一、问题分析
1. 传统神经网络在处理序列输入时存在的问题
- 在不同的示例中,输入和输出可能具有不同的维度。
- 无法在不同的文本位置共享所学到的特征信息。
2. 循环神经网络存在的问题
- RNN使用先前的信息以及现在的输入来得到输出,但是输出不仅仅只跟前面的信息有关,可能还会和后面的信息有关。因此没有利用到后面的信息,可能会导致预测出错。
- 因为梯度消失或梯度爆炸的原因,RNNs的神经网络无法很深,因此最开始的单词很难对句子后面的单词产生影响,例如英语中名词的单复数对was和were的影响。
- 梯度爆炸也是RNNS的一个问题,但是梯度爆炸更容易发现,当我们看到参数编程NAN时,便知道参数溢出了,此时可以采用梯度缩减等方法,将梯度进行缩放,控制在一定的量级之类,从而很好得解决梯度爆炸的问题。
二、RNN结构
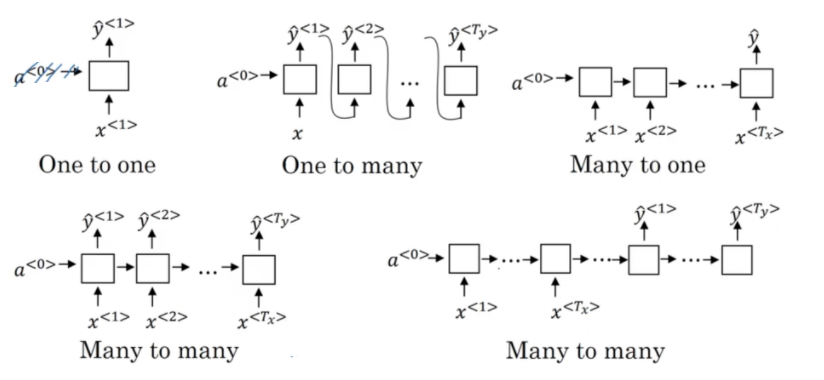
1. one-to-one
2. one-to-many
- 音乐生成
3. many-to-one
- 分类问题,例如电影分类
4. many-to-many
- 语言翻译(输入和输出具有不同的维度)
- 句子中的人名识别(输入和输出具有相同的维度)
3.Deep RNNs
深度循环神经网络的结构便是将序列模型增加几层,但是不同于先前几百层的神经网络结构,Deep RNNs的网络层次一般很少超过三层。由于时间维度的存在,即使层数很少然是网络的规模也会变得很大。
4. 双向神经网络
在RNN中,某个时刻的输出可能不仅与先前的信息有关,还可能与之后的信息有关。因此就需要利用到双向的信息,得到了双向身形网络。
例:在一个人名辨别的RNN中,有两个输入分别为:
- He said, "Teddy bears are on sale!"
- He said, "Teddy roosevelt was a great President!"
仅仅通过“He said Teddy”这三个词是无法判断出Teddy是否是人名,还需要利用到之后的信息。
三、LSTM
1. 公式

2. 遗忘门
在LSTM的忘记门里,如果没有加上偏置量,那么很可能导致一开始的梯度就消失。而使用了偏置,可以确保网络开始训练时忘记门是关闭的,然后在训练过程中学习到如何关闭忘记门。
ft控制上一时刻记忆单元ct-1的信息融入记忆单元ct。在理解一句话时,当前词xt可能继续延续上文的意思继续描述,也可能从当前词xt开始描述新的内容,与上文无关。和输入门it相反, ft不对当前词xt的重要性作判断, 而判断的是上一时刻的记忆单元ct-1对计算当前记忆单元ct的重要性。当ft开关打开的时候,网络将不考虑上一时刻的记忆单元ct-1。
3. 输入门
it控制当前词xt的信息融入记忆单元ct。在理解一句话时,当前词xt可能对整句话的意思很重要,也可能并不重要。输入门的目的就是判断当前词xt对全局的重要性。当it开关打开的时候,网络将不考虑当前输入xt。
4. 输出门
输出门ot的目的是从记忆单元ct产生隐层单元ht。并不是ct中的全部信息都和隐层单元ht有关,ct可能包含了很多对ht无用的信息,因此, ot的作用就是判断ct中哪些部分是对ht有用的,哪些部分是无用的。
5. 记忆单元
记忆单元ct综合了当前词xt和前一时刻记忆单元ct-1的信息。这和ResNet中的残差逼近思想十分相似,通过从ct-1到ct的”短路连接”, 梯度得已有效地反向传播。 当ft处于闭合状态时, ct的梯度可以直接沿着最下面这条短路线传递到ct-1,不受参数W的影响,这是LSTM能有效地缓解梯度消失现象的关键所在。
四、GRU
1. 公式

2. 重置门
重置门rt用于控制前一时刻隐层单元ht-1对当前词xt的影响。如果ht-1对xt不重要,即从当前词xt开始表述了新的意思,与上文无关, 那么rt开关可以打开, 使得ht-1对xt不产生影响。
3. 更新门
更新门zt用于决定是否忽略当前词xt。类似于LSTM中的输入门it, zt可以判断当前词xt对整体意思的表达是否重要。当zt开关接通下面的支路时,我们将忽略当前词xt,同时构成了从ht-1到ht的”短路连接”,这梯度得已有效地反向传播。和LSTM相同,这种短路机制有效地缓解了梯度消失现象, 这个机制于highwaynetworks十分相似。
五、 其他
1. 为什么GRU和LSTM能够避免梯度消失?
GRU和LSTM的结构有点类似残差网络模块,通过维持细胞状态,将之前的网络信息传递到后面,避免了梯度消失/梯度爆炸等问题的出现。
2. 细胞状态是否包含着多种混合信息(为什么需要输出门)?
在LSTM中,输入门判断当前输入词对全局的重要性,而遗忘门判定上一时刻的细胞状态对当前的细胞状态的重要性。因此,当结合输入门和遗忘门更新完细胞状态后,当前的细胞状态不仅包含了与该时刻的输出相关的信息,可能也包含了和之后时刻相关的信息。此时,输出门的作用就是判断当前的细胞状态哪些对当前输出是有用的,哪些是无用的。