转自:https://blog.csdn.net/u010626937/article/details/72896144#commentBox
1.Python的机器学习包sklearn中也包含了感知机学习算法,我们可以直接调用,因为感知机算法属于线性模型,所以从sklearn.linear_model中import下面给出例子。
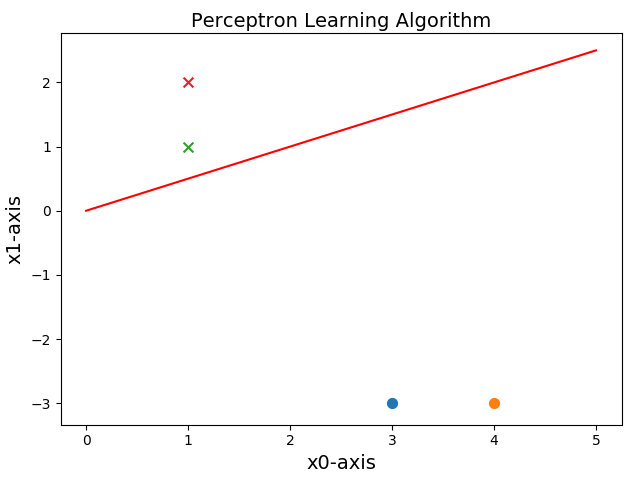
import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import Perceptron #创建数据,直接定义数据列表 def creatdata1(): samples=np.array([[3,-3],[4,-3],[1,1],[1,2]]) labels=np.array([-1,-1,1,1]) return samples,labels def MyPerceptron(samples,labels): #定义感知机 clf=Perceptron(fit_intercept=True,n_iter=30,shuffle=False) #训练感知机 clf.fit(samples,labels) #得到权重矩阵 weigths=clf.coef_ #得到截距bisa bias=clf.intercept_ return weigths,bias #画图描绘 class Picture: def __init__(self,data,w,b): self.b=b self.w=w plt.figure(1) plt.title('Perceptron Learning Algorithm',size=14) plt.xlabel('x0-axis',size=14) plt.ylabel('x1-axis',size=14) xData=np.linspace(0,5,100) yData=self.expression(xData) plt.plot(xData,yData,color='r',label='sample data') plt.scatter(data[0][0],data[0][1],s=50) plt.scatter(data[1][0],data[1][1],s=50) plt.scatter(data[2][0],data[2][1],s=50,marker='x') plt.scatter(data[3][0],data[3][1],s=50,marker='x') plt.savefig('3d.png',dpi=75) def expression(self,x): y=(-self.b-self.w[:,0]*x)/self.w[:,1] return y def Show(self): plt.show() if __name__ == '__main__': samples,labels=creatdata1() weights,bias=MyPerceptron(samples,labels) print ('最终训练得到的w和b为:',weights,',',bias) Picture=Picture(samples,weights,bias) Picture.Show()
其中:
Perceptron fit_intercept : bool Whether the intercept should be estimated or not. If False, the data is assumed to be already centered. Defaults to True. #是否应该估计截距,如果是False则认为数据是被中心化过的(减去过均值)。默认是True #也就是说如果是False,则b=0 shuffle : bool, optional, default True Whether or not the training data should be shuffled after each epoch. #一个epoch应该是对所有的数据处理一遍 #每次处理之后是否打乱原有数据的顺序 n_iter : int, optional The number of passes over the training data (aka epochs). Defaults to None. Deprecated, will be removed in 0.21. .. versionchanged:: 0.19 Deprecated #这个真是不太明白是什么意思。
运行结果:
最终训练得到的w和b为: [[-2. 4.]] , [0.] DeprecationWarning: n_iter parameter is deprecated in 0.19 and will be removed in 0.21. Use max_iter and tol instead. DeprecationWarning)