转自:https://www.cnblogs.com/jimoer/p/14673646.html,https://juejin.cn/post/6844903921677238285
1.原理
- 基于语句的复制:在主数据库上执行的SQL语句,在从数据库上会重复执行一遍。MySQL默认采用的就是这种复制,效率比较高。但如果SQL中使用uuid()、rand()等函数,那么复制到从库的数据就会有偏差。
- 基于行的复制,指将更新处理后的数据复制到从数据库。但如果修改的行数过多,造成的开销比较大。
- 混合复制,默认采用语句复制,当发现语句不能进行精准复制数据时(例如语句中含有uuid()、rand()等函数),采用基于行的复制。

MySQL 主从复制涉及到三个线程:
- 一个在主节点的线程:
log dump thread - 从库会生成两个线程:一个 I/O 线程,一个 SQL 线程
-
主节点 log dump 线程
当从节点连接主节点时,主节点会为其创建一个 log dump 线程,用于发送和读取 Binlog 的内容。在读取 Binlog 中的操作时,log dump 线程会对主节点上的 Binlog 加锁;当读取完成发送给从节点之前,锁会被释放。主节点会为自己的每一个从节点创建一个 log dump 线程。
-
从节点I/O线程
当从节点上执行start slave命令之后,从节点会创建一个 I/O 线程用来连接主节点,请求主库中更新的Binlog。I/O 线程接收到主节点的 log dump 进程发来的更新之后,保存在本地 relay-log(中继日志)中。并将读取到的 Binlog文件名和位置保存到master-info 文件中,以便在下一次读取的时候能够清楚的告诉 Master :“ 我需要从哪个 Binlog 的哪个位置开始往后的日志内容,请发给我”。
中继日志是从服务器 I/O 线程将主服务器的 Binlog 日志读取过来,解析到各类 Events 之后记录到从服务器本地文件,然后根据这个进行数据同步。
mysql> show variables like '%relay%'; +---------------------------+------------------------------------------------+ | Variable_name | Value | +---------------------------+------------------------------------------------+ | max_relay_log_size | 0 | | relay_log | /data/mysql_6328_binlog/mysql-relay-bin.log | | relay_log_basename | /data/mysql_6328_binlog/mysql-relay-bin | | relay_log_index | /data/mysql_6328_binlog/mysql-relay-bin.index | | relay_log_info_file | relay-log.info | | relay_log_info_repository | TABLE | | relay_log_purge | ON | | relay_log_recovery | ON | | relay_log_space_limit | 0 | | sync_relay_log | 10000 | | sync_relay_log_info | 10000 | +---------------------------+------------------------------------------------+ 11 rows in set (0.00 sec)
具体参数介绍可见,https://www.cnblogs.com/rickiyang/p/13856388.html。
sql线程负责重放relay log,并在 relay log.info 中记录当前应用中继日志的文件名和位置点。但这是存在的问题是,如果一个主库的从库过多,那么要为每个从库生成一个log dump线程用于同步bin log,这将会对主库产生很大的压力,所以就出现了级联复制:
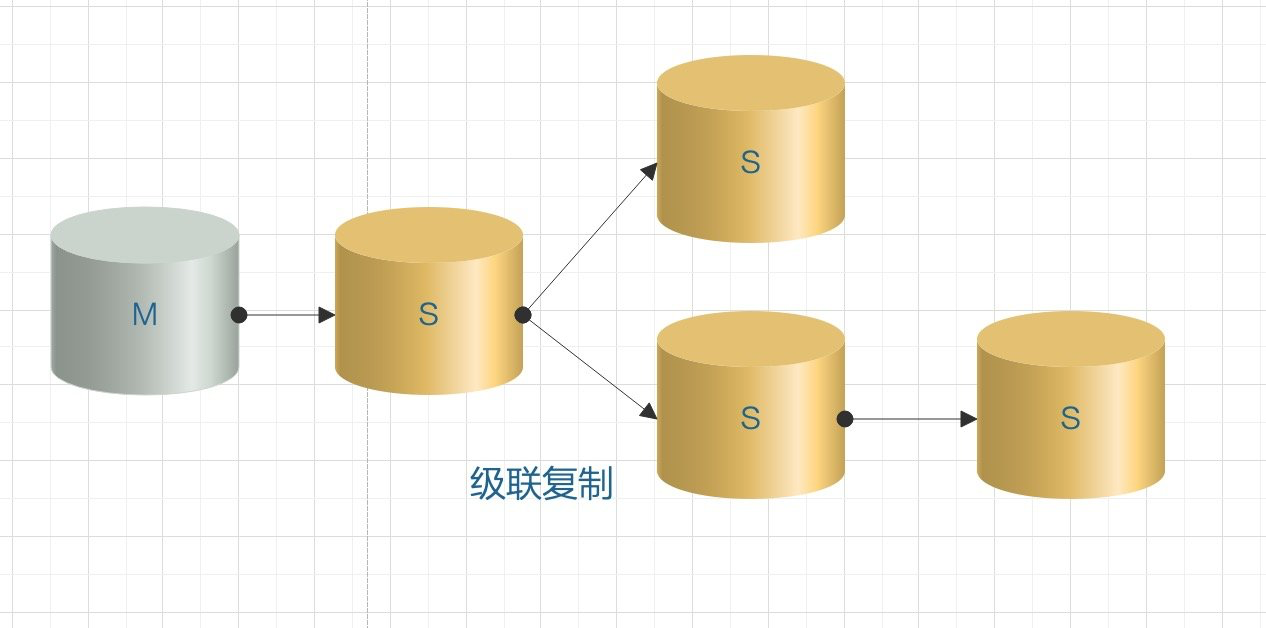
部分 slave 节点连接到它上一级的从节点上。这样就缓解了主服务器的压力。级联复制解决了一主多从场景下多个从库复制对主库的压力,带来的弊端就是数据同步延迟比较大。
风险:
主从延迟:因为 Slave 端是通过 I/O thread 单线程来实现数据解析入库;从库同步主库数据的过程是串行化的,而 Master 端写 Binlog 由于是顺序写效率很高(并行),当主库的 TPS 很高的时候,必然 Master 端的写效率要高过 Slave 端的读效率,这时候就有同步延迟的问题。通过show status查看延时。
改进:https://cloud.tencent.com/developer/article/1924123
在Mysql5.7之后可以用并行复制解决主从同步延时问题。从库开启多个sql线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志。
代码层面避免改后就查,因为查从从库的话,就可能会因为主从延时导致查不到,如果非要改后就查那么要保证直连主库,但可能就会失去了读写分离的意义了。