论文地址:https://arxiv.org/pdf/1406.4729.pdf
论文翻译请移步:http://www.dengfanxin.cn/?p=403
一、背景:
传统的CNN要求输入图像尺寸是固定的(因为全连接网络要求输入大小是固定的)
- crop处理,可能不包含整个物体,还会丢失上下文信息
- warping处理,会导致图像变形
- 以上都会导致CNN对不同scale/size泛化能力不强


优点
- 不管输入尺寸为多少,SPP都能生成固定尺寸的输出,这使得CNN无需固定输入图片尺寸
- CNN使用多尺度图片输入进行训练,增加了scale-invariance,减少了过拟合
- SPP运用了多尺度的信息,空间信息更加丰富,使得CNN对物体的形变更加robust
- SPP可以广泛运用在任何CNN架构上,提高performance
二、SPP对R-CNN的改进:
1、使用了SPP灵活改变网络输入尺寸
2、将整张图片一次性输入CNN提取特征,将提取出的region proposal的坐标映射到feature map上,共享了计算
改进细节:
1、SPP

- 将feature map(假设有K个channel)划分为固定数量的bin(见上图的网格,假设bin的数目为
),在每个bin里使用Max Pooling(或者AvgPooling)
- 最终每个金字塔得到
-dimension的特征向量,然后拼接起来
- 值得注意的是,最粗粒度的金字塔级别,只是用了一个bin,这等同于Global Average Pooling
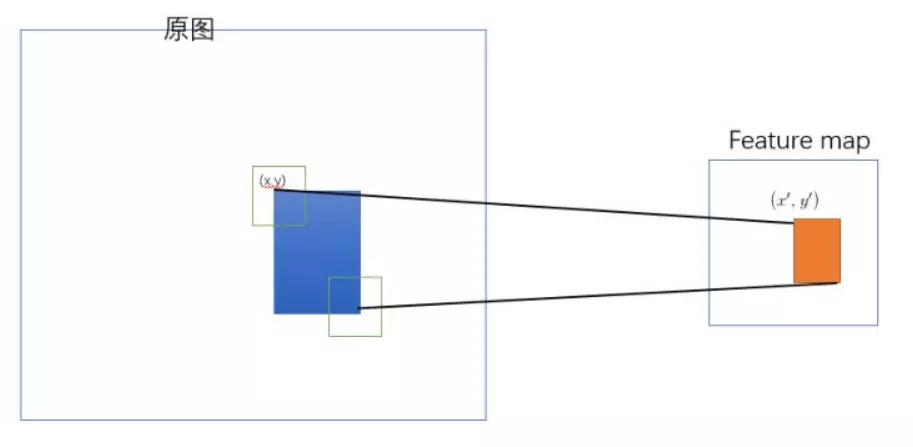


更多映射推理细节详见:https://blog.csdn.net/ibunny/article/details/79397399
3、训练方式
三、SPP-Net网络结构:
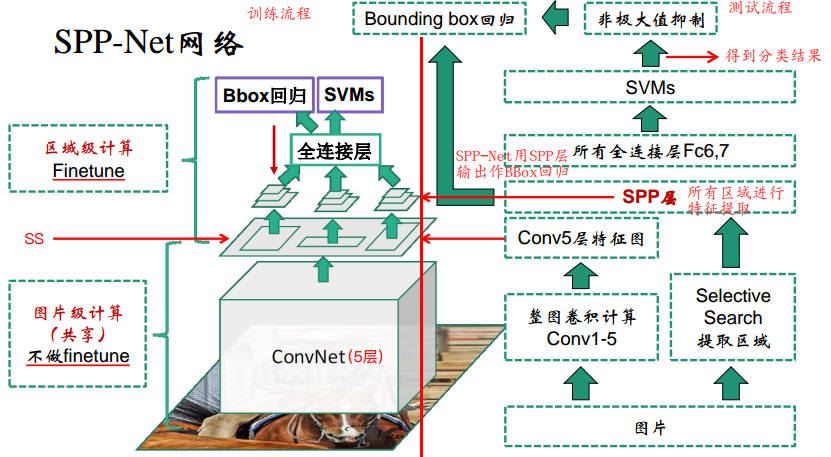
左边是训练流程,右边是测试流程,注意SPP-Net是直接用SPP池化层的输出特征作Bounding Box的回归,不像R-CNN是用Conv5的特征。

测试过程:
输入任意尺寸大小的图像,类似R-CNN,利用SS得到近2K推荐区域
通过卷积网络进行一次特征提取,得到特征图
通过ROI映射计算得到推荐区域映射到特征图的特征
输入SPP得到固定尺寸的特征
然后类似R-CNN,通过全连接层,再输入SVM得到分类概率
NMS处理
对处理后的结果,结合SPP输出特征进行边框回归
训练过程:
1、依旧是预训练好的网络,以及2K推荐区域,得到每个区域的SPP pooling层的一维特征
2、fine-tune(最大不同)
- 只fine-tune全连接网络
- FC6,FC7,FC8
- FC8被换成了21-way(20个类+背景)
- 初始化为Guassian(0, 0.01)
- learning rate从1e-4到1e-5
- 250K个batch使用1e-4
- 50k个batch使用1e-5
- 正负例平衡
- 每个batch中25%是正例,75%为负例
- IOU threshold
- 正例为0.5-1
- 负例为0.1-0.5
3、SVM
- IOU threshold为0.3
- 负例互相之间IOU超过70%则去除一个
- 使用了hard negtive mining的策略来训练SVM
4、Bbox Regression
- 使用了和R-CNN里一样的边框回归来refine坐标
- IOU阈值为0.5
四、SPP-Net缺点
SPP-Net只解决了R-CNN卷积层计算共享的问题,但是依然存在着其他问题:
(1) 训练分为多个阶段,步骤繁琐: fine-tune+训练SVM+训练Bounding Box
(2) SPP-Net在fine-tune网络的时候固定了卷积层,只对全连接层进行微调,而对于一个新的任务,有必要对卷积层也进行fine-tune。(分类的模型提取的特征更注重高层语义,而目标检测任务除了语义信息还需要目标的位置信息)
参考资料:
https://blog.csdn.net/bryant_meng/article/details/78615353
https://www.jianshu.com/p/b2fa1df5e982
https://blog.csdn.net/ibunny/article/details/79397399