APScheduler
APScheduler是基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。
APScheduler提供了多种不同的调度器,方便开发者根据自己的实际需要进行使用;同时也提供了不同的存储机制,可以方便与Redis,数据库等第三方的外部持久化机制进行协同工作,总之功能非常强大和易用。
安装
使用 pip 包管理工具安装 APScheduler 是最方便快捷的。

APScheduler的主要的调度类
在APScheduler中有以下几个非常重要的概念,需要大家理解:
- 触发器(trigger)
包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行,根据trigger中定义的时间点,频率,时间区间等等参数设置。除了他们自己初始配置以外,触发器完全是无状态的。
- 作业存储(job store)
存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。job store支持主流的存储机制:redis, mongodb, 关系型数据库, 内存等等
- 执行器(executor)
处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。基于池化的操作,可以针对不同类型的作业任务,更为高效地使用cpu的计算资源。
- 调度器(scheduler)
通常在应用只有一个调度器,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。
这里简单列一下常用的若干调度器:
- BlockingScheduler:仅可用在当前你的进程之内,与当前的进行共享计算资源
- BackgroundScheduler: 在后台运行调度,不影响当前的系统计算运行
- AsyncIOScheduler: 如果当前系统中使用了async module,则需要使用异步的调度器
- GeventScheduler: 如果使用了gevent,则需要使用该调度
- TornadoScheduler: 如果使用了Tornado, 则使用当前的调度器
- TwistedScheduler:Twister应用的调度器
- QtScheduler: Qt的调度器
APScheduler提供的多种调度器,可以根据具体需求来选择合适的调度器:
BlockingScheduler:适合于只在进程中运行单个任务的情况,通常在调度器是你唯一要运行的东西时使用。
BackgroundScheduler: 适合于要求任何在程序后台运行的情况,当希望调度器在应用后台执行时使用。
AsyncIOScheduler:适合于使用asyncio框架的情况
GeventScheduler: 适合于使用gevent框架的情况
TornadoScheduler: 适合于使用Tornado框架的应用
TwistedScheduler: 适合使用Twisted框架的应用
QtScheduler: 适合使用QT的情况
触发器组件(trigger)
调用方式
add_job() 中 trigger 参数为调用方式,有 interval, day, cron 三种值
- date 日期:触发任务运行的具体日期
- interval 间隔:触发任务运行的时间间隔
- cron 周期:触发任务运行的周期
触发器date
特定的时间点触发,只执行一次。参数如下:
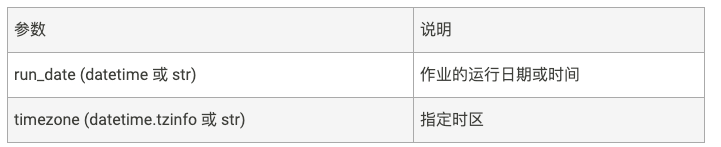
使用例子:
from datetime import datetime from datetime import date from apscheduler.schedulers.blocking import BlockingScheduler def job(text): print(text) scheduler = BlockingScheduler() # 在 2019-8-30 运行一次 job 方法 scheduler.add_job(job, 'date', run_date=date(2019, 8, 30), args=['text1']) # 在 2019-8-30 01:00:00 运行一次 job 方法 scheduler.add_job(job, 'date', run_date=datetime(2019, 8, 30, 1, 0, 0), args=['text2']) # 在 2019-8-30 01:00:01 运行一次 job 方法 scheduler.add_job(job, 'date', run_date='2019-8-30 01:00:00', args=['text3']) scheduler.start()
触发器interval
固定时间间隔触发。参数如下:
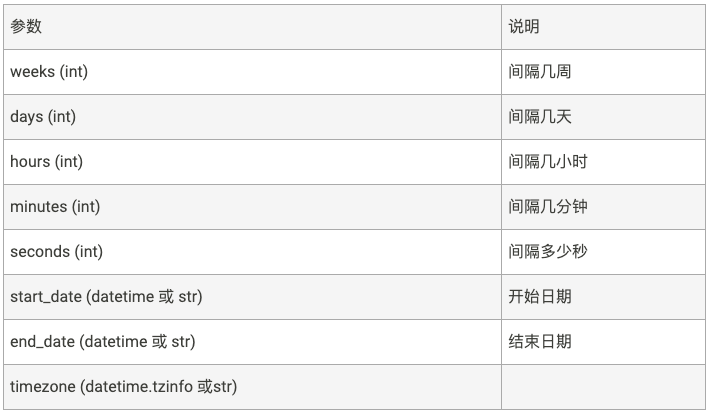
使用例子:
import time from apscheduler.schedulers.blocking import BlockingScheduler def job(text): t = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) print('{} --- {}'.format(text, t)) scheduler = BlockingScheduler() # 每隔 1分钟 运行一次 job 方法 scheduler.add_job(job, 'interval', minutes=1, args=['job1']) # 在 2019-08-29 22:15:00至2019-08-29 22:17:00期间,每隔1分30秒 运行一次 job 方法 scheduler.add_job(job, 'interval', minutes=1, seconds = 30, start_date='2019-08-29 22:15:00', end_date='2019-08-29 22:17:00', args=['job2']) scheduler.start() ''' 运行结果: job2 --- 2019-08-29 22:15:00 job1 --- 2019-08-29 22:15:46 job2 --- 2019-08-29 22:16:30 job1 --- 2019-08-29 22:16:46 job1 --- 2019-08-29 22:17:46 ...余下省略... '''
触发器cron
在特定时间周期性地触发。参数如下:

(year=None, month=None, day=None, week=None, day_of_week=None, hour=None, minute=None, second=None, start_date=None, end_date=None, timezone=None)
除了week和 day_of_week,它们的默认值是*
例如day=1, minute=20,这就等于year='*', month='*', day=1, week='*', day_of_week='*', hour='*', minute=20, second=0,工作将在每个月的第一天以每小时20分钟的时间执行
表达式类型

注!month和day_of_week参数分别接受的是英语缩写jan– dec 和 mon – sun
当设置的时间间隔小于,任务的执行时间,线程会阻塞住,等待执行完了才能执行下一个任务,可以设置max_instance指定一个任务同一时刻有多少个实例在运行,默认为1
使用例子:
import time from apscheduler.schedulers.blocking import BlockingScheduler def job(text): t = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) print('{} --- {}'.format(text, t)) scheduler = BlockingScheduler() # 在每天22点,每隔 1分钟 运行一次 job 方法 scheduler.add_job(job, 'cron', hour=22, minute='*/1', args=['job1']) # 在每天22和23点的25分,运行一次 job 方法 scheduler.add_job(job, 'cron', hour='22-23', minute='25', args=['job2']) scheduler.start() ''' 运行结果: job1 --- 2019-08-29 22:25:00 job2 --- 2019-08-29 22:25:00 job1 --- 2019-08-29 22:26:00 job1 --- 2019-08-29 22:27:00 ...余下省略... '''
添加任务
添加任务的方法有两种:
- 通过调用add_job()
- 通过装饰器scheduled_job()
第一种方法是最常用的方法。第二种方法主要是方便地声明在应用程序运行时不会更改的任务。该 add_job()方法返回一个apscheduler.job.Job实例,可以使用该实例稍后修改或删除该任务。
import time from apscheduler.schedulers.blocking import BlockingScheduler scheduler = BlockingScheduler() @scheduler.scheduled_job('interval', seconds=5) def job1(): t = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) print('job1 --- {}'.format(t)) @scheduler.scheduled_job('cron', second='*/7') def job2(): t = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) print('job2 --- {}'.format(t)) scheduler.start() ''' 运行结果: job2 --- 2019-08-29 22:36:35 job1 --- 2019-08-29 22:36:37 job2 --- 2019-08-29 22:36:42 job1 --- 2019-08-29 22:36:42 job1 --- 2019-08-29 22:36:47 job2 --- 2019-08-29 22:36:49 ...余下省略... '''
移除作业
移除 job 也有两种方法:remove_job() 和 job.remove()。
remove_job() 是根据 job 的 id 来移除,所以要在 job 创建的时候指定一个 id。
job.remove() 则是对 job 执行 remove 方法即可
scheduler.add_job(job_func, 'interval', minutes=2, id='job_one') scheduler.remove_job(job_one) job = add_job(job_func, 'interval', minutes=2, id='job_one') job.remvoe()
获取 job 列表
通过 scheduler.get_jobs() 方法能够获取当前调度器中的所有 job 的列表
暂停作业:
– apscheduler.job.Job.pause()
– apscheduler.schedulers.base.BaseScheduler.pause_job()
恢复作业:
– apscheduler.job.Job.resume()
– apscheduler.schedulers.base.BaseScheduler.resume_job()
修改作业 job
可以通过apscheduler.job.Job.modify() or modify_job()来动态修改job的属性信息,除了job id无法修改之外,都是可以修改的。
job.modify(max_instances=6, name='Alternate name')
另外我们也可以通过apscheduler.job.Job.reschedule() or reschedule_job()动态重新设置trigger,示例如下:
scheduler.reschedule_job('my_job_id', trigger='cron', minute='*/5')
关闭调度器
默认情况下调度器会等待所有正在运行的作业完成后,关闭所有的调度器和作业存储。如果你不想等待,可以将wait选项设置为False。
scheduler.shutdown()
scheduler.shutdown(wait=False)