1.决定再重新读一遍sv论文。
4.中位数
https://blog.csdn.net/zhang20072844/article/details/13372753
https://blog.csdn.net/z84616995z/article/details/18909475
5.贝叶斯因子https://www.zhihu.com/question/29620591

6.Benjamini-Hochberg Procedure
https://wenku.baidu.com/view/fcc64d9af61fb7360b4c6575.html
7.读完了似乎也并没有什么新的理解啊。
8.缺失值处理汇总。一直对impute这个单词的意思都不太理解,你应该早就直接百度数据impute,能够出现好多相关的博客啊,你就一直用网易翻译查看单词的意思,然后就被迷惑了。。。不懂的别瞎猜,多百度。
https://www.jianshu.com/p/90220f34f9d5
一般的处理缺失值的方法:
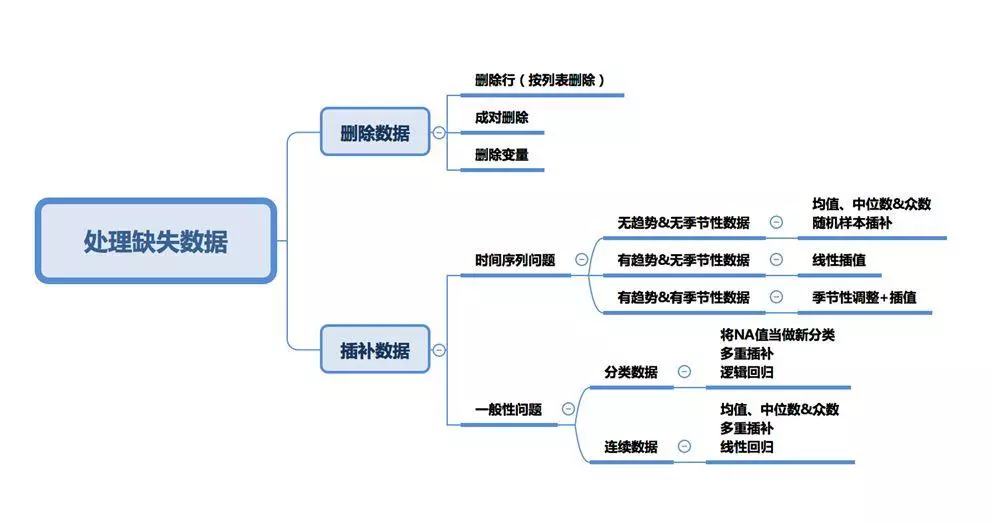
https://www.cnblogs.com/tecdat/p/11776029.html R中的插补(想法:其中介绍了不少插补的方法,比如说随机森林之类的看起来十分高大上,我也可以借来尝试一下解决问题。不就是代码吗....努力一下写一写。)
9.sklearn中有个imputer类直接可以直接对数据补充,但是我不明白为什么要fit呢?
https://blog.csdn.net/weixin_39541558/article/details/80627199
import numpy as np from sklearn.preprocessing import Imputer ###1.使用均值填充缺失值 imp = Imputer(missing_values='NaN', strategy='mean', axis=0) print(imp.fit([[1, 2], [np.nan, 3], [7, 6]])) X = [[np.nan, 2], [6, np.nan], [7, 6]] print(imp.transform(X)) #以下为输出 Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0) [[4. 2. ] [6. 3.66666667] [7. 6. ]]
https://www.cnblogs.com/chaosimple/p/4153158.html 这个讲的比较清楚,先用fit拟合一个矩阵,之后用它的均值去给后来transform的矩阵进行填充。
可以选择均值/中位数/众数填充。
#原来需要一个基准的矩阵啊,我还以为是直接对一个矩阵求它的行和列就OK了,那应该在不同的方法中,可能处理的方法不同吧?(个人看法)
#但是如果是在sc中,如何进行呢?忽然想到了,那就用X去fit,然后再transformX就可以啦,就可以自动用本矩阵填充了。
#明天继续加油哦,如果睡不着的话,那就继续起来学。。