1.pytorch入门学习
这个官方教程还挺好的。可以作为一个手册来查找。
包括创建对象,对象与numpy的互相转换,对象的+操作,对象转移到GPU上。
第二个dataloader的教程学到了可以使用dataloader加载数据,自动完成分batch,shuffle,等工作,首先对每个数据集可以继承DataSet类,然后重写__len__,__getitem__函数。另外数据集还可以加transform,做预处理吧。
2.7日——————————
1.对pytorch首先定义net,定义cirtetion,optimizer;
然后进行forward,pred=net(input),也就是进行预测;
然后loss=cirtetion(pred,label)
然后累计梯度清0optimizer.zero_grad(),然后反向传播loss.backward()
然后更新梯度optimizer.step()
2.torch.nn.NLLLoss
negative log likelihood loss 是指负的log似然损失。
https://blog.csdn.net/geter_CS/article/details/84857220
4.Memory Pinning
https://blog.csdn.net/tsq292978891/article/details/80454568
这个在GPU强大的情况下可以这么设置。
6.晚上对R的学习
1.在概率曲线上,曲线上的点表示什么意思?横轴表示什么意思?
(我目前只知道曲线和x轴的面积为1。
https://www.zhihu.com/question/23237834 在知乎上发现了这个问题:概率密度函数在某一点的值有什么意义?
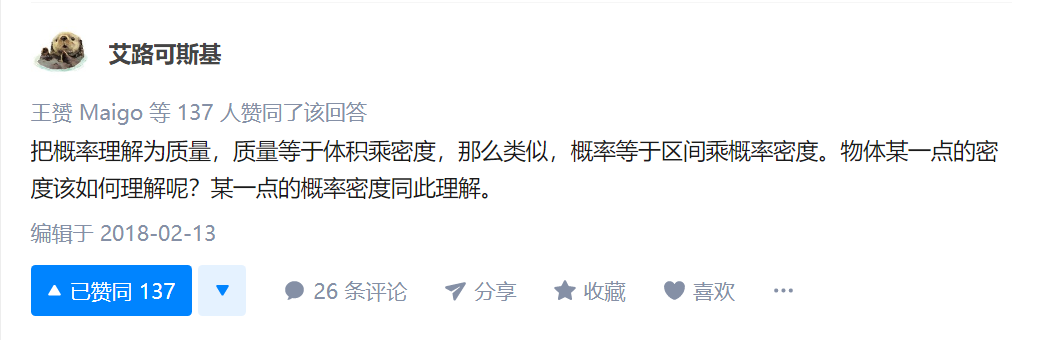
也就是说,对于一个概率密度曲线,横轴就是表示实数本身,而曲线上某一个点(x,y)是表示当前的点在取样时被选中的概率,(错了,这个画线的理解是错的,如果曲线上的点是概率的话,那就大错特错了。)曲线上的某一点就相当于概率密度,一个区间[a,b]之间的面积,就是这个区间内的x轴值被随机选中的概率,那么对于正态分布来说,越靠近μ均值的x值被选中的概率就越大!是这个意思,点没有意义,面积才有意义。
2.对一个分布,如何产生符合分布的值?
https://blog.csdn.net/bitcarmanlee/article/details/82795137从这篇博客当中,我觉得挺神奇的,原来正态分布居然可以从一个均匀分布来模拟:
import numpy as np from pylab import * def sample(): x = np.random.rand() # 两个均匀分布分别为x, y y = np.random.rand() R = np.sqrt(-2 * np.log(x)) theta = 2 * np.pi * y z0 = R * np.cos(theta) #z1 = R * np.sin(theta) return z0 def sampleNtimes(): list = [] n = 100000 for i in range(n): x = sample() list.append(x) y = np.reshape(list, n, 1) hist(y, normed=1, fc='c') # 直方图 x = arange(-4, 4, 0.1) plot(x, 1 / np.sqrt(2 * np.pi) * np.exp(-0.5 * x ** 2), 'g', lw=6) # 标准正态分布 xlabel('x', fontsize = 24) ylabel('p(x)', fontsize = 24) show() sampleNtimes()
由此我就想到,R种生成数据的函数应该和python是一样的,那么我就想查看python中的随机函数,看它是如何实现的,但是非得打开pycharm才能看吗?否则看到的都是说明,而没有源码啊!

在github上搜numpy也没有什么好的结果。算了,打开pycharm。
居然函数只是一个pass。。。好吧

https://blog.codinglabs.org/articles/methods-for-generating-random-number-distributions.html
找到了这个博客,原来想要生成符合分布的随机数是有算法的啊!
Inverse Ttransform和Acceptance-Rejection两种基础算法
虽然没看懂,但是第一次知道有数据生成的算法。所以说,在生成一些数据的时候,符合分布的数据,基本上都使用已经存在的包的函数,而不是自己写一个生成服从某一分布的函数了。