一、直接采样
直接采样的思想是,通过对均匀分布采样,实现对任意分布的采样。因为均匀分布采样好猜,我们想要的分布采样不好采,那就采取一定的策略通过简单采取求复杂采样。
假设y服从某项分布p(y),其累积分布函数CDF为h(y),有样本z~Uniform(0,1),我们令 z = h(y),即 y = h(z)^(-1),结果y即为对分布p(y)的采样。

直接采样的核心思想在与CDF以及逆变换的应用。在原分布p(y)中,如果某个区域[a, b]的分布较多,然后对应在CDF曲线中,[h(a), h(b)]的曲线斜率便较大。那么,经过逆变换之后,对y轴(z)进行均匀分布采样时,分布多的部分(占据y轴部分多)对应抽样得到的概率便更大,
局限性
实际中,所有采样的分布都较为复杂,CDF的求解和反函数的求解都不太可行。
二、拒绝采样
拒绝采样是由一个易于采样的分布出发,为一个难以直接采样的分布产生采样样本的通用算法。既然 p(x) 太复杂在程序中没法直接采样,那么便一个可抽样的分布 q(x) 比如高斯分布,然后按照一定的方法拒绝某些样本,达到接近 p(x) 分布的目的。

计算步骤
设定一个方便抽样的函数 q(x),以及一个常量 k,使得 p(x) 总在 k*q(x) 的下方。(参考上图)
- x 轴方向:从 q(x) 分布抽样得到 a;
- y 轴方向:从均匀分布(0, k*q(a)) 中抽样得到 u;
- 如果刚好落到灰色区域: u > p(a), 拒绝, 否则接受这次抽样;
- 重复以上过程。
计算步骤(BN)
- 根据网络指定的先验概率分布生成采样样本;
- 拒绝所有与证据不匹配的样本;
- 在剩余样本中对事件X=x的出现频繁程度计数从而得到估计概率、
局限性
- 拒绝了太多的样本!随着证据变量个数的增多,与证据e相一致的样本在所有样本中所占的比例呈指数级下降,所以对于复杂问题这种方法是完全不可用的。
- 难以找到合适的k*q(a),接受概率可能会很低。
三、重要性采样(似然加权)
重要性采样主要是用于求一个复杂分布p(x)的均值,最后并没有得到样本。
重要性采样的思想是借助一个易于采样的简单分布q(x),对这个简单分布q(x)所得到的样本全部接受。但是以此得到的样本肯定不满足分布p(x),因此需要对每一个样本附加相应的重要性权重。在重要性采样中,以p(x0)/q(x0)的值作为每个样本的权重。这样,当样本和分布p(x)相近时,对应的权重大;与分布p(x)相差过多时,对应的权重小。这个方法采样得到的是带有重要性权重的服从q(z)分布的样本,这个权重乘以样本之后的结果其实就是服从p(z)分布的。

通过上述公式,我们可以知道重要性采样可以用于近似复杂分布的均值。
四、吉布斯采样
假设有一个例子:E:吃饭、学习、打球;时间T:上午、下午、晚上;天气W:晴朗、刮风、下雨。样本(E,T,W)满足一定的概率分布。现要对其进行采样,如:打球+下午+晴朗。
问题是我们不知道p(E,T,W),或者说,不知道三件事的联合分布。当然,如果知道的话,就没有必要用吉布斯采样了。但是,我们知道三件事的条件分布。也就是说,p(E|T,W), p(T|E,W), p(W|E,T)。现在要做的就是通过这三个已知的条件分布,再用Gibbs sampling的方法,得到联合分布。
具体方法:首先随便初始化一个组合,i.e. 学习+晚上+刮风,然后依条件概率改变其中的一个变量。具体说,假设我们知道晚上+刮风,我们给E生成一个变量,比如,学习→吃饭。我们再依条件概率改下一个变量,根据学习+刮风,把晚上变成上午。类似地,把刮风变成刮风(当然可以变成相同的变量)。这样学习+晚上+刮风→吃饭+上午+刮风。同样的方法,得到一个序列,每个单元包含三个变量,也就是一个马尔可夫链。然后跳过初始的一定数量的单元(比如100个),然后隔一定的数量取一个单元(比如隔20个取1个)。这样sample到的单元,是逼近联合分布的。

五、蓄水池采样
蓄水池抽样(Reservoir Sampling ),即能够在o(n)时间内对n个数据进行等概率随机抽取,例如:从1000个数据中等概率随机抽取出100个。另外,如果数据集合的量特别大或者还在增长(相当于未知数据集合总量),该算法依然可以等概率抽样。
算法步骤:
- 先选取数据流中的前k个元素,保存在集合A中;
- 从第j(k + 1 <= j <= n)个元素开始,每次先以概率p = k/j选择是否让第j个元素留下。若j被选中,则从A中随机选择一个元素并用该元素j替换它;否则直接淘汰该元素;
- 重复步骤2直到结束,最后集合A中剩下的就是保证随机抽取的k个元素。
六、MCMC算法
马氏链收敛定理
马氏链定理:如果一个非周期马氏链具有转移概率矩阵P,且它的任何两个状态是连通的,那么(lim_{p oinfty}P_{ij}^n)存在且与i无关,记(lim_{p oinfty}P_{ij}^n = pi(j)),我们有:

其中(pi = [pi(1), pi(2), ... , pi(j), ...], sum_{i=0}^{infty}pi_i = 1, pi)称为马氏链的平稳分布。
所有的 MCMC(Markov Chain Monte Carlo) 方法都是以这个定理作为理论基础的。
说明:
- 该定理中马氏链的状态不要求有限,可以是有无穷多个的;
- 定理中的“非周期“这个概念不解释,因为我们遇到的绝大多数马氏链都是非周期的;

细致平稳条件


针对一个新的分布,如何构造对应的转移矩阵?
对于一个分布(pi(x)),根据细致平稳条件,如果构造的转移矩阵P满足(pi(i)P_{ij} = pi(j)P_{ji}),那么(pi(x))即为该马氏链的平稳分布,因此可以根据这个条件去构造转移矩阵。
通常情况下,初始的转移矩阵(P)一般不满足细致平稳条件,因此我们通过引入接受率构造出新的转移矩阵(P'),使其和(pi(x))满足细致平稳条件。由此,我们便可以用任何转移概率矩阵(均匀分布、高斯分布)作为状态间的转移概率。
如果我们假设状态之间的转移概率是相同的,那么在算法实现时,接收率可以简单得用(pi(j)/pi(i))表示。
Metropolis-Hastings采样
对于给定的概率分布p(x),我们希望能有便捷的方式生成它对应的样本。由于马氏链能收敛到平稳分布, 于是一个很的漂亮想法是:如果我们能构造一个转移矩阵为P的马氏链,使得该马氏链的平稳分布恰好是p(x), 那么我们从任何一个初始状态x0出发沿着马氏链转移, 得到一个转移序列 x0,x1,x2,⋯xn,xn+1⋯,, 如果马氏链在第n步已经收敛了,于是我们就得到了 π(x) 的样本xn,xn+1⋯。

在马尔科夫状态链中,每一个状态代表一个样本(x_n),即所有变量的赋值情况。
通过分析MCMC源码,可以知道:假设状态间的转移概率相同,那么下一个样本的采样会依赖于上一个样本。假设上一个样本所对应的原始分布概率(pi(x))很小,那么下一个样本的接受率很大概率为1;反之如果上一个样本的原始分布概率(pi(x))很大,那么下一个样本会有挺大概率被拒绝。这样的机制保证了生成的样本服从分布(pi(x))。
从上述分析可以看出,假如初始状态的样本对应的分布概率很小,那么在算法刚开始运行时所产生的样本(即使是分布概率很小的样本)很大可能都会被接收,从而使得算法刚开始运行时采样的样本不满足原始分布(pi(x))。只要算法采样到分布概率大的样本(此时即为收敛!),那么之后所采样得到的样本就会基本服从原始分布。当然,从初始状态遍历到分布概率大的状态时需要运行一段时间,这段过程即为收敛的过程。MCMC算法在收敛之后,保证了在分布概率(pi(x))大的地方产生更多的样本,在分布概率(pi(x))小的地方产生较少的样本。
一个马尔可夫链需要经过多次的状态转移过程采用达到一个稳定状态,这时候采样才比较接近真实的分布。此过程称为burn in。一般可通过丢弃前面的N个采样结果来达到burn in。
疑问
-
MCMC的收敛是什么意思?这个过程中是什么参数会更新导致收敛?如何确定何时收敛?
收敛过程没有参数会更新,收敛的思想类似于大数定理。应用MCMC算法采样时,初始的样本量少,服从的分布可能和复杂分布(pi(x))相差挺远,但随着状态转移数的增加(转移矩阵P的应用),根据上述定理的证明,最终的样本分布会逐渐服从复杂分布(pi(x))。
-
(pi)是每个状态所对应的概率分布吗?如果是的话,初始选定一个状态后,这个(pi)如何设定?或则在MCMC证明过程中,初始(pi)的概率分布如何设置?
在MCMC的证明过程中,(pi)是每个状态所对应的概率分布。证明中所给定的初始(pi)应该只是为了证明无论初始样本符合什么分布,在经过一定数量的转移之后,得到的样本会服从复杂分布(pi (x)),在实际代码实现中,不用对这个(pi)进行设定。
七、代码
import numpy as np
import random
import matplotlib.pyplot as plt
import pandas as pdf
Rejection Sampling
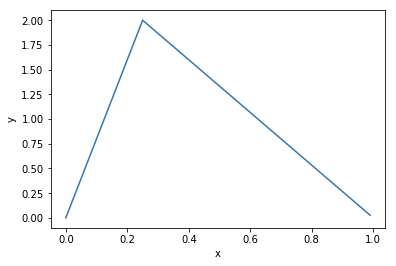
def f(x):
if 0 <= x and x <= 0.25:
y = 8 * x
elif 0.25 < x and x <= 1:
y = (1 - x) * 8/3
else:
y = 0
return y
def g(x):
if 0 <= x and x <= 1:
y = 1
else:
y = 0
return y
def plot(fun):
X = np.arange(0, 1.0, 0.01)
Y = []
for x in X:
Y.append(fun(x))
plt.plot(X, Y)
plt.xlabel("x")
plt.ylabel("y")
plt.show()
plot(f)
plot(g)

def rejection_sampling(N=10000):
M = 3
cnt = 0
samples = {}
while cnt < N:
x = random.random()
acc_rate = f(x) / (M * g(x))
u = random.random()
if acc_rate >= u:
if samples.get(x) == None:
samples[x] = 1
else:
samples[x] = samples[x] + 1
cnt = cnt + 1
return samples
s = rejection_sampling(100000)
X = []
Y = []
for k, v in s.items():
X.append(k)
Y.append(v)
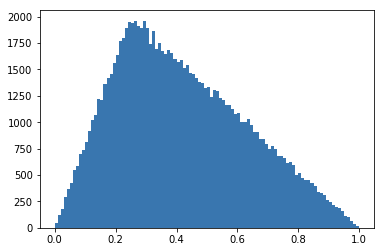
plt.hist(X, bins=100, edgecolor='None')
MCMC Sampling
Metropolis-Hastings Algorithm
PI = 3.1415926
def get_p(x):
# 模拟pi函数
return 1/(2*PI)*np.exp(- x[0]**2 - x[1]**2)
def get_tilde_p(x):
# 模拟不知道怎么计算Z的PI,20这个值对于外部采样算法来说是未知的,对外只暴露这个函数结果
return get_p(x)
def domain_random(): #计算定义域一个随机值
return np.random.random()*3.8-1.9
def metropolis(x):
new_x = (domain_random(),domain_random()) #新状态
#计算接收概率
acc = min(1,get_tilde_p((new_x[0],new_x[1]))/get_tilde_p((x[0],x[1])))
#使用一个随机数判断是否接受
u = np.random.random()
if u<acc:
return new_x
return x
def testMetropolis(counts = 100,drawPath = False):
plt.figure()
#主要逻辑
x = (domain_random(),domain_random()) #x0
xs = [x] #采样状态序列
for i in range(counts):
xs.append(x)
x = metropolis(x) #采样并判断是否接受
#在各个状态之间绘制跳转的线条帮助可视化
X1 = [x[0] for x in xs]
X2 = [x[1] for x in xs]
if drawPath:
plt.plot(X1, X2, 'k-',linewidth=0.5)
##绘制采样的点
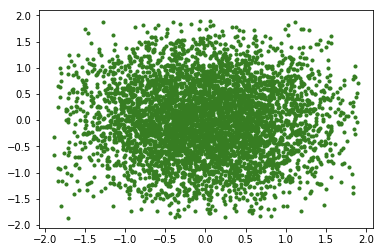
plt.scatter(X1, X2, c = 'g',marker='.')
plt.show()
testMetropolis(5000)
def metropolis(x):
new_x = domain_random()
#计算接收概率
acc = min(1,f(new_x)/f(x))
#使用一个随机数判断是否接受
u = np.random.random()
if u<acc:
return new_x
return x
def testMetropolis(counts = 100,drawPath = False):
plt.figure()
#主要逻辑
x = domain_random()
xs = [x] #采样状态序列
for i in range(counts):
xs.append(x)
x = metropolis(x) #采样并判断是否接受
#在各个状态之间绘制跳转的线条帮助可视化
plt.hist(xs, bins=100, edgecolor='None')
# plt.plot(xs)
plt.show()
testMetropolis(100000)
Gibbs Sampling
def partialSampler(x,dim):
xes = []
for t in range(10): #随机选择10个点
xes.append(domain_random())
tilde_ps = []
for t in range(10): #计算这10个点的未归一化的概率密度值
tmpx = x[:]
tmpx[dim] = xes[t]
tilde_ps.append(get_tilde_p(tmpx))
#在这10个点上进行归一化操作,然后按照概率进行选择。
norm_tilde_ps = np.asarray(tilde_ps)/sum(tilde_ps)
u = np.random.random()
sums = 0.0
for t in range(10):
sums += norm_tilde_ps[t]
if sums>=u:
return xes[t]
def gibbs(x):
rst = np.asarray(x)[:]
path = [(x[0],x[1])]
for dim in range(2): #维度轮询,这里加入随机也是可以的。
new_value = partialSampler(rst,dim)
rst[dim] = new_value
path.append([rst[0],rst[1]])
#这里最终只画出一轮轮询之后的点,但会把路径都画出来
return rst,path
def testGibbs(counts = 100,drawPath = False):
plt.figure()
x = (domain_random(),domain_random())
xs = [x]
paths = [x]
for i in range(counts):
xs.append([x[0],x[1]])
x,path = gibbs(x)
paths.extend(path) #存储路径
p1 = [x[0] for x in paths]
p2 = [x[1] for x in paths]
xs1 = [x[0] for x in xs]
xs2 = [x[1] for x in xs]
if drawPath:
plt.plot(p1, p2, 'k-',linewidth=0.5)
##绘制采样的点
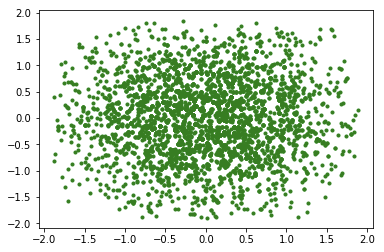
plt.scatter(xs1, xs2, c = 'g',marker='.')
plt.show()
testGibbs(5000)