一、python 数据爬取
1、 认识数据分析思路
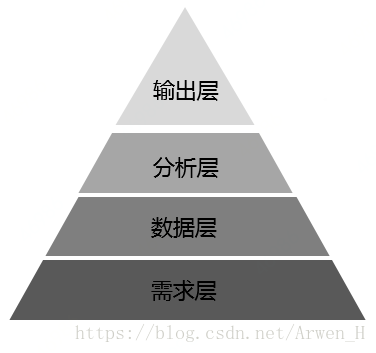
图1.1 四层思路
1.1 需求层
1.1.1 描述
需求是数据分析的开始,也是你要分析的目标方向。
理论上数据分析所从事的工作是给出业务相应的数据结果,而不是解决方案。
1.1.2 需求来源
场景一:监控到现有的指标出现了异常情况需要通过数据分析原因
场景二:公司要对现有的运营模式或者某个产品进行评估确定是否需要进行调整或者优化
场景三:公司下达了战略目标或短期目标需要通过分析看如何达成
1.1.3 需求具备本领
1、对业务、产品、需求背景有比较深的了解,以及足够对你才能去引导判断这个需求
2、光了解需求方是还不够的,你需要从获得的需求快速的去结合你所掌握的技能组工具有个初步的分析思路
3、综合判断后你再决定是否需要分析,应该怎么分析,与需求方达是否达成一致
1.2 数据层
1.1.1 描述
数据层大致分为:数据获取、数据清洗、数据整理
利用数据库才能实现大数据下的真正核心分析。
1.1.2 大数据
含义:是指无法用现有的软件工具提取、存储、搜索、共享、分析和处理的海量的、复杂的数据集合。
挖掘价值: 1.客户群体细分,然后为每个群体量定制特别的服务;2.模拟现实环境,发掘新的需求同时提高投资的回报率;3.加强部门联系,提高整条管理链条和产业链条的效率;4.降低服务成本,发现隐藏线索进行产品和服务的创新。
1.3 分析层
1.3.1 描述
整个分析过程需要掌握的工具为SQL、excel、python等。
分析步骤:描述分析——锁定方向——建模分析——模型测试——迭代优化——模型加载——洞察结论
1.3.2 数据描述
用来对数据进行基本情况的刻画,包括:数据总数、时间跨度、时间粒度、空间范围、空间粒度、数据来源等。
1.3.3 指标统计
用来作报告,分析实际情况的数据指标,可粗略分为四大类:变化、分布、对比、预测。
1.4 输出层
1.4.1 描述
一个完整的数据报告,应至少包含以下六块内容:报告背景、报告目的、数据来源、数量等基本情况、分页图表内容及本页结论、各部分小结及最终总结、下一步策略或对趋势的预测;
2、简单页面的爬取
2.1 准备requests库和User Agent
安装 pip install requests
requests库基于Urlib,是一个常用的http请求库
User agent——让爬虫假装是一个正常的用户在使用浏览器对目标网站的服务器发出请求
安装成功

图2.1 查看requests库
2.2 代码实现
import requests
from bs4 import BeautifulSoup
def get_info(url):
"""获得网页内容"""
r = requests.get(url)
return r.content
def parse_str(content):
"""解析结果为需要的内容"""
soup = BeautifulSoup(content, 'lxml')
infos = [v.find('a') for v in soup.find_all('li')]
r = []
for v in infos:
try:
r.append(' '.join([v.text, v['href']]))
except:
pass
return '
'.join(r)
def load_rlt(rlt, filename):
"""将结果保存到文件里"""
with open(filename, 'w') as fw:
fw.write(rlt)
def main():
url = 'http://hao.bigdata.ren/'
r = get_info(url)
rlt = parse_str(r)
load_rlt(rlt, 'bigdata.csv')
if __name__ == '__main__':
main()
print('finished!')
# 其中目的是爬取大数据网页(http://hao.bigdata.ren)的网址信息
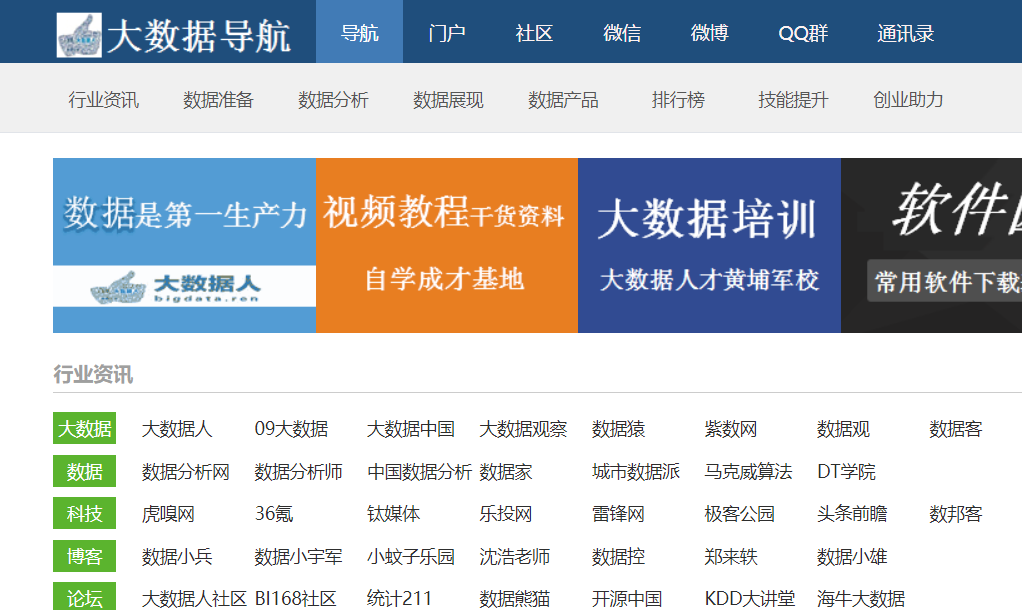
图2.2 网址展示
2.2.1 代码实现路径一
通过Visual Studio Code编辑器进行运行代码,以及生成自定义的bigdata.csv文件
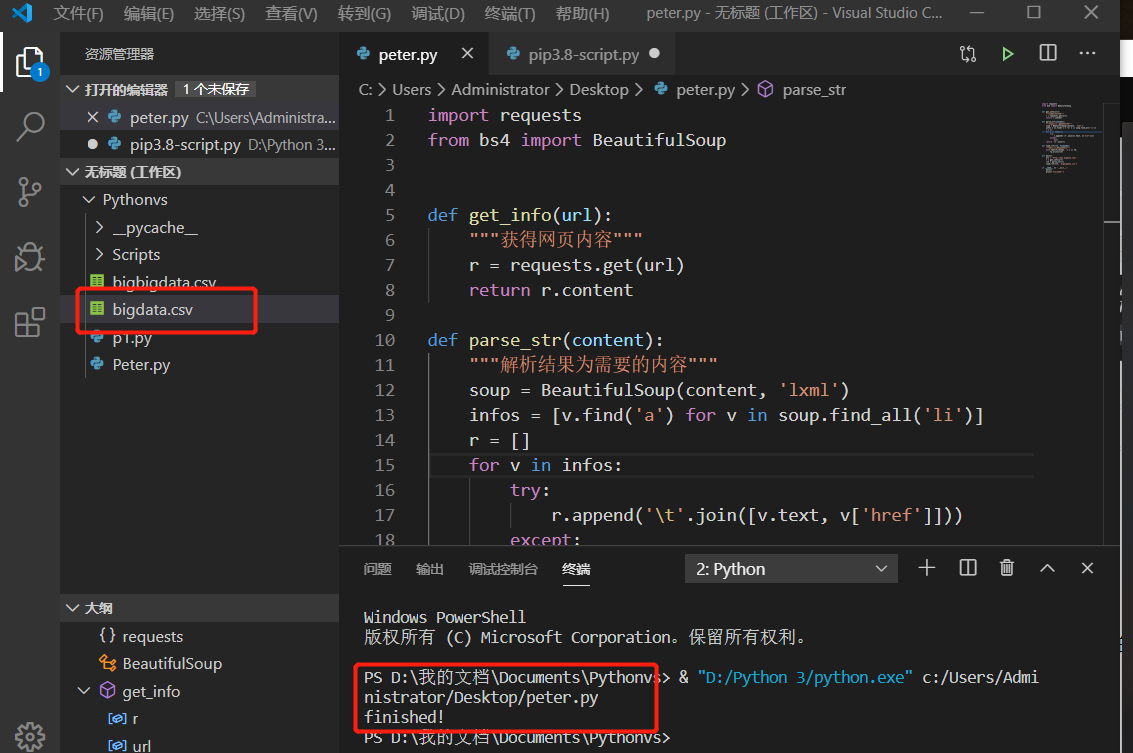
图2.3 VS实现代码
2.2.2 代码实现路径二
通过cmd输入命令行实现,事先得确认安装requests库
先复制该.py文件的地址到命令行中
cd .py的路径
接着
python .py名

图2.4 命令行运行
运行实现结果为生成bigdata.csv文件
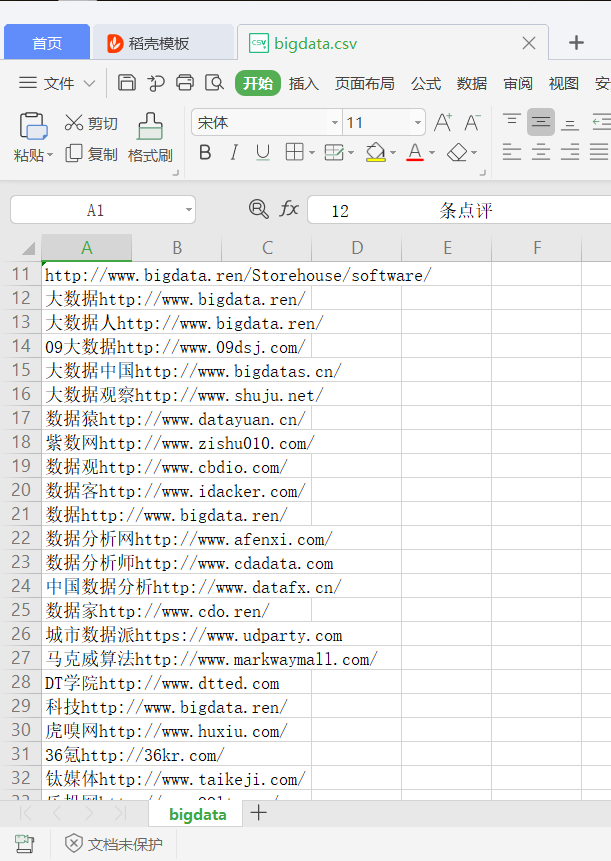
图2.5 成功保存桌面中