前言
学习深度学习和计算机视觉,特别是目标检测方向的学习者,一定听说过Faster Rcnn;在目标检测领域,Faster Rcnn表现出了极强的生命力,被大量的学习者学习,研究和工程应用。网上有很多版本的Faster RCNN的源码,但是很多版本代码太过于庞大,对新入门的学习者学习起来很不友好,在网上苦苦寻找了一番后终于找到了一个适合源码学习的Faster Rcnn的pytorch版本代码。
根据该版本的作者讲该代码除去注释只有两千行左右,并且经过小编的一番学习之后,发现该版本的代码真的是非常的精简干练,读起来“朗朗上口”,并且深刻的感觉到作者代码功底之深厚。在此先附上源码的地址(https://github.com/chenyuntc/simple-faster-rcnn-pytorch) ,并对源码作者(陈云)表示由衷的感谢和深深地敬意。
本文章主要的目的是对该版本代码的主要框架进行梳理,希望能够对一些想学习源码的读者有一定的帮助。
本文作者:白俊杰
代码的主要文件
-data文件中主要是文件的与dataset相关的文件
-misc中有下载caffe版本预训练模型的文件,可以不看
-model文件中主要是与构建Faster Rcnn网络模型有关的文件
-utils中主要是一些辅助可视化和验证的文件
-train.py是整个程序的运行文件,下面有一部分会做介绍
-trainer.py文件主要是用于训练,模型的损失函数的计算都在这个文件中
train
先来看一下train.py里的主要内容:
def train(train(**kwargs)): #训练网络的主要内容(位于train.py文件中)
opt._parse(kwargs)
dataset = Dataset(opt) #读取用于训练的图片及进行相关的预处理(在下文的dataset部分做详细介绍)
dataloader = data_.DataLoader(dataset,
batch_size=1,
shuffle=True,
# pin_memory=True,
num_workers=opt.num_workers)
testset = TestDataset(opt) #读取用于测试的图片及进行相关的预处理
test_dataloader = data_.DataLoader(testset,
batch_size=1,
num_workers=opt.test_num_workers,
shuffle=False,
pin_memory=True
)
faster_rcnn = FasterRCNNVGG16() #网络结构,包含主要Extractor,RPN和RoIHead三部分结构。
trainer = FasterRCNNTrainer(faster_rcnn).cuda() #主要包含模型的训练过程的
for epoch in range(opt.epoch):#开始迭代训练
trainer.reset_meters()
for ii, (img, bbox_, label_, scale) in tqdm(enumerate(dataloader)):
scale = at.scalar(scale)
img, bbox, label = img.cuda().float(), bbox_.cuda(), label_.cuda()
trainer.train_step(img, bbox, label, scale) #执行训练
从train.py中的主要函数可以看出,主要的步骤涉及训练数据和测试数据的预处理,网络模型的构建(Faster RCNN),然后就是迭代训练,这也是通用的神经网络搭建和训练的过程。在Faster Rcnn网络模型中主要包含Extractor、RPN和RoIhead三部分。网络中Extractor主要是利用CNN进行特征提取,网络采用的VGG16;RPN是候选区网络,为RoIHead模块提供可能存在目标的候选区域(rois);RoIHead主要负责rois的分类和微调。整体的框架图如下图所示:
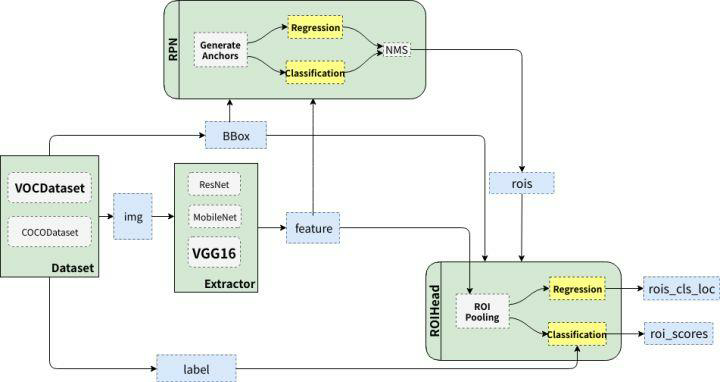
图片来源于陈云的知乎
Dataset
在本版本的代码中读取的数据格式为VOC,Dataset和TestDataset类分别负责训练数据和测试数据的读取及预处理。在预处理部分主要的操作就是resize图像的大小、像素值的处理以及图像的随机翻转。主要的内容如下:
class Dataset: #训练数据预处理(位于data/dataset.py文件中)
def __init__(self, opt):
self.opt = opt
self.db = VOCBboxDataset(opt.voc_data_dir) #读取VOC格式的数据,包括图像和label(.xml)
self.tsf = Transform(opt.min_size, opt.max_size) #resize图像的大小,在代码中默认长边小于等于1000,
#短边小于等于600,两个边至少有一个等于其值,然后对图像像素值减去均值,使得像素均值为零,并对图像进行随机翻转(具体细节代码见**)
def __getitem__(self, idx):
ori_img, bbox, label, difficult = self.db.get_example(idx)
img, bbox, label, scale = self.tsf((ori_img, bbox, label))
return img.copy(), bbox.copy(), label.copy(), scale
def __len__(self):
return len(self.db)
class TestDataset:
pass #与class Dataset相似,没有图像翻转过程(具体内容见data/dataset.py文件中TestDataset)
FasterRCNNVGG16
下面主要介绍Extractor、RPN和RoIHead三部分结构
Extractor
extractor, classifier = decom_vgg16() #该行代码位于model/faster_rcnn_vgg16.py中的FasterRCNNVGG16类中
Extractor部分主要使用的VGG16的网络结构,同时使用预训练好的模型提取图片的特征。论文中主要使用的是Caffe的预训练模型,根据代码的作者讲该版本的预训练模型效果比较好。
为了节约显存,作者将前四层卷积层的学习率设置为0,Conv5_3的输入作为图片的特征输入到RPN网络中。根据网络结构,Conv5_3部分的感受野为16,也就是相较于输入的图片大小,feature map的尺寸为(C,H/16,W/16).该部分网络结构图如下所示:
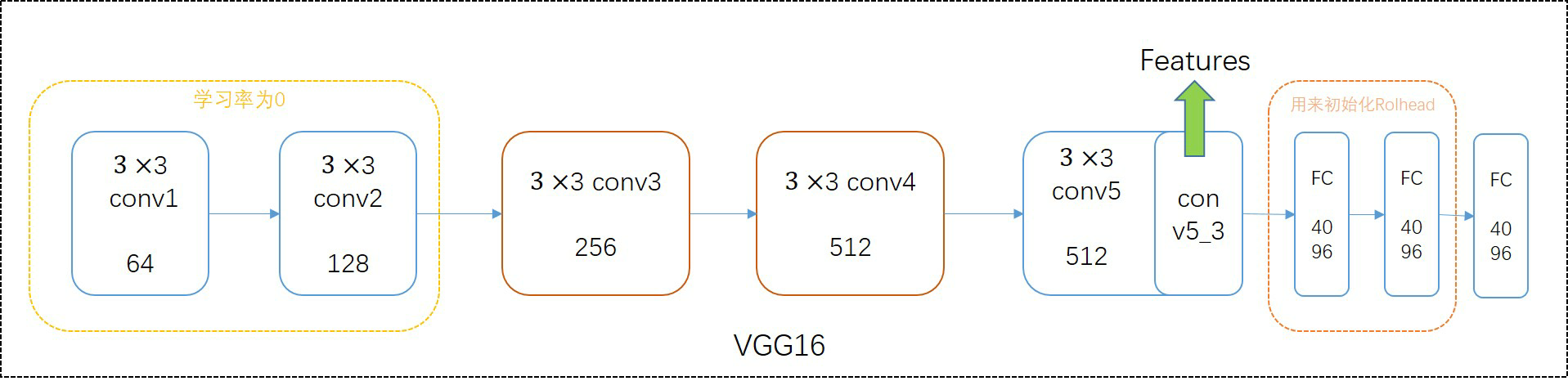
具体的decom_vgg16()代码如下:
def decom_vgg16(): #该段落代码位于model/faster_rcnn_vgg16.py中
# the 30th layer of features is relu of conv5_3
if opt.caffe_pretrain: #使用caffe版本的预训练模型
model = vgg16(pretrained=False) #使用pytorch中自带的vgg16模型
if not opt.load_path:
model.load_state_dict(t.load(opt.caffe_pretrain_path)) #加载caffe版本的预训练模型,需要自己下载。
else:
model = vgg16(not opt.load_path)
features = list(model.features)[:30] #提取特征的网络
classifier = model.classifier #classifier在RoIhead部分使用
classifier = list(classifier)
del classifier[6]
if not opt.use_drop: #是否使用dropout
del classifier[5]
del classifier[2]
classifier = nn.Sequential(*classifier) #分类器网络
# 冻结前四层卷积层
for layer in features[:10]:
for p in layer.parameters():
p.requires_grad = False
return nn.Sequential(*features), classifier
RPN
Faster RCNN中最突出的贡献就是提出了Region Proposal Network(RPN),将候选区域提取的时间开销几乎降为0。该模块的主要作用提供可能存在目标的候选区域rois。模块结构图如下所示:
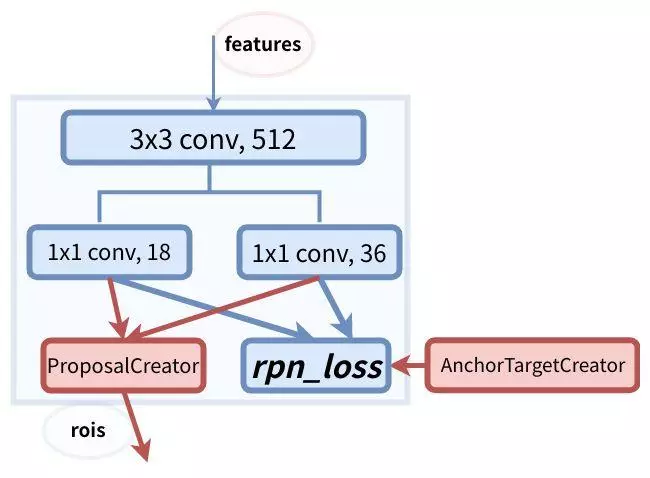
图片来源于陈云的知乎
class RegionProposalNetwork(nn.Module): #代码中实现RPN的类(代码位于model/region_proposal_network.py中)
def __init__():#省略,具体看先关文件
# ......
def forward(self, x, img_size, scale=1.):
#x: Extractor模块处理后的特征图,形状为(N, C, H, W)
#img_size : 输入图像的大小
#scale : 网络下采样的尺寸大小
n, _, hh, ww = x.shape
anchor = _enumerate_shifted_anchor( #枚举所有anchor
np.array(self.anchor_base),
self.feat_stride, hh, ww)
n_anchor = anchor.shape[0] // (hh * ww) #一个anchor产生的锚点框
h = F.relu(self.conv1(x)) #激活函数
rpn_locs = self.loc(h) #卷积产生每个锚点框的位置
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4)
rpn_scores = self.score(h) #卷积产生每个锚点框的评分
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous()
rpn_softmax_scores = F.softmax(rpn_scores.view(n, hh, ww, n_anchor, 2), dim=4) #softmax操作
rpn_fg_scores = rpn_softmax_scores[:, :, :, :, 1].contiguous()
rpn_fg_scores = rpn_fg_scores.view(n, -1)
rpn_scores = rpn_scores.view(n, -1, 2)
rois = list()
roi_indices = list()
for i in range(n):
roi = self.proposal_layer( #根据每个锚点的评分选出对应的候选区域
rpn_locs[i].cpu().data.numpy(),
rpn_fg_scores[i].cpu().data.numpy(),
anchor, img_size,
scale=scale)
batch_index = i * np.ones((len(roi),), dtype=np.int32)
rois.append(roi)
roi_indices.append(batch_index)
rois = np.concatenate(rois, axis=0)
roi_indices = np.concatenate(roi_indices, axis=0)
return rpn_locs, rpn_scores, rois, roi_indices, anchor
RoIHead
RoIhead主要任务是对RPN网络选出的候选框进行分类和回归,在RoIhead中作者提出了RolPooling方法将不同尺度的候选区域全部pooling到一个尺度上。模块结构图如下所示:
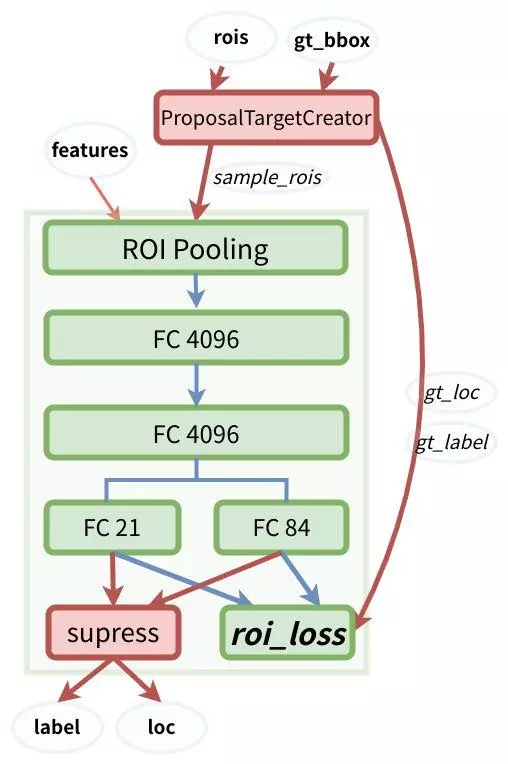
图片来源于陈云的知乎
class VGG16RoIHead(nn.Module): #代码位于model/faster_rcnn_vgg16.py中
def __init__(self, n_class, roi_size, spatial_scale,
classifier):
# n_class includes the background
super(VGG16RoIHead, self).__init__()
self.classifier = classifier #vgg16的两层全连接,可见文中的Extractor部分VGG16的结构图
self.cls_loc = nn.Linear(4096, n_class * 4) #输出目标区域位置
self.score = nn.Linear(4096, n_class) #输出预测类别
normal_init(self.cls_loc, 0, 0.001) #正则化
normal_init(self.score, 0, 0.01)
self.n_class = n_class #类别
self.roi_size = roi_size #roi大小
self.spatial_scale = spatial_scale #空间尺度
self.roi = RoIPooling2D(self.roi_size, self.roi_size, self.spatial_scale)
def forward(self, x, rois, roi_indices):
#......省略
pool = self.roi(x, indices_and_rois) #RoI池化部分
pool = pool.view(pool.size(0), -1) #降维
fc7 = self.classifier(pool) #VGG16的两层全连接
roi_cls_locs = self.cls_loc(fc7) #预测出位置
roi_scores = self.score(fc7) #分类
return roi_cls_locs, roi_scores
运行代码
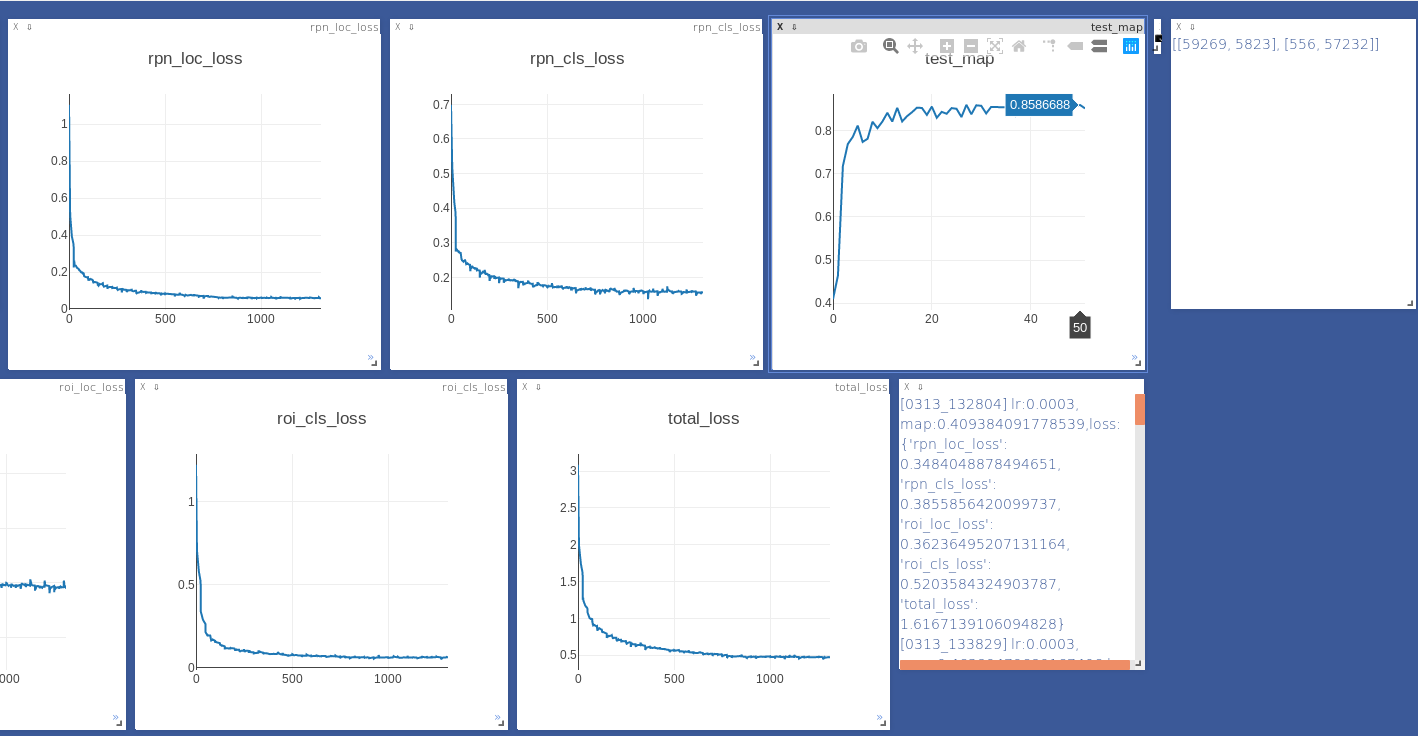
整体来说该版本的代码环境相当简单,配置起来相当容易,没有什么坑,认真阅读作者的readme就好。在utils文件中有一个config.py文件,在里边可以修改文件读取的路径,学习率等参数,自己运行时根据自己的情况进行修改即可。小编运行自己的数据(非VOC2007)结果如下图:
总结
本篇文章主要的目的是推荐一个适合源码学习的Faster rcnn版本给大家,并对代码框架做了初步的介绍,希望对大家的源码学习有一定的帮助,由于整个算法实现的代码较为复杂,且细节比较多,很难通过一篇文章进行详细的说明,如果大家对本版本的代码感兴趣,可以自己阅读源码学习。在学习源码的时候我个人是有很多感想的,作为一个小白,通过源码的学习真的学习到了很多,之前论文阅读过几遍,别的版本的代码也拿来训练过数据,但是读了这个的源码,又如发现了新大陆,很多算法的细节和精髓才算有了深刻的理解,真的是纸上得来终觉浅,绝知此事要coding。除了算法本身,在一些代码的实现上也有很多的学习,真的感受到代码作者的功力深厚,再次对作者表示深深地敬意.最后留个问题,在阅读源码的时候,发现作者使用了visdom进行可视化,如运行的截图,小编还知道pytorch中一个可视化工具tensorboardX,但都不是很熟悉,还请知情人士在下方留言,详细的讲解一下两种可视化工具的优劣。由于小编是一个刚入门(入坑)的学习者,文章中的不当之处还请大家谅解和提出,很希望能与大家一起讨论学习。
最后再次放上源码链接:https://github.com/chenyuntc/simple-faster-rcnn-pytorch
参考:
https://zhuanlan.zhihu.com/p/32404424
https://www.cnblogs.com/kerwins-AC/p/9734381.html
推荐阅读
实战 | 相机标定
实战 | 图像矫正技术
实战 | Unity下ARKit与OpenCV的结晶
实战 | 基于SegNet和U-Net的遥感图像语义分割
实战 | 文字定位与切割
我用MATLAB撸了一个2D LiDAR SLAM
原来CNN是这样提取图像特征的。。。
最佳机器/深度学习课程 Top 5 ,吴恩达占了俩
机器学习必学十大算法
语义分割如何「拉关系」?
YOLO简史
这可能是「多模态机器学习」最通俗易懂的介绍
算力限制场景下的目标检测实战浅谈
开源 | 用深度学习让你的照片变得美丽
面试时让你手推公式不在害怕 | 线性回归
面试时让你手推公式不在害怕 | 梯度下降
深度学习在计算机视觉各项任务中的应用
干货 | 深入理解深度学习中的激活函数