原文地址:https://www.cnblogs.com/duma/p/10666269.html
建议:结合第四版Hadoop权威指南阅读,更有利于理解
运行机制
运行一个 MR 程序主要涉及以下 5 个部分:
- 客户端: 提交 MR 作业,也就是我们运行 hadoop jar xxx 的命令后,启动的 Java 程序
- YARN ResourceManager: YARN 集群主节点,负责协调集群上计算资源的分配
- YARN NodeManager:YARN 集群从节点,负责启动和监视机器上的容器(container)
- MapReduce Application Master:负责协调 MR 作业,当然 Spark 作业也有对应的 application master
运行 MR 任务的工作原理如下图,本图摘自《Hadoop 权威指南(第四版)》:
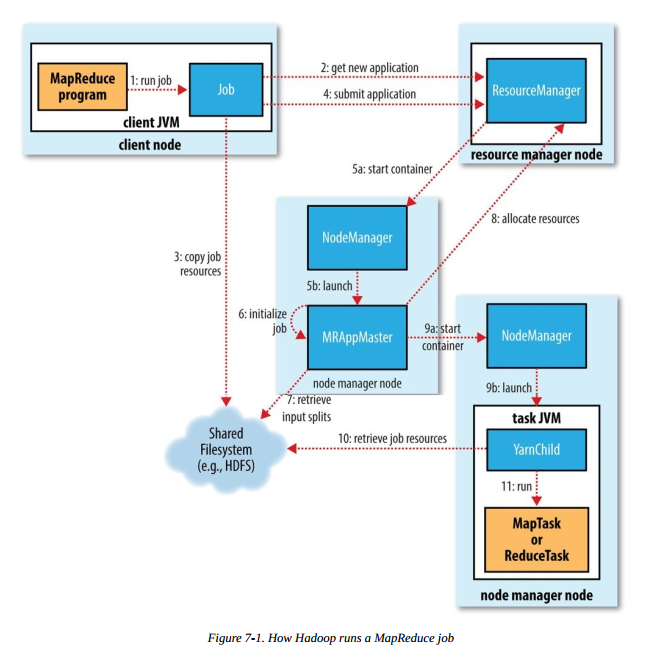
步骤1 是我们在客户端节点(集群中的某台机器)执行 hadoop jar xxx 命令后,启动 MR 作业的流程,后续会涉及以下几个重要流程
- 作业的提交和初始化
- 任务的分配与执行
- 进度和状态的更新
下面会详细介绍每个流程。这里我们将编写的整个 MR 程序叫做作业,MR作业运行后的 map 或 reduce 任务统称为任务。
任务的提交和初始化
作业的提交
- 向 ResourceManager 申请一个新的应用 ID(步骤 2),之前的 MR 例子我们可以看到,应用 ID 的形式为:application_1551593879638_0009
- 计算作业分片检查作业的输入输出,若输入文件不可分割或者输入路径不存在,报错返回;如果没有指定输出路径或者输出路径已存在,报错返回
- 将作业运行所需的资源(jar、配置文件和分片信息等)复制到共享文件系统中(步骤 3),默认为 HDFS 。目录名称以应用 ID 命名
- 调用 ResourceManager 的 submitApplication() 方法提交作业(步骤4)
以上的流程均在客户端节点完成。
作业的初始化
ResourceManager 收到调用它的 submitApplication() 方法后,会在 NodeManager 中分配一个 container (步骤 5a),在 container 中启动 application master(步骤 5b) 。MapReduce application master 的主类是 MRAppMaster。application master 完成初始化后(步骤 6),从共享文件系统(如:HDFS)获取分片信息(步骤 7)。对每个分片创建一个 map 任务和 reduce 任务,并分配任务 ID。如果 application master 判断该任务不是 uber 任务,那么接下来会进行任务分配。
任务分配与运行
任务分配
application master 会为 map 任务和 reduce 任务向 ResourceManager 申请分配资源。map 任务的优先级高于 reduce 任务,且直到 5% 的 map 任务完成时,reduce 任务请求才能发出。reduce 任务可以在集群的任意机器执行,但 map 任务有数据本地化的限制,理想情况下数据分片和 map 任务在同一节点运行,即数据本地化(data local),这样 map 任务直接读取本地的数据,不需要网络 IO。如果达不到理想情况,可以在数据节点同一机架上启动 map 任务,即机架本地化(rack local),这样 map 任务从同机架上其他节点将数据拷贝到自己的节点。最差的情况是分片和 map 任务不在同一机架,需要跨机架拷贝数据。application master 申请的资源包括内存和 CPU 核心数,申请的大小可以通过 4 个属性指定:
- mapreduce.map.memory.mb:map 任务内存, 单位:MB,默认:1024
- mapreduce.map.cpu.vcores:map 任务 CPU 核心数,默认:1
- mapreduce.reduce.memory.mb:reduce 任务内存,单位:MB,默认:1024
- mapreduce.reduce.cpu.vcores:reduce 任务 CPU 核心数,默认:1
任务执行
ResourceManager 为任务在某个 NodeManager 上分配容器后(步骤 9a),application master 会与该 NodeManager 通信来启动容器(步骤 9b)。该任务的主类为 YarnChild,该任务运行前会先将共享文件系统(如:HDFS)上的文件本地化(步骤 10),文件包括:配置文件、JAR包和分布式缓存文件。最后,运行 map 或 reduce 任务(步骤 11)。
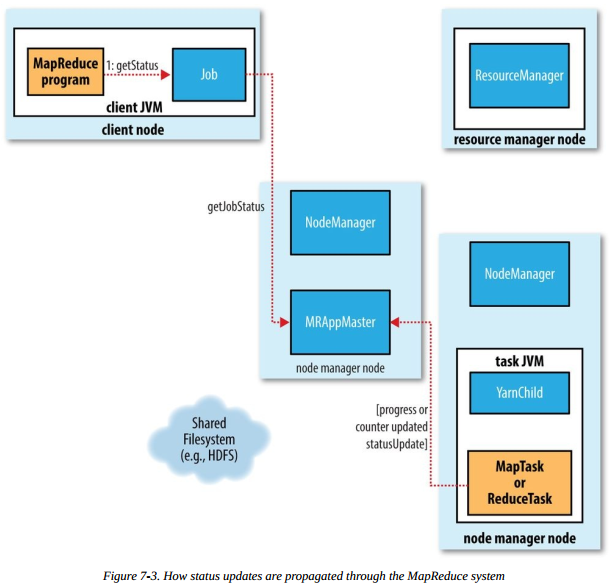
进度和状态更新
当用户成功提交并且作业成功运行后,用户希望能够看到作业的运行状态。一个作业和它的每个任务都有一个状态,包括:作业或任务的状态(比如,运行中、成功或失败),map 或 reduce 任务的进度以及计数器值等。
- 当 map 或 reduce 任务运行时,通过接口向自己的 application master 上报进度和状态
- 作业的运行期间,客户端请求 application master 以获得最新的状态
流程图如下:
作业的完成
application master 接到最后一个任务成功完成的通知后,便把作业置位成功得状态。可以端查询到任务成功完成后,从 waitCompletion() 方法返回。作业的统计信息和计数器值输出在控制台。最后,application master 会做一些清理工作,作业信息由 JobHistoryServer 存档,以便用户以后查询。
小结
本章主要介绍 MR 作业的运行机制,并且了解了 YARN 集群主从节点职责及其相互之间的配合。通过这篇文章的介绍希望读者对 MR 作业的运行机制有大致的了解。我们可以简单总结下本章介绍的相关组件的作用。本文主要参考《Hadoop 权威指南(第四版)》和 Hadoop 官方文档,有兴趣的读者可以深入研究,一起探讨。