1.关于K折交叉验证
https://scikit-learn.org/stable/modules/cross_validation.html#k-fold 只选择最简单的第一个来学习
2折交叉验证:
import numpy as np from sklearn.model_selection import KFold X = ["a", "b", "c", "d",'e','f','g']#当有7个元素时 kf = KFold(n_splits=2) for train, test in kf.split(X): print("%s %s" % (train, test))
分的结果是这样:
[4 5 6] [0 1 2 3] [0 1 2 3] [4 5 6] #有4个元素: [2 3] [0 1] [0 1] [2 3] #8个元素 [4 5 6 7] [0 1 2 3] [0 1 2 3] [4 5 6 7]
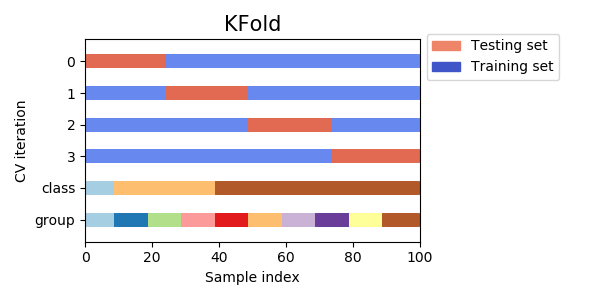
从上面的图片中就很好理解,如果是4折交叉验证的话,那么就是其中有一折,分别做测试和训练集。
但是有疑问的是,如果是在DL代码中,就需要每个epoch建立不同的Dataloader吗?因为需要对fullDataset做分割来形成Train和Test了。
import numpy as np from sklearn.model_selection import KFold X = np.array([[0., 0.], [1., 1.], [-1., -1.], [2., 2.]]) y = np.array([0, 1, 0, 1]) kf=KFold(n_splits=2) for train,test in kf.split(X): X_train, X_test, y_train, y_test = X[train], X[test], y[train], y[test] print(X_train, X_test, y_train, y_test) #下面又说到,它是直接根据下标就可以获取到训练和测试集,因为split的结果就是index
输出:
[[-1. -1.] [ 2. 2.]] [[0. 0.] [1. 1.]] [0 1] [0 1] [[0. 0.] [1. 1.]] [[-1. -1.] [ 2. 2.]] [0 1] [0 1]
2.继续学习Torchtext教程
http://mlexplained.com/2018/02/08/a-comprehensive-tutorial-to-torchtext/
https://blog.csdn.net/nlpuser/article/details/88067167
3.文本数据增强操作
dropout和shuffle??
https://zhuanlan.zhihu.com/p/63182132
包括同义词替换、随机插入、随机交换、随机删除,这样能够使一个句子产生出多个句子,一个句子产生4-8个新句子提升效果明显,而且针对小数据集有用:
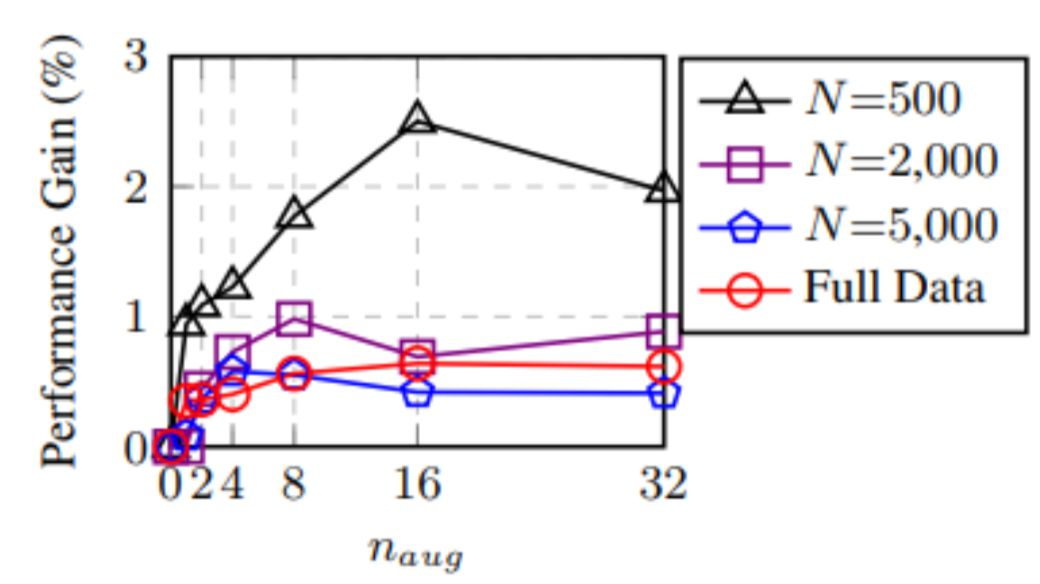
从上图就可以看出,小数据集和大数据集规模分别是什么,低于1000的都算是小数据集 ,高于1000的都算是大的。
代码实现:
def shuffle(self, text): #随机交换 text = np.random.permutation(text.strip().split())#那怎么获取上下文的语义关系??就这样shuffle了? return ' '.join(text) #随机删除 def dropout(self, text, p=0.5):#为啥要随机删除呢? 是数据增强操作??? # random delete some text text = text.strip().split() len_ = len(text) indexs = np.random.choice(len_, int(len_ * p)) for i in indexs: text[i] = '' return ' '.join(text)
4.优达的一个项目
https://ypwhs.github.io/machine-learning/projects/P1_boston_housing/boston_housing.html
下面这个说的就是K折交叉验证:
Q: 优化模型时,使用这种方法对网格搜索有什么好处?
A: 使用 K 折交叉验证能尽可能避免训练集随机分配的偏差导致模型准确度之间的差异,同时还能验证模型的稳健性。5.关于刷题的讨论
https://www.1point3acres.com/bbs/thread-421347-1-1.html
https://posts.careerengine.us/p/5d0a35b1bf24494a034ad99c 这个讲的非常好。
为什么考算法?

6.交叉熵
https://blog.csdn.net/tsyccnh/article/details/79163834
需要自己手推一下才能真正地理解。
从熵到相对熵(KL散度)再到交叉熵,手推一下吧。
5-5日又详细学习了,并做了脑图
3-10————————————
1.pd读取文件转换为array
import pandas as pd a=pd.read_csv('a.txt',header=None) #输出: >>> a.values array([['a'], ['b'], ['c'], ['d']], dtype=object)
多出来的空的换行的不会读进来。
2.mmwrite
??
import pandas as pd from scipy.io import mmwrite a=pd.read_csv('a.txt',sep=' ',header=None) print(a.columns.values) mmwrite('b',a.values)
或者mmwrite('b',a)
结果b文件:
%%MatrixMarket matrix array integer general % 4 2 0 1 0 2 1 0 0 0
a文件:
0 1
1 0
0 0
2 0
出现的问题进行记录,分析:
import pandas as pd from scipy.io import mmwrite,mmread a=pd.read_csv('a.txt',sep=' ',header=None) print(a.columns.values) mmwrite('b',a.values) b=mmread('b.mtx') #如果用b=mmread('b.mtx').T.tocsr().astype('float32')读取 #会出现: #AttributeError: 'numpy.ndarray' object has no attribute 'tocsr' #所以,我猜测是因为a在存储的时候就是以array去存的, >>> a.values array([[0, 1], [1, 0], [0, 0], [2, 0]], dtype=int64) #所以读取的时候也是按array这样纵列去读,这里mmread/mmwrite只相当于普通的存储吧,应该要把a转换为稀疏矩阵形式存储才ok呢。
主要的scipy的https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_matrix.html,有用到变换的地方就可以看看。
from scipy import sparse a=pd.read_csv('a.txt',sep=' ',header=None) asp=sparse.csr_matrix(a.values) #以压缩行的形式 mmwrite('b',asp) b=mmread('b.mtx') #这样: >>> asp <4x2 sparse matrix of type '<class 'numpy.int64'>' with 3 stored elements in Compressed Sparse Row format> #b.mtx %%MatrixMarket matrix coordinate integer general % 4 2 3 1 2 1 2 1 1 4 1 2
3.scipy.sparse 这个讲的还蛮好的!
6.tuple转换为array
原来这么简单,我一直以为是不可跨越的鸿沟呢。。。
a=[([1,2],[6,7]),([3,0],[4,8])] b=np.array(a) >>> b.shape (2, 2, 2) >>> b array([[[1, 2], [6, 7]], [[3, 0], [4, 8]]])
7大大的疑问,pytorch 定义的激活函数层可以重复使用吗 ?
现在我在写的这个有很多线性层,但是我不想写那么多relu层,但是在每个线性层的输出都用了relu激活,不知道是要定义那么多relu还是???
而且模型的结构输出如下:,让我很担心,看起来不像能重复使用的样子。

只有最后才输出了ReLUctant()啊。。。
然后我在官方文档看到了这个:https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-nn/
有问题总要赶快解决嘛!柳暗花明又一村咯~~~
8.sklearn 中 MaxAbsScaler
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MaxAbsScaler.html
>>> from sklearn.preprocessing import MaxAbsScaler >>> X = [[ 1., -1., 2.], ... [ 2., 0., 0.], ... [ 0., 1., -1.]] >>> transformer = MaxAbsScaler().fit(X) >>> transformer MaxAbsScaler() >>> transformer.transform(X) array([[ 0.5, -1. , 1. ], [ 1. , 0. , 0. ], [ 0. , 1. , -0.5]])
非常简单,就是把每一列都/最大值的绝对值就ok了。
2020-5-21更新————————
https://blog.csdn.net/weixin_40683253/article/details/81508321
MaxAbsScaler 是归一化到[-1,1]之间的。