思路
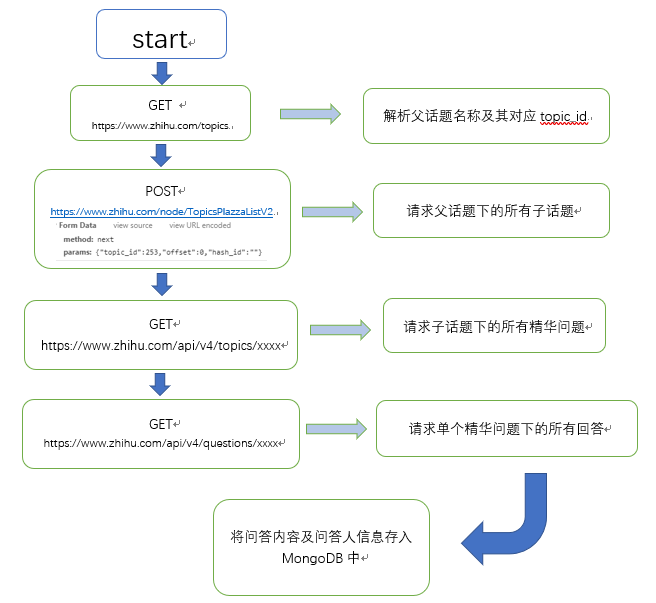
我的整个算法的思路还是很简单的,文字版步骤如下:
1、通过话题广场进入某个话题的页面,避免了登陆注册页面的验证,查找到对应要爬取的话题,从 url 中得到话题id
2、该页面的所有资源采用了延迟加载,如果采用模拟浏览器进行加载的话还是很麻烦,经研究后发现知乎有前后端数据传输的api,所以获取数据方面是基于知乎提供的api
3、设置 offset 和 limit,以及将爬取的评论用几个正则和简单的去重操作进行处理,就能开始获取数据并存储到数据库里
用法
1、进入某个话题,得到话题ID,拿西邮为例,url为:https://www.zhihu.com/topic/20019540/top-answers,
则得到话题id为 20019540,并在在 main 中修改对应变量值
2、在 ZhiHuCrawler.py 代码中设置 q_num (爬取的精华问题的个数), ans_num (爬取的回答的问题个数)
3、在 saveMysql 方法中修改 mysql 的相关连接信息
4、执行该 ZhiHuCrawler 脚本
局限
1、知乎的反爬很简单,但是每年都在变,所以我版本适用于 2018 年的知乎,后续未知;
2、话题id只能手动获取,想改成非手动也很容易,可以拿上面的思路实现
3、去除脏数据时(评论去重)遇到了些困难还没有解决,比如对于恶意刷评论(内容重复),我们需要去重,但 mysql 中blog 长文本类型无法设置为唯一索引,所以现在设想解决方法有:
I) 将评论的头几句话保存一下来,然后用Unique约束去重
II) 先全部存下来,最后用Union查询取出不重复的评论
III) 编程语言那块去重,记在存入或取出的代码中加入去重功能,而不是数据库
github