一、集群简介
Redis Cluster是redis3.0后正式推出的分布式解决方案。
之前介绍了复制和哨兵,解决了高可用问题,通过复制,读操作可以分发到多个节点(读实现了负载均衡),但是写操作依然只有一个节点,无法实现写操作的负载均衡,但是依然面临单机内存和并发的瓶颈。
集群就是用来解决写操作负载均衡的问题。其核心有两个作用
- 数据分片:这是集群最最核心的功能,通过发片,突破了redis的单机内存限制,数据发布到多个节点,每个节点都可以提供读写操作,响应能力也得到提高
- 高可用:这个和复制-哨兵一样,每个节点都由主从组成,同时实现了自动故障转移。
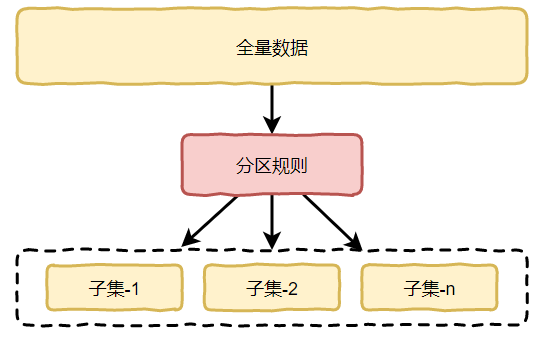
二、Redis Cluster数据分区原理
2.1 Hash分区方案
常见哈希分区主要两种:
- 节点取余分区
- 一致性哈希(distributed hash table)
2.1.1节点取余分区
N为节点的数量。这种方案优点是简单,缺点是当有节点数量变化(扩容or缩容),数据节点映射关系需要重新计算,会导致数据重新迁移。
一般用于节点可以预估不变的场景,比如数据库分表分库,比如订单库可以分64个,orderId mod 64可得到这个订单数据应该写入那个库。
2.1.2一致性哈希
实现思路是为系统中的每一个节点分配一个token,范围一般为0~2的32次方,这个这些token构成一个哈希环。
当有数据写入时,先根据key计算出哈希值X,然后顺时针寻找到第一个大于X的token的节点,然后把值存入该节点即可。下图中:
- A存入node1
- B存入node2
- 。。。
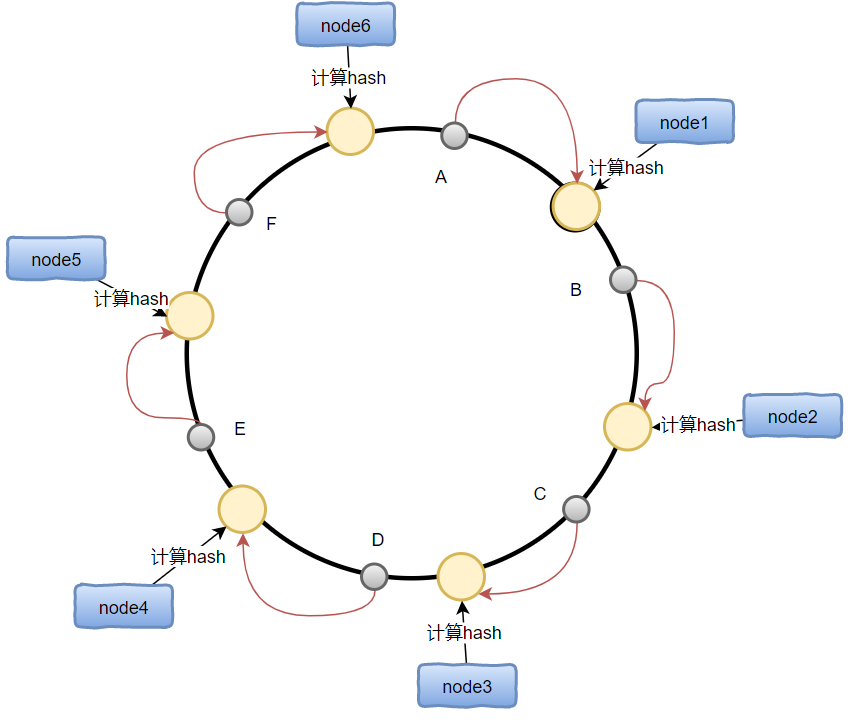
一致性哈希分区中,如果增加或者减少节点,只影响节点改节点相邻的节点,其他节点毫无影响,比如在node1之前增加一个节点,只会使得原来存储到node1的数据一部分数据(比如A)转移到新节点,其他节点毫无影响。
一致性哈希的最大问题是,当节点比较少时,新增或者删除节点会导致数据的分配严重不均衡。 在上图中,如果删除node1和node2:
- 原有node1和node2存储的数据会全部迁移到node3,导致node3的数据从原来的的1/6变成了1/2
- node(4,5,6)三个节点总共存储1/2,严重不平衡。
虚拟槽分区是对一致性哈希的改进,用来解决负载均衡的问题。
2.2 Redis Cluster数据分区方案
Redis Cluster采用虚拟槽分区,槽是介于实际节点和数据之间的虚拟概念,每个节点对应一定范围的槽,每个槽包含一定范围内的哈希值,使用了虚拟槽分区后,数据的映射关系从hash-》节点变成了hash-》槽-》节点。
Redis Cluster槽的范围是16384(016383)。所有键基于哈希函数映射到016383整数槽内(CRC取模),计算公式:
示意图如下:
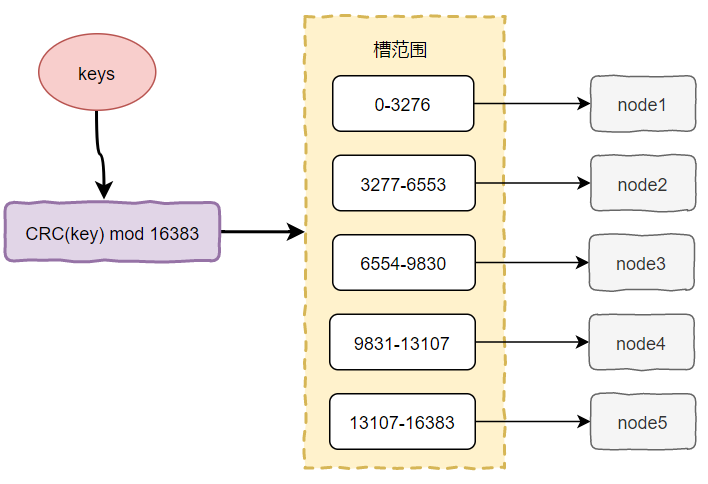
使用虚拟槽分区后,节点的变动对系统影响较小,比如上图中,删除node1,只需要对0-3276的槽重新分配即可。
三、搭建集群
搭建一个三主三从的集群,在同一台机器上,由端口号进行区分。
- 三主:7000,7001,7002
- 三从:8000,8001,8002
3.1 准备节点
7000节点配置如下:
#端口号
port 7000
#开启集群模式
cluster-enabled yes
#节点超时时间(毫秒)
cluster-node-timeout 15000
#集群内部配置文件
cluster-config-file "nodes-7000.conf"
logfile "log-7000.log"
protected-mode no
daemonize yes
依次配置7001,7002,8000,8001,8002。
启动6个节点:
src/redis-server redis-7000.conf
src/redis-server redis-7001.conf
src/redis-server redis-7002.conf
src/redis-server redis-8000.conf
src/redis-server redis-8001.conf
src/redis-server redis-8002.conf
配置相关说明
上面的配置中cluster-enabled 和cluster-config-file是集群相关的配置。
cluster-enabled 设置为yes,代表集群模式,默认redis是单机模式。
cluster-config-file是集群特有的配置文件,在redis启动的时候如果发现没有配置文件会自动创建一个配置文件。
打开配置文件,如果集群配置文件已经存在,则直接读取。集群配置文件由redis自动维护,无需手动修改。
7000首次启动后生成的集群配置文件如下:
877e9d061f80cea70285e823cbc4246041752149 :7000@17000 myself,master - 0 0 0 connected 5474 5798 11459 11958 12706 13735
vars currentEpoch 0 lastVoteEpoch 0
记录了集群的初始状态,最重要的是第一个40位的16进制字符串,是集群的节点ID,节点ID在集群初始化的时候只创建一次,重启后会加载集群配置文件进行重用。集群节点ID不用于redis的运行id,运行id每次重启后都会变好。
3.2 创建集群
直接使用redis-cli命令来创建(redis5.0之后)
输入命令
redis-cli --cluster create 192.168.118.129:7000 192.168.118.129:7001 192.168.118.129:7002 192.168.118.129:8000 192.168.118.129:8001 192.168.118.129:8002 --cluster-replicas 1
--cluster-replicas 1表示每一个主节点分配一个从节点。
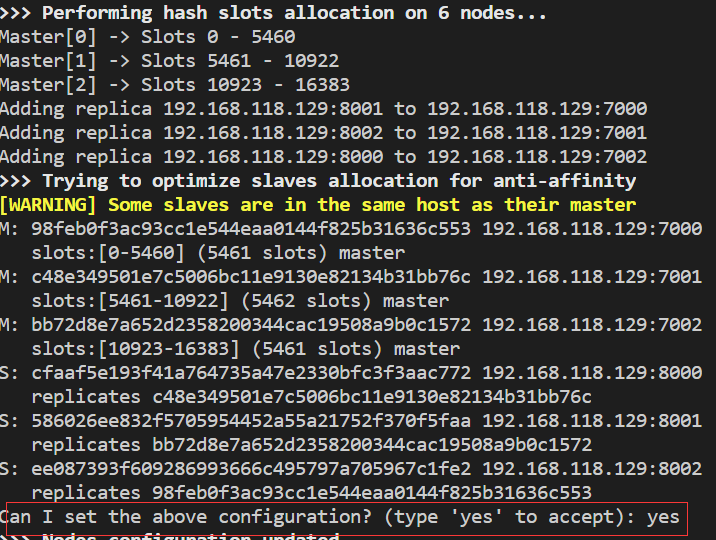
(上面的warning是因为我把所有节点部署到了同一个机器)
输入yes继续
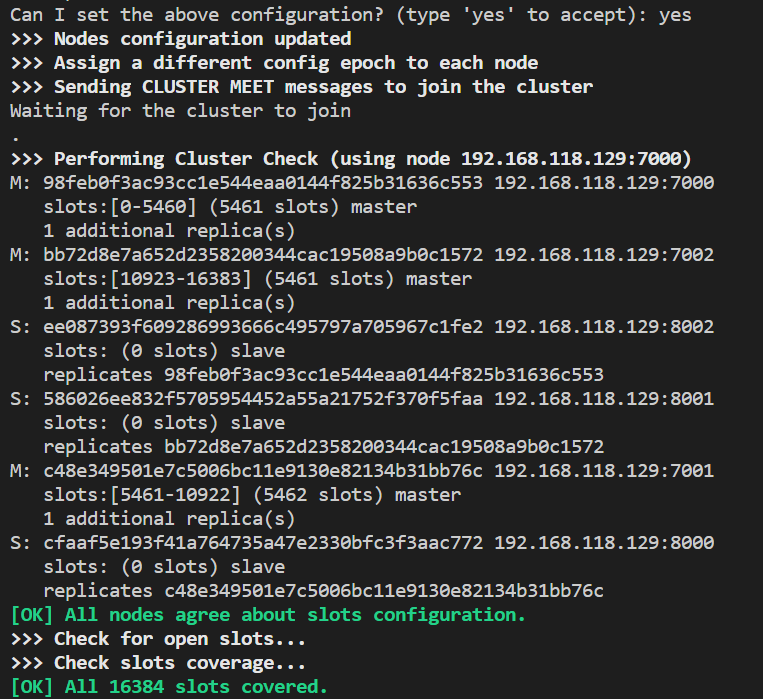
集群配置成功,16384个slots分配完毕。
整体结构
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.118.129:8001 to 192.168.118.129:7000
Adding replica 192.168.118.129:8002 to 192.168.118.129:7001
Adding replica 192.168.118.129:8000 to 192.168.118.129:7002
用上面命令创建的集群是无法手工指定主从关系的。
四、节点通信原理
4.1 Gossip消息
Redis采用Gossip协议(P2P),Gossip协议的工作原理就是节点之间不断通信交换信息,一段时间后所有节点都会知道集群的完整信息,类似于流言传播,类似于下图:
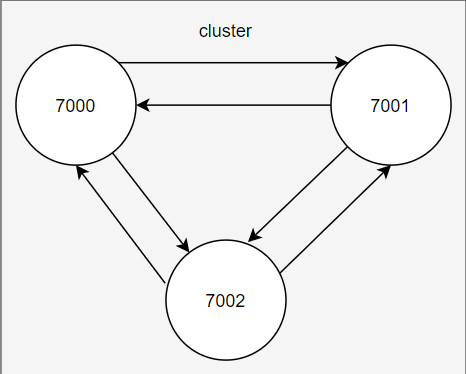
通信过程:
- cluster中的每一个节点都会单独开辟一个TCP通道,用于节点之间的彼此通信,通信端口号是在节点基础端口号上加10000,比如原端口号是7000,则对应的Gossip端口号则为17000。
- 每个节点在固定周期内通过特定规则选择几个节点发送ping消息
- 接收到ping消息的节点用pong消息作为响应。
Gossip消息类型:

Gossip消息解析流程:
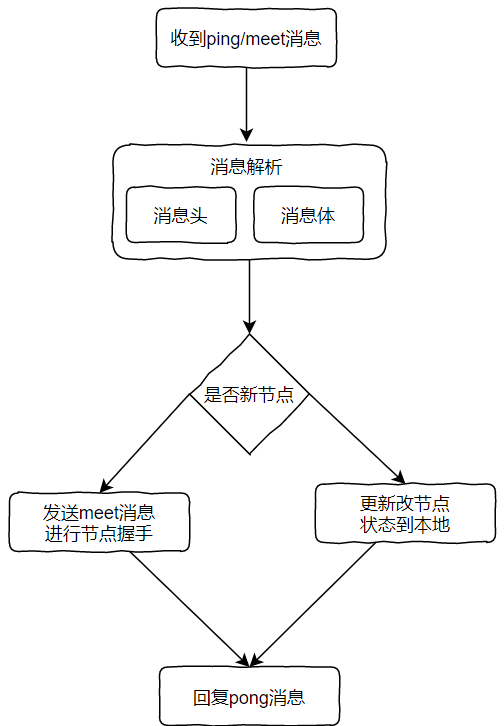
meet
4.2 通信节点选择
上面的Gossip消息中,ping/pong消息都需要携带当前节点的信息和部分其他节点的信息(状态等),这些频繁的信息交换势必会加重带宽和计算负担。依次每次选择多少个节点进行通信(每次要发给多少个节点)变得特别重要:
- 太多:交换成本高
- 太少:消息交换频率低,影响故障判断,节点发现的速度。
具体选择:
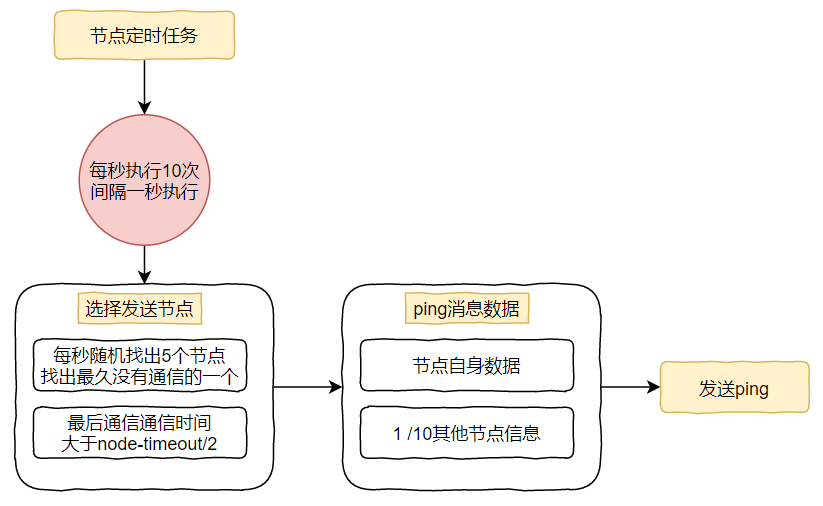
选择发送节点
5个节点是指集群内随机找5个节点,取其中一个其他节点发送ping。
10次:针对上一步选出来的一个节点每100毫秒扫描一次本地的节点列表,如果发现节点最近一次接受pong消息的时间大于cluster-node-timeout/2 ,则需要给该节点发送ping消息,总节点数量:
- num(node.pong_received > cluster_node_timeout/2)
ping消息数量
自身节点数量+1/10其他节点的数量
由此可见,节点的cluster_node_timeout和整个集群节点的数量都会影响集群节点之间的信息交换。