在"14 磁盘及文件系统管理详解"中,我们详细介绍了磁盘的工作原理,但是,有一点我们一定要明白,作为现在存储数据的主要设备,机械磁盘早就是上个世纪的产品,而它的读写速度与内存、CPU比起来已经不在一个级别上,但是当前“大数据”背景下,我们有大量的数据需要进行存储,这样对磁盘的要求更加高了。
为了解决,或者是缓解磁盘读写存储速度慢,以及保证数据的冗余性,我们创建了RADI技术,同时,通过mdadm命令来管理软RAID。这一节内容,我们就来详细了解RAID技术和mdadm管理命令。
硬盘的分类(接口)
我们说电脑的核心部件为CPU、内存和I/O总线;他们之间的大概工作过程如下图:

1、我们要知道,系统要实现某一个应用的功能,就需要对应的启动这个应用的进程。而这个进程的运行与否,则取决于内核进程。所以,第一步,我们需要将内核进程调用CPU上,让内核进程调用你要实现的那个应用的进程内容。而这些进程内容默认都是存储在内存中的;
所以,我们说内存的大小直接决定了进程运行的快慢;
【这里要注意的是,我们的内存将进程分为一个一个的“页面”,而“页面”的大小正好就是2^n,所以,我们的磁盘上的数据块(block)的大小,也是以2^n来进行存储的,就是为了方便内存调用】
2、内核进程决定调用的哪个普通进程,比如,我要运行“mkdir”创建目录,则这个时候,“mkdir”的进程就会被调用到CPU上来运行;这个过程就是由内核进程来决定的;
3、“mkdir”的进程决定了调用磁盘的那些数据,而这个过程则由CPU通过控制总线来向磁盘发起控制指令;例如:运行 “mkdir /test” 则此时,CPU就会控制在 / 目录对应的磁盘来创建 test 目录;
4、如果是数据调用,则这个数据会通过数据总线,从磁盘上调用到内存中,方便应用进程来对该数据进行处理;
明白这个过程后,我们需要明白一个问题;不管是在数据传输、还是指令传输的时候,我们的CPU、磁盘、内存都来自于不同的厂家,而这些厂家之间的指令都是不同的。就好像一个说英语的和一个说汉语的之间无法沟通。这时候,我就需要两个东西来解决这个问题:1、驱动;2、控制器(接口)
驱动我们不多研究,这里我们重点说磁盘控制器:
主板上不同的接口,就是不同设备的控制器,他们都担任着控制指令转换的任务,也就是将CPU的控制指令装换为各个设备能够识别的控制指令。在保证指令能够读懂的情况下,来进行数据传输;
在硬盘设备上,我们根据不同的接口来区分不同的硬盘:
1、IDE并行总线:133Mbps
2、SATA串行总线:300Mbps、600Mbps
3、USB3.0串行接口:480Mbps
4、SCSI(small computer system interface 小型计算机系统接口)并行总线
5、SAS将SCSI并行总线接口作为串行总线接口
此时,我们回到我们最初提出的问题,在一台繁忙的服务器上面,单块磁盘没办法满足内存对于数据读取速度的要求了。这是候,就出现了RAID技术;
RAID的工作原理
RAID原理说白了,就是将多个磁盘同时为服务器提供数据读取与写入的服务;
原来磁盘用来连接服务器的那个接口,不再用来直接连接硬盘,而是连接一个特定的设备,而这个设备能将一个接口模拟成多个接口,用来连接硬盘,而接主机的那个口依然只有一个,这样,在CPU看来,后面接的硬盘依然是一个,而实际上已经接上了多个磁盘;
而这个中间设备,我们就叫做RAID(可以是硬件,也可以由软件模拟,模拟的叫软RAID,而硬件搭建的叫硬RAID,这内容我们之后再提),Redundant arrays of dependent disks 独立的磁盘冗余阵列。现在,它已经成为了一个企业级存储的标准解决方案;
条带与镜像
RAID如何进行数据存储呢?
100M的数据,将其存储于两个磁盘上,如果按照block单位来存储,则会被切分为过小的数据,不太适合,为了方便将数据存储,我们使用条带技术,将数据均匀的切分为多个“条带”;如下图,将100M的数据分为两个50M的条带分别存储于两块磁盘上;
在数据进行读取的时候,也是从来块次磁盘上面同时读取;
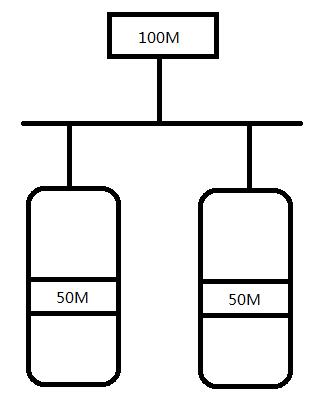
但是这样来存储数据也有一个问题,如果任何一个磁盘上的数据出现问题,则整个数据就无法读取了;
RAID如何进行数据冗余呢?(镜像)
为了解决条带技术带来的数据容易丢失的问题,我们又通过镜像的方式来对数据进行备份,这种方式就是将同一份数据在两个磁盘上都存放一份,其中一个磁盘数据丢失,还有另外一个磁盘的数据还在;但是,这种方式使得数据读写速度降低。
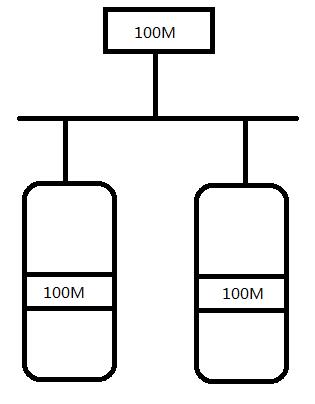
所以,就产生了各种级别的RAID。
RAID级别
首先,RAID级别仅仅只是代表磁盘的组织方式不同,没有上下之分;
RAID0 条带技术,实现的即为RAID0
RAID1 镜像技术,实现的即为RAID1
RAID10 对磁盘先做RAID1,在对磁盘做RAID0,则是RAID10

A,B两盘做RAID1,C,D两盘做RAID1,然后再一起做RAID0;
RAID01
A,B两盘先做RAID0,C,D两盘先做RAID0,然后再一起做RAID1;
R10要比R01好,因为,如果A,B做的RAID1,当B盘出现故障的时候,则在数据恢复的时候就可以直接从A盘进行数据恢复;如果A,B做的是RAID0,当B盘出现故障的时候,则在数据恢复的时候,就需要从C,D两盘中获取数据进行恢复;
RAID4 最少要三块盘,才能实现RAID4;其中一块校验盘,如果A,B或者校验盘任何一块盘坏了,都可以进行数据恢复。但是,在读取或者存储数据的时候都要经过校验盘,所以,这大大影响了数据的读取;于是就有了RAID5;
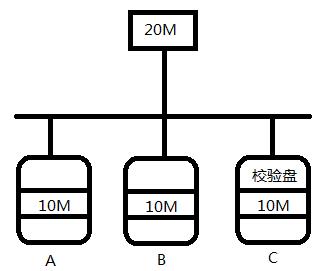
RAID5 如下图,相对于RAID4而言,RAID5则是将校验数据分布在各个磁盘上,则时候就不会单独拿出一个磁盘来作为校验盘了。这就解决了RAID4校验盘影响数据读写速度的问题;【这是最常用的RAID方式】

RAID50 磁盘先做RAID5,在做RAID0;
RAID6 相对于RAID5而言,RAID5只做了一次数据校验,而RAID6则由添加了一次数据校验的过程;
JBOD 磁盘大小可以不停的累加,当单个文件特别大的时候,并且在逐渐变大的时候,空间不够用了,就可以使用该技术;Hadoop就需要使用到该技术;
硬RAID与软RAID
硬RAID是由特定的RAID卡来完成工作的。
这个RAID卡上包含自己的控制芯片,自己的内存,以及供电电池;硬RAID的配置需要在BIOS里面完成;做好了RAID以后,CPU是无法看到你的真正的磁盘了,而是一些虚拟的磁盘;当CPU需要将数据写入磁盘的时候,这时现将数据缓存在RAID卡上的内存上面,然后慢慢写入到磁盘中;当CPU要读取数据的时候,这个工作就由RAID的芯片来完成;
软RAID的实现是通过系统内核模块md(multi disks)来完成。
首先md会模拟出一个逻辑设备来,这个逻辑设备就是以md开头的文件,例如/dev/md0最后的数字只是一个标号而已;再进行数据存储的时候就会通过你对应的RAID级别进行存储;所以软RAID是由你的CPU完成的,这个性能是无法保证的;
mdadm管理命令(软RAID)
mdadm(md admin)md的管理器;将任何块设备做成RAID;
-C 创建
-l 级别 指定级别
-n 设备个数
-c chunk大小
--add
--del
-F 监控查看
-G 增加
-A 装配
-x 指定空闲盘自动填充坏盘
例如:mdadm -C /dev/md0 -a yes -l 0 -n 2 /dev/sdb{1,2}
【在创建这个虚拟的RAID磁盘的过程中,我们可以通过 cat /proc/mdstat 文件,看到磁盘的同步过程】
cat /proc/mdstat或fdisk -l查看创建RAID的相关信息;
mount /dev/md0 /mnt 挂载就能使用了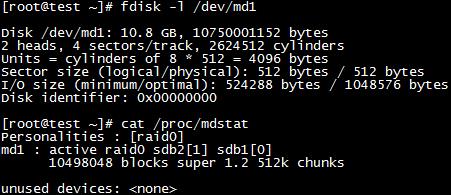
例如:mdadm -C /dev/md1 -a yes -n 2 -l 1 -x 1 /dev/sdb{1,2,3} #指定/dev/md1磁盘,然后 -x 指定一个备份盘;
mke2fs -j /dev/md1 格式化
mount /dev/md1 /media/ 挂载
mdadm -D /dev/md1 显示磁盘阵列RAID的详细信息

-f 可以模拟坏盘
mdadm /dev/md1 -f /dev/sdb1 #将sdb1模拟损坏
-r 移除坏盘
mdadm /dev/md1 -r /dev/sdb1 #将sdb1拔出来
-S 暂停运行整个磁盘阵列
mdadm -S /dev/md1 #停止这个整列
-A 再次启动磁盘整列
mdadm -A /dev/md1 /dev/sdb{1,2} 重新再启用这个RAID
watch 周期性的执行某命令,并以全屏的方式显示这个结果;
-n 制定周期长度
例如:watch -n 5 ‘命令’ #将当前RAID信息保存至配置文件,以便以后进行装配
mdadm -D --scan > /etc/mdadm.conf