基本概念
规则学习概念:机器学习中的规则(rule)通常是指语义明确、能描述数据分布所隐含的客观规律或领域概念、可写成"若…则…"形式的逻辑规则。规则学习(rulelearning)是从训练数据中学习出一组能用于对未见示例进行判别的规则。
形式化定义规则
- 左侧称为规则头
- 右侧称为规则体
- L为规则的长度
- 又叫if-then规则
规则冲突
冲突定义:一个示例被判别结果不同的多条规则覆盖;
解决方法:
- 投票法:判别相同的规则数最多的结果作为最终结果
- 排序法:在规则集合上定义一个顺序->带序规则学习/优先级规则学习
- 元规则法:定义关于规则的规则(元规则)来指导使用规则集
规则分类
- 命题规则:原子命题+逻辑连接词
- 一阶规则:原子公式,谓词、量词
一阶规则比(逻辑规则)强很多,能表达复杂的关系,称为关系型规则,其语义层面与人类的语义层面一致。
序贯覆盖
规则学习的目标:参数一个能覆盖尽可能多的样例的规则集,最直接的方法“序贯覆盖”(逐条归纳):在训练集上每学到一条规则,就将该规则覆盖的训练样例去除,然后以剩下的训练样例组成训练集重复上述过程。由于每次只处理一部分数据,因此也称为分治(separate-and-conquer)策略。
关键:如何从训练集学出单条规则
学习规则的方法
- 基于穷尽搜索的方法
- 从空规则开始,将正例类别作为规则头,逐个遍历训练集中的每个属性及取值。
- 在属性和候选值较多时会存在组合爆炸的问题。
- 自顶向下
- 从比较一般的规则开始,逐条添加新文字以缩小规则覆盖范围
- 生成-测试法
- 规则逐渐特化
- 覆盖范围从大到小
- 对噪声的鲁棒性较强,适用于命题规则学习
- 先考虑规则的准确性,然后考虑覆盖的样本数,然后考虑属性次序等等
- 自底向上
- 从比较特殊的规则开始,逐渐删除文字以扩大规则覆盖范围
- 数据驱动法
- 规则逐渐泛化
- 适合于训练样本较少
- 适用于假设空间较复杂的任务,如一阶规则学习
评价规则优劣的标准(根据具体任务情况设计适当的标准):
- 先考虑规则准确率(准确率=n/m。n:规则覆盖的正例数,m:覆盖的样例总数)
准确率相同时,考虑覆盖样例数,准确率、覆盖样例数都相同时考虑属性次序。
剪枝优化
规则生成本质上是一个贪心搜索过程,需要一定的机制来缓解过拟合的风险,最常见的做法是剪枝(pruning)。
预剪枝:剪枝可发生在规则生长过程中;
后剪枝:也可发生在规则产生后;
通常是基于某种性能度量指标来评估增/删逻辑文字前后的规则性能,或增/删规则前后的规则集性能,从而判断是否要进行剪枝。
统计显著性检验
- CN2——似然率统计量LRS,采用集束搜索,最早考虑过拟合的规则学习方法。
-
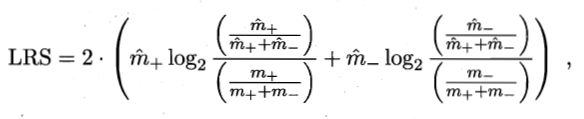
- LRS越大,采用规则集进行预测与直接使用训练集正、反例比例进行猜测的差别越大。
- LRS越小,规则集的效果越可能是偶然现象。
后剪枝
- 减错剪枝REP
- 一次训练集学习规则集R
- 多轮剪枝:每轮穷举所有可能的简直操作,然后用验证集对剪枝产生的所有候选规则集进行评估,保留最好者
- 循环多次
- 设训练样本数为m,时间复杂度O(m4)
- IREP(Incremental REP)
- 在REP上改进
- 每次生成一条规则立即在验证集上进行剪枝得到规则,并将覆盖样例去除
- 时间复杂度O(mlog2m)
- RIPPER(预剪枝+后处理优化)


一阶规则学习
命题规则学习的缺陷:难以处理对象之间的关系。
引入领域知识
- 属性重构:在现有属性基础上构造新的属性
- 函数约束:基于领域知识设计某种函数机制约束假设空间
First-Order Inductive Learner(FOIL)
- 遵循序贯覆盖,采用自顶向下(泛化到特化的过程)的规则归纳策略;
- FOIL增益
- 和分别表示增加候选文字后新规则所覆盖的正负样本数
- 和分别表示原本规则所覆盖的正负样本数
- 因为关系数据中的不平衡性,仅考虑正例的信息量
- FOIL可以被看做是命题规则学习和归纳逻辑程序设计之间的过渡,但其自顶向下的规则生成过程不支持嵌套,所以表达能力仍有不足。
参考自:https://blog.csdn.net/Julialove102123/article/details/80104962