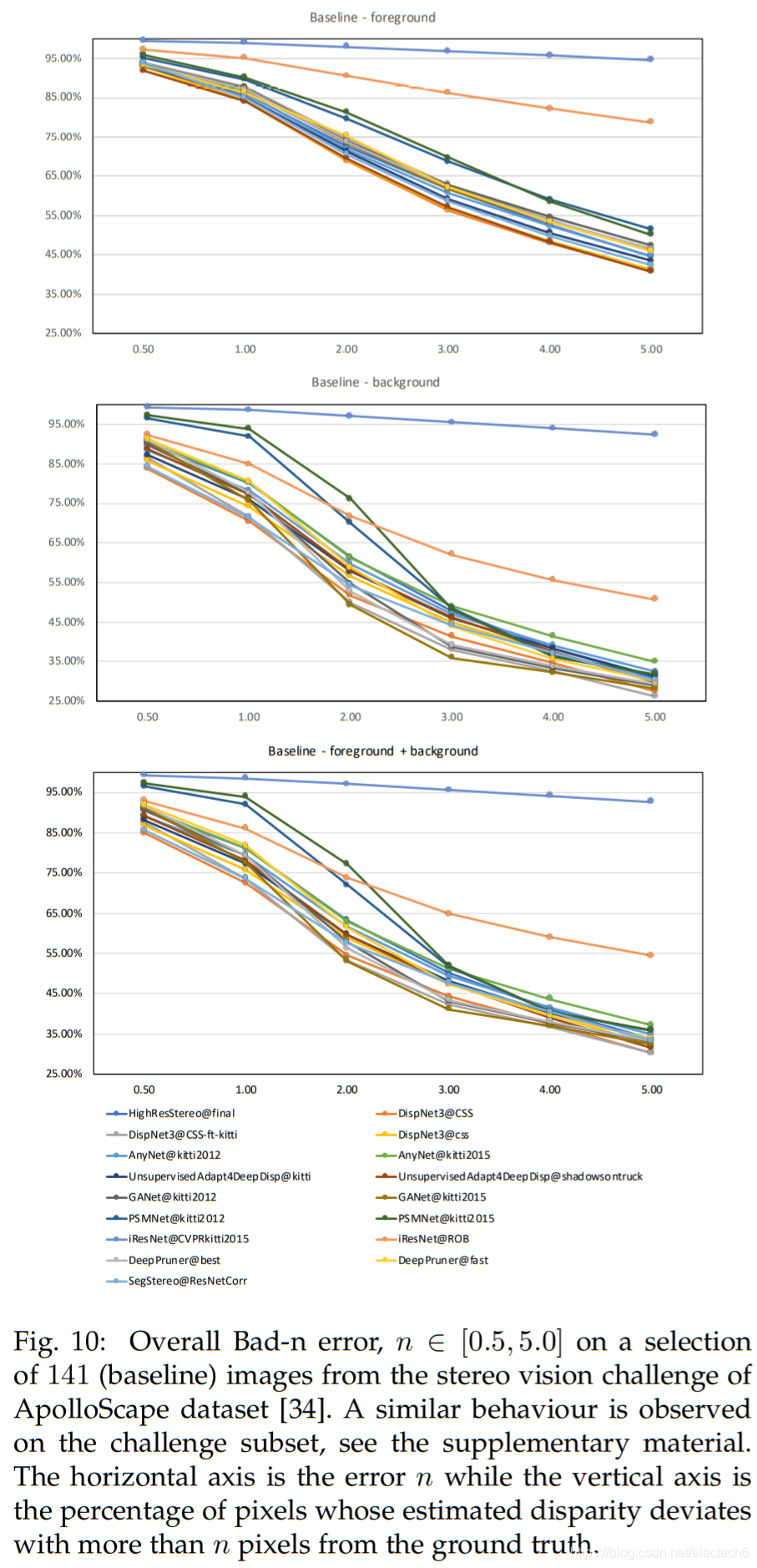
注:Bad-n误差定义为估计的视差与真实值之间相差超过n个像素的像素百分比
未来发展方向
使用深度学习并基于立体视觉的深度估计取得了可喜的成果。但是,该领域仍然处于起步阶段,尚待进一步发展。在本节中,我们介绍了一些现存的问题,并且突出未来研究的方向。
(1) 相机参数。本文研究的绝大多数基于立体视觉的方法都需要矫正过的图片。多视图立体视觉是用平面扫描体(Plane-Sweep Volumes, PSVs)或者反向投影图片/特征(backprojected images/features)。图像矫正和PSVs都要求已知相机参数,这导致在自然环境中的估计变得困难。许多论文试图通过联合优化相机参数和三维场景的几何结构,来解决单目估计深度和三维形状重建(3D Shape Reconstruction)问题[153]。
(2) 光照条件和复杂的材料特性。不良的光照条件和复杂的材料特性仍然是当前大多数方法的挑战。将物体识别、高级场景理解和低级特征学习相结合,可能是解决这些问题的一种有效途径。
(3) 空间和深度的分辨率。当前大多数方法不能处理高分辨率输入的图像,并且通常生成低空间分辨率和深度分辨率的深度图。深度分辨率特别有限,导致这些方法无法重建细小的结构(比如植被和头发),以及距离相机很远的结构。虽然精化模块(refinement module)可以提高估计的深度图的分辨率,但与输入图像的分辨率相比,增加还是太小了。这个问题最近被分层技术解决了,该技术通过限制中间结果的分辨率来根据实际需要得到不同精度的视差[32]。在这些方法中,低分辨率深度图可以实时生成,因此可以用于移动平台上,而高分辨率图则需要更多的计算时间。实时制作高空间和深度分辨率的精确地图仍然是未来研究的挑战。
(4) 实时处理。大多数用于视差估计的深度学习方法使用3D和4D代价体(cost volume),这些代价体是使用2D和3D卷积进行处理和正则化的。就内存需求和处理时间而言,它们是昂贵的。开发轻量级的、能够快速出结果的、端到端深度网络仍然是未来研究的一个具有挑战性的方向。
(5) 视差范围。现有方法对视差范围统一进行离散处理。这会导致很多问题。特别地,尽管重建误差在视差空间中可以很小,但是它在深度空间中可能导致米级别的误差,尤其是在远距离处。缓解此问题的一种方法是通过在对数空间中均匀离散化视差和深度。并且,改变视差范围需要重新训练网络。将深度视为连续变量可能是将来研究中有希望的一种途径。
(6) 训练。深度网络在很大程度上依赖于标有真值的训练图像的可用率。这对于深度/视差重建是非常昂贵且费力的。同样的地,这些方法的性能及其泛化能力可能会受到很大影响,包括将模型过度拟合到特定领域的风险。现有方法通过设计不需要3D标注的损失函数,或者通过使用领域自适应(domain adaptation)和迁移学习(transfer learning)的策略来缓解此问题。但是,前者需要校准过的摄像机。领域自适应技术,尤其是无监督的领域[138],最近吸引了很多的关注,因为使用这些技术,既可以训练易于获得的合成数据,又可以训练真实数据。一旦收集到新图像,它们也将以无监督的方式,在运行时适应不断变化的环境。它们的早期结果非常令人鼓舞,因此希望在将来看到大型数据集的出现,这有点像ImageNet,但它应用于三维重建。
(7) 从数据中自动学习网络结构、及其激活函数和参数。现有的大多数研究都集中在设计新颖的网络体系结构和新颖的训练方法以优化其参数。直到最近,一些论文才开始致力于自动学习最佳架构。早期的尝试,例如文献[149]专注于简单的网络结构 我们希望在未来会看到更多关于自动学习复杂的视差估计的结构及其激活函数的研究,例如,使用神经网络进化理论[154-155](the neuro-evolution theory),这将免除手动网络设计的需求。
结论
对于使用深度学习、基于立体视觉的深度估计技术,本文提供了它最新发展的全面调查。尽管这些技术还处于起步阶段,但是它们都达到了最高水平。自从2014年以来,我们进入了一个新的时代,其中数据驱动和机器学习技术在基于图像的深度重建中起着核心作用。我们已经看到,2014年-2019年之间,在主要的计算机视觉、计算机图形学和机器学习的会议与期刊上发表了超过150篇相关的论文。即使在本文提交的最后阶段,也有越来越多的新论文准备发表,这使得跟踪最新动态很困难,更重要的是,要了解它们的差异和相似之处也很困难,特别是对于该领域的新手。因此,这种及时的综述可以为读者提供指南,以帮助他们浏览这个快速发展的研究领域。
最后,本文没有涵盖几个相关的领域。比如使用深度学习、基于图像的3D目标重建(Han等人最近对此进行了调查[153]),以及基于单目和视频的深度估计(鉴于过去5至6年中,已针对该领域发表了大量论文,因此需要单独的综述)。其他领域则包括光度立体视觉(photometric stereo)和主动双目立体视觉(active stereo)[153-157],它们不在本文讨论范围之内。
本文来自 计算机视觉life公众号 翻译整理。
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
