转自:https://aws.amazon.com/cn/big-data/what-is-hive/
https://www.jianshu.com/p/e9ec6e14fe52,https://blog.csdn.net/qq_26442553/article/details/80300714
1.简介
Facebook为了解决海量日志数据的分析而开发了Hive,Hive是一种用类SQL语句来协助读写、管理存储在分布式存储系统上大数据集的数据仓库软件。
Hive 让用户可以利用 SQL 读取、写入和管理 PB 级数据,将复杂的MapReduce编写任务简化为SQL语句。因为Hive语句最终会生成MapReduce任务去计算,所以不适用于实时计算的场景,它适用于离线分析。
- Hive 使用批处理,因此它可以快速操作非常大型的分布式数据库,Hive 会将 HiveQL 查询转换成在 Apache Hadoop 的分布式作业计划框架。
- 它会查询存储在分布式存储解决方案,如 Hadoop 分布式文件系统 (HDFS,hadoop Distribute file system) 。数据是存储在HDFS上的,Hive本身并不提供数据的存储功能。
- Hive将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如MySQL)。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 支持结构化和非结构化数据。为常见的 SQL 数据类型提供原生支持,如 INT、FLOAT 和 VARCHAR。
- 数据存储方面:它能够存储很大的数据集,并且对数据完整性、格式要求并不严格。
2.Hive架构
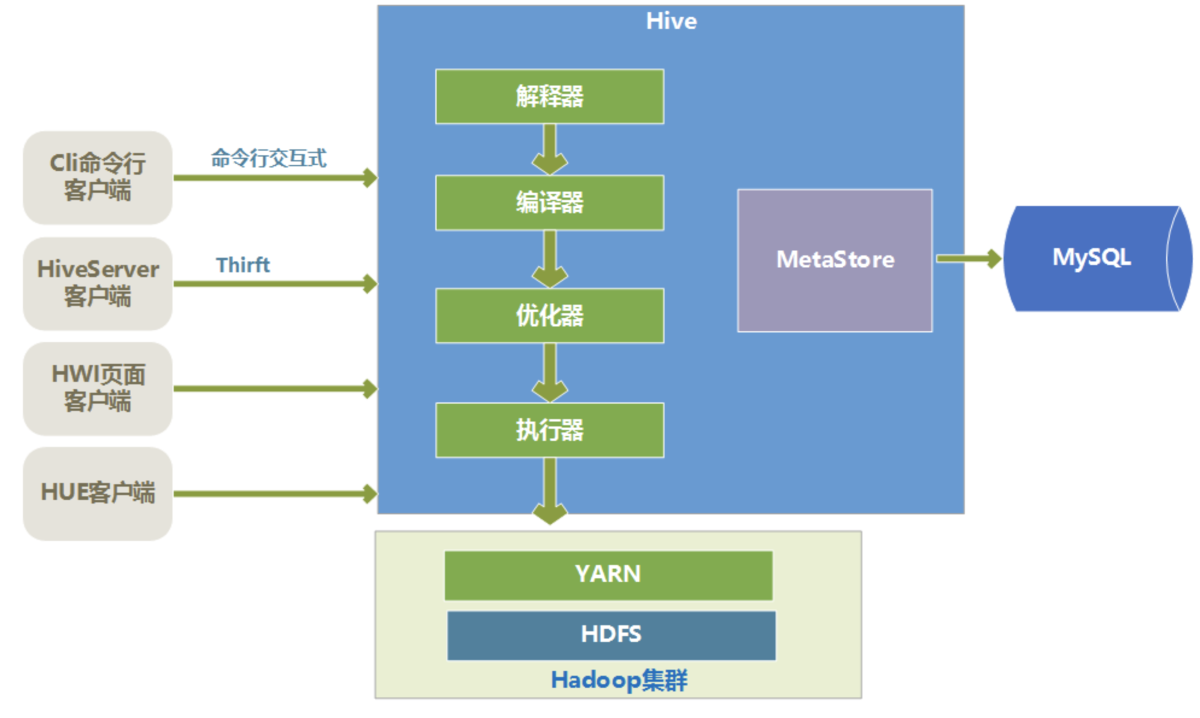
Hive的底层数据是存储在HDFS上的,Hive中的库和表可以看作是对HDFS上数据做的一个映射,所以Hive必须是运行在一个Hadoop集群上的。
3.Hive文件格式
- TEXTFILE。为默认格式,导入数据时会直接把数据文件拷贝到hdfs,行存储。
- SEQUENCEFILE
- RCFILE
- ORCFILE(0.11以后出现)

其中sequencefile是进行二进制格式编码压缩,也是基于行存储,rcfile是基于列存储。
4.行存储与列存储
表:
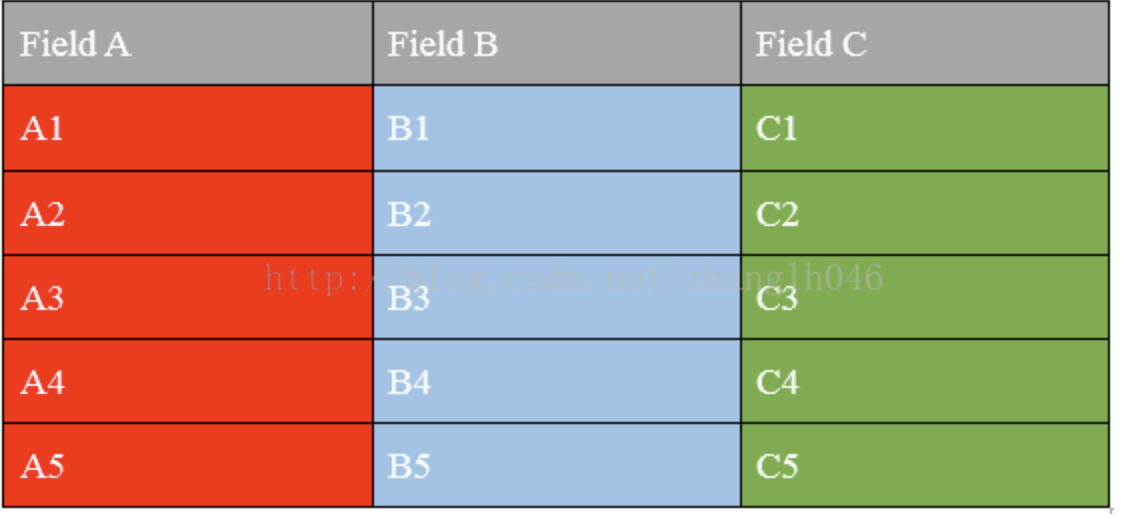
按行存储:
![]()
- 优点:相关的数据是保存在一起,比较符合面向对象的思维,一行数据就是一条记录。这种存储格式比较方便进行INSERT/UPDATE操作。
- 缺点:
- 如果查询只涉及某几个列,它会把整行数据都读取出来,不能跳过不必要的列读取。如果数据量比较大就比较影响性能。
- 由于每一行中,列的数据类型不一致,导致不容易获得一个极高的压缩比,也就是空间利用率不高。
- 不是所有的列都适合作为索引。
按列存储:
![]()
- 优点:
- 查询时,只有涉及到的列才会被查询,不会把所有列都查询出来,即可以跳过不必要的列查询。
- 高效的压缩率,不仅节省储存空间也节省计算内存和CPU。
- 任何列都可以作为索引。
- 缺点:INSERT/UPDATE很麻烦或者不方便;不适合扫描小量的数据。