https://zhuanlan.zhihu.com/p/77307258,这篇写的简直太好了,不愧是阿里啊!
https://www.infoq.cn/article/lteUOi30R4uEyy740Ht2
1.attention计算分为三步
- score-function:打分部分
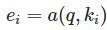
- normalize(alignment function) 对齐部分:
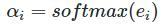
- generate context vector function 生成部分:

又根据key==value这样,分为普通模式和键值对模式:
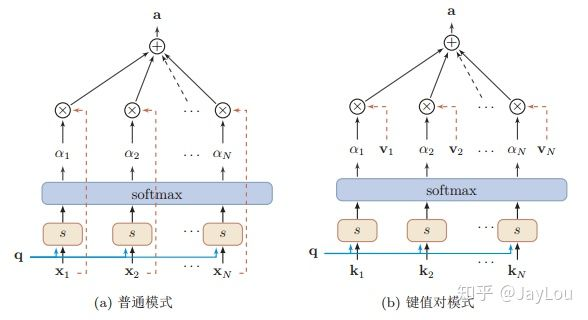
2.score-function不同
也就是计算相似度的方式不同,可以通过点乘/cos相似度/MLP实现
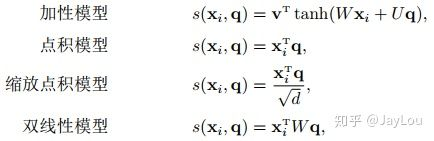
3. alignment function不同
也就是求权重的方式不同,分为global/local attention ,local 是部分输入向量才能进入这个池子。有local-m 和 local-p两个方案。
但好像local增益不大。
4.generate context vector function不同
soft/hard att。
hard attention 是一个随机采样,采样集合是输入向量的集合,采样的概率分布是alignment function 产出的 attention weight。因此,hard attention 的输出是某一个特定的输入向量。
soft attention 是一个带权求和的过程,求和集合是输入向量的集合,对应权重是 alignment function 产出的 attention weight。
硬注意力机制的缺点:

5.并行
RNN 由于递归的本质,导致无法并行。CNN 在 NLP 中扮演了 n-gram 的 detector 角色,在层内可以并行。

它的 perceptive field 是整个句子,所以任意两个位置建立关联是常数时间内的。
没有了递归的限制,就像 CNN 一样可以在每一层内实现并行。
self-attention 借鉴 CNN中 multi-kernel 的思想,进一步进化成为 Multi-Head attention。

关于transform中的上面这个图我看不太懂,是什么意思呢?就maskeddecoder这个部分看不懂。
6.为什么att有用?
是因为它懂得了"context is everything"。
语言模型(language model)是整个 NLP 领域的基础,语言模型的精准程度基本上直接掌握所有 NLP 任务效果的命脉。而 context 又掌握着语言模型的命脉,语义不孤立,在特定 context 下展示特定的一面模型如果可以学习到这些知识,就可以达到见人说人话,见鬼说鬼话的理想状态。
在语义表达上能把 context 用好的都是成功的典范:
- word2vec 靠学习 word 及其 context 发家,
- ELMo-deep contextualized word representations
- BERT 从句子中抠掉一个词用上下文去预测这个词
- transformer-xl 较 transformer 使用更全面的 context 信息
- XLNet 一大重要贡献也是研究如何使用上下文信息来训练语言模型
Attention 背后本质的思想就是:在不同的 context 下,focusing 不同的信息。