1.在看imputation的样例代码
测试损失是怎么得出来的呢?将X输入进模型,并且预测出了X',那么此时就可以根据loss函数来计算了,包括重建的概率损失,以及隐空间变量和库大小变量的KL散度。
那么imputation它是如何进行的呢?查看代码后我发现了,首先从数据集中加载已经扰乱过的数据:
# zero masked matrix
# corrupted data:

通过扰乱数据训练模型,并且测试数据使用的是原始数据:
# start a new fresh model on a corrupted training set:
![]()
在train_model类中,训练是通过扰乱数据,

其中评估imputed数据是:

这样输入的预测X_zero对应的数据,并且传入原始数据exp_train,以此来计算出填充错误。
我认为是对rate_和exp_train对应的i,j行计算imputed损失。
总之,先使用X_zero训练模型,并给出X_zero的结果,再和原始数据计算L1距离的中值作为损失。
#但是还是难以接受,直接拟合分布,就算数据出现插补也是OK的?难以接受。但是补充不都是以当前数据去补充当前数据吗,没问题的。
2.对cortex的数据集的sv同样进行了分析,发现是一样的道理。
对扰乱数据建立模型,之后会得到扰乱数据的VAE结果,因为之前使用了扰乱数据训练,所以会自动进行填充,然后和原始数据计算error。
3.np.nonzero的例子
import numpy as np x=np.array([1,2,3,0,12,14]).reshape(2,3) print(x) print(np.nonzero(x)) #输出: [[ 1 2 3] [ 0 12 14]] (array([0, 0, 0, 1, 1], dtype=int64), array([0, 1, 2, 1, 2], dtype=int64))
这里输出是两个list,分别指示行和列,一 一对应的关系。
要注意得到的两个list长度是相同的,就是非0元素的个数。
#反应过来之后,感觉真是厉害。
#我还以为输出的直接是(i,j)这样子的。
4.高斯核密度估计
https://blog.csdn.net/unixtch/article/details/78556499 (待看)
5.负对数似然
https://blog.csdn.net/silver1225/article/details/88914652 (待看)
7.接下来看差异表达分析!
假设检验什么的我最不明白了。
差异表达分析应该是对不同的细胞类型来说的吧?这篇文章的意思是直接对表达矩阵建模???
不的,是对不同的细胞类型找出DE基因的。
![]()
尝试理解这两个假设检验的例子:
fw函数是计算每个cell中细胞的表达占比,是通过softmax层输出的,那这里fgw是针对其中一个gene,
#那这里的s是对当前cell所标识的batch,还是对所有的batch呢?我目前认为是前者。但是后者也有可能,是它忽略了batch,因为就算不同的batch也有可能是相同的cell类型。
如果对所有batch来说,当前gene的均值在当前细胞类型za中 大于 另一cell类型,那么就接受原假设,当前g是差异表达基因,反之如果≤就不是???
Es是根据经验频率得出的。
#明白了一点,它不需要校正细胞的批次,而是对Es这样求期望,就忽略批次,而能够得出差异表达的gene。
8.转录组差异表达分析
https://www.jianshu.com/p/5f94ae79f298似乎也没什么用。
但是这本书讲的也太抽象了。
10.贝叶斯假设检验
https://blog.csdn.net/jackxu8/article/details/70332331
下载了《贝叶斯统计》的教材,看了一下贝叶斯假设检验的例子。
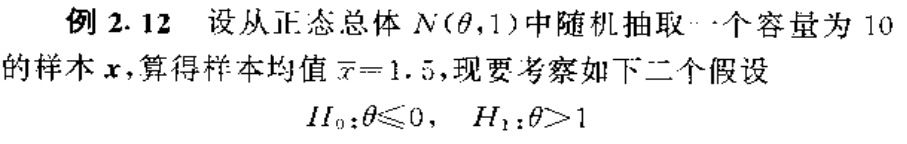


贝叶斯假设检验的总体步骤:

总之要计算原假设的后验概率和备择假设的后验概率,然后求二者之商。
11.对后验积分的理解
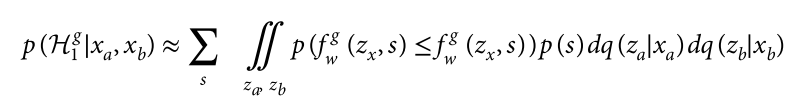
左边是原假设的后验概率,右边是对所有批次的类别细胞,za和zb应该是两个不同的cluster的,首先对于一个za,
p(s)是每个批次中的细胞相对丰度。#目前还对这个公式啥意思完全不明白。
对每一个基因g和细胞对(za,zb),观测到的基因表达为(xa,xb)并且批ID为(sa,sb)。
12.搜索关键字“贝叶斯检验 差异表达”,结果不佳。
13.通过在给的实验说明中,理解了一点:
从训练有素的VAE模型中,我们可以采样每个细胞中每个基因的基因表达率。 然后,对于两个感兴趣的种群,我们可以从每个种群中随机抽取一对细胞,以比较它们在一个基因中的表达率。 差异表达的程度通过logit(p /(1-p))进行度量,其中p是种群A中的细胞表达高于种群B中的细胞的概率。我们可以形成DE值的零分布 通过从组合人口中随机抽取配对。
上面所说的p就是原假设H1。
再看basic教程,讲解如何确定DE基因,首先选定感兴趣的细胞类型。