drf(八)—分页
说明:分页的原理与数据库中的 limit 截取相关,也涉及limit offset的使用,内部原理相似,但是rest_framework中封装了应用函数。
分页基类
class BasePagination:
display_page_controls = False
def paginate_queryset(self, queryset, request, view=None): # pragma: no cover
raise NotImplementedError('paginate_queryset() must be implemented.')
def get_paginated_response(self, data): # pragma: no cover
raise NotImplementedError('get_paginated_response() must be implemented.') # 自动生成页码,并将对象进行序列化的操作。
def get_paginated_response_schema(self, schema):
return schema
def to_html(self): # pragma: no cover
raise NotImplementedError('to_html() must be implemented to display page controls.')
def get_results(self, data):
return data['results']
def get_schema_fields(self, view):
assert coreapi is not None, 'coreapi must be installed to use `get_schema_fields()`'
return []
def get_schema_operation_parameters(self, view):
return []
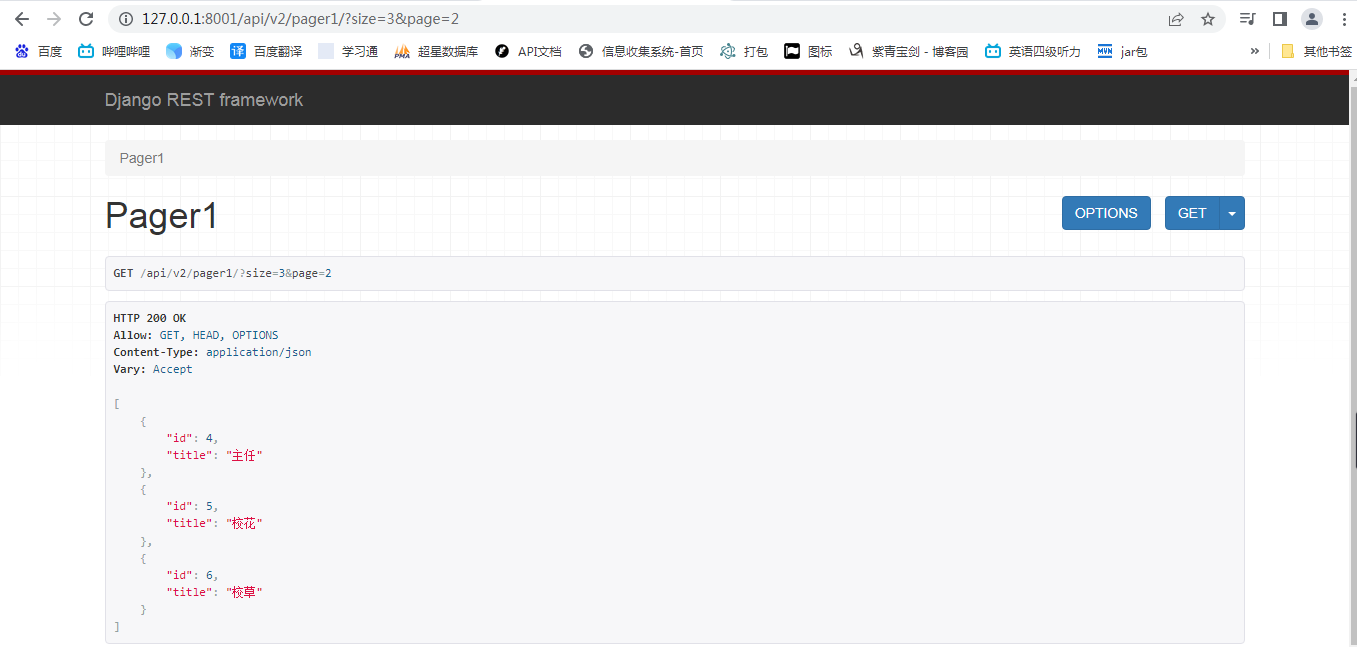
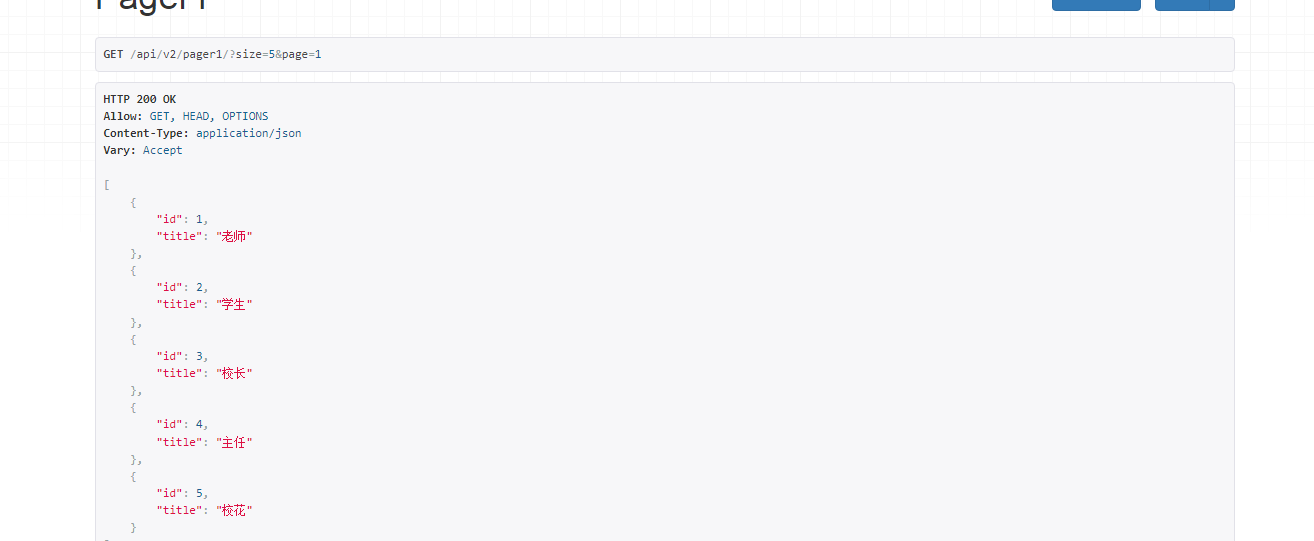
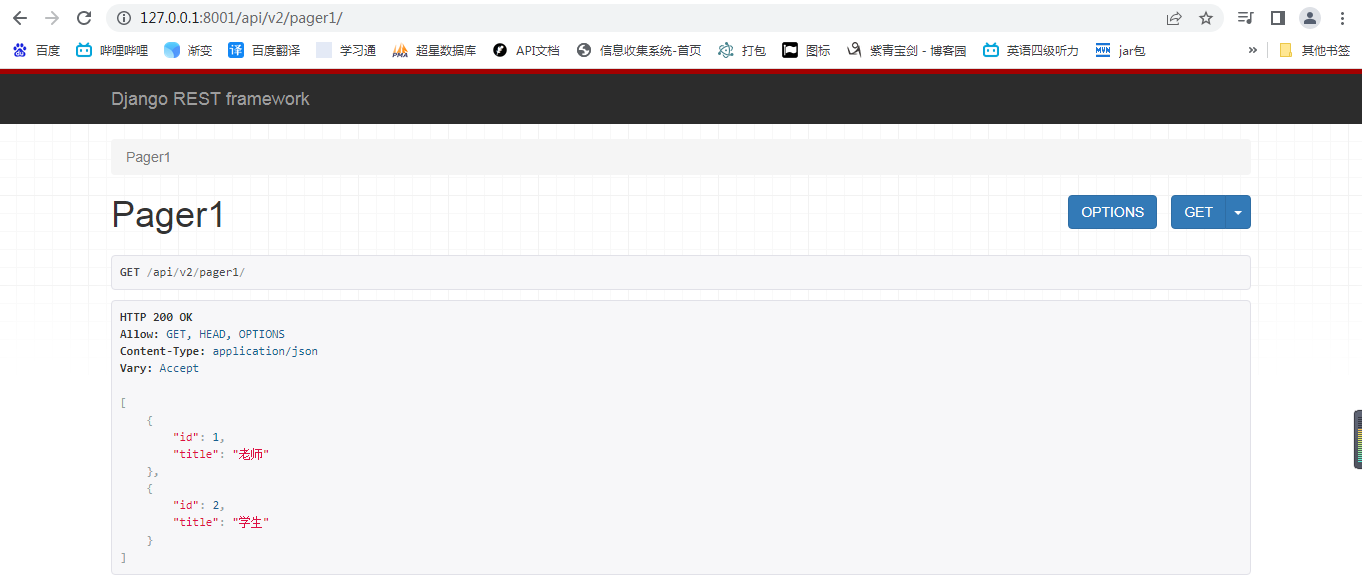
1.普通的参数分页
class MyPageNumberPagination(PageNumberPagination):
page_size = 2 # 每页显示多少条数据
page_query_param = 'page'
page_size_query_param = 'size' # 路由中增加参数
max_page_size = 5 #
class Pager1View(APIView):
def get(self,request,*args,**kwargs):
roles=models.Role.objects.all()
# 创建分页对象
pg=MyPageNumberPagination()
# 在数据库中获取分页数据
pager_roles=pg.paginate_queryset(queryset=roles,request=request,view=self)
# 对数据进行序列化,将分页数据进行序列化
ser=RoleSerializers(instance=pager_roles,many=True)
# 使用渲染器进行放回
return Response(ser.data)
内部源码
class PageNumberPagination(BasePagination):
page_size = api_settings.PAGE_SIZE # 可以去配置文件中读取,但是一般只是在子类中配置
django_paginator_class = DjangoPaginator
# Client can control the page using this query parameter.
page_query_param = 'page'
page_query_description = _('A page number within the paginated result set.')
# Client can control the page size using this query parameter.
# Default is 'None'. Set to eg 'page_size' to enable usage.
page_size_query_param = None
page_size_query_description = _('Number of results to return per page.')
# Set to an integer to limit the maximum page size the client may request.
# Only relevant if 'page_size_query_param' has also been set.
max_page_size = None
last_page_strings = ('last',)
template = 'rest_framework/pagination/numbers.html'
invalid_page_message = _('Invalid page.')
def paginate_queryset(self, queryset, request, view=None):
page_size = self.get_page_size(request)
if not page_size:
return None
paginator = self.django_paginator_class(queryset, page_size)
page_number = self.get_page_number(request, paginator)
try:
self.page = paginator.page(page_number)
except InvalidPage as exc:
msg = self.invalid_page_message.format(
page_number=page_number, message=str(exc)
)
raise NotFound(msg)
if paginator.num_pages > 1 and self.template is not None:
# The browsable API should display pagination controls.
self.display_page_controls = True
self.request = request
return list(self.page)
自定义的字段主要使用在上述使用的参数。
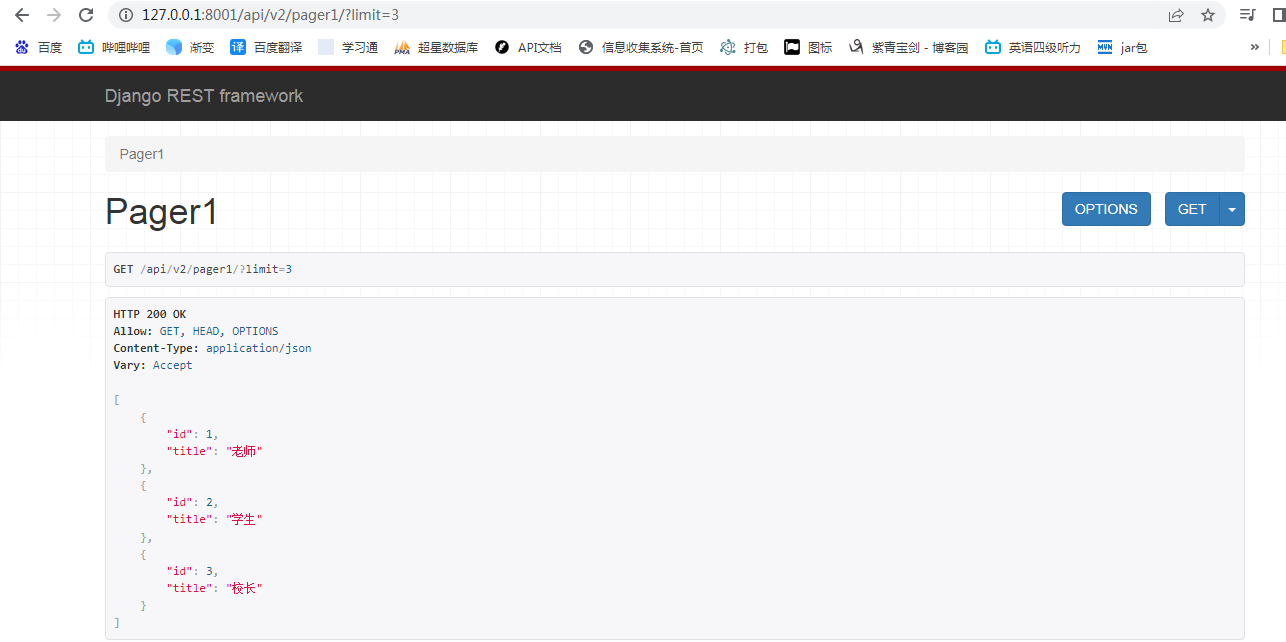
2. limit 分页
class MyLimitOffsetPagination(LimitOffsetPagination):
default_limit = 2
limit_query_param = 'limit'
offset_query_param = 'offset'
max_limit = 4
源码:
class LimitOffsetPagination(BasePagination):
default_limit = api_settings.PAGE_SIZE
limit_query_param = 'limit'
limit_query_description = _('Number of results to return per page.')
offset_query_param = 'offset'
max_limit = None
超出索引范围。只显示最大的条数。
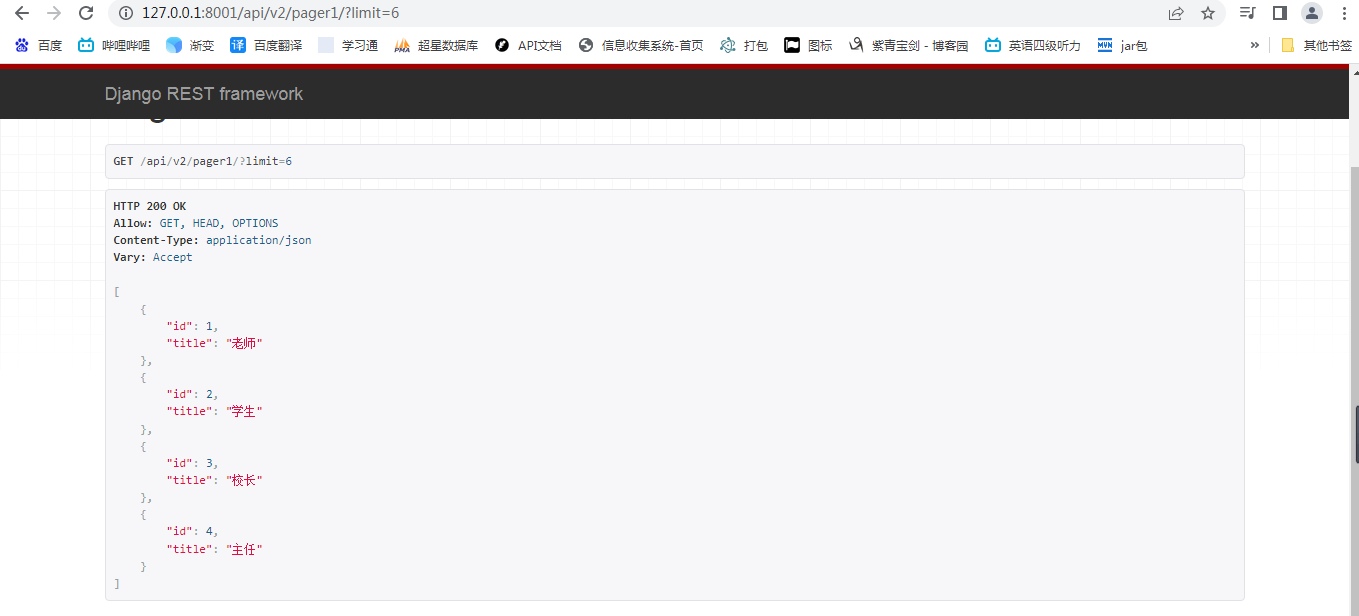
传入 offset 参数,从 offset 位置后取出 limit 条数据;
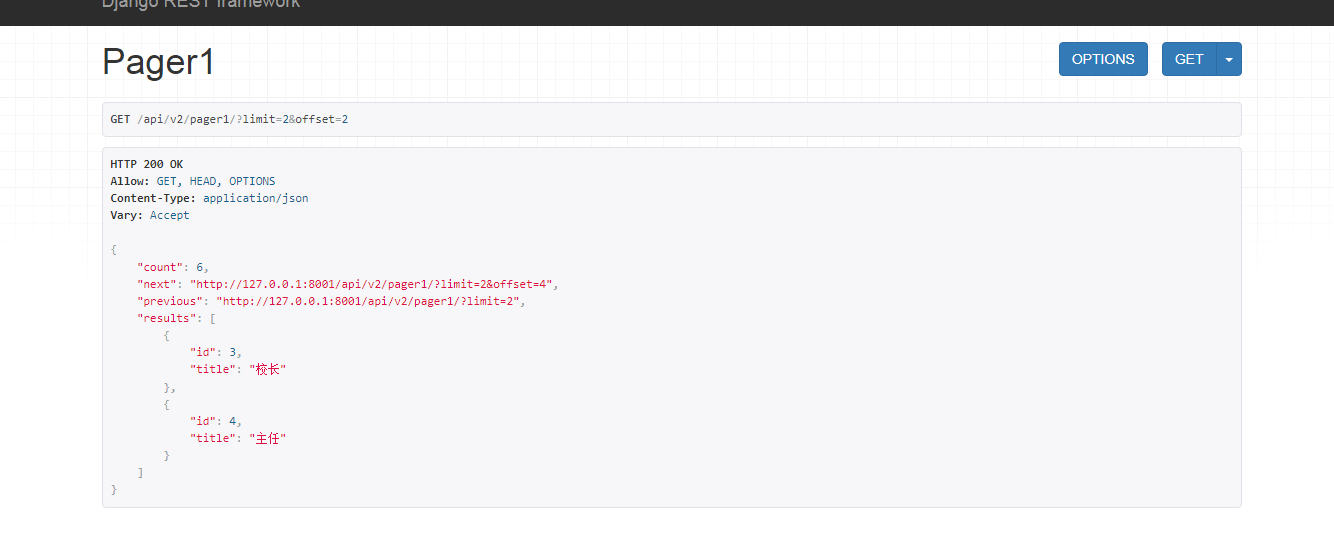
调用生成url的方法也可以生成下一页的url连接。
3.生成安全页码的分页
说明:生成页码的功能其他类也有,只是安全页码的功能,页码参数是加密字符串。
class MyCursorPagination(CursorPagination):
cursor_query_param = 'cursor'
page_size = 2
ordering = 'id' # 排序规则,'-id'则会修改为倒叙
page_size_query_param = None
max_page_size = None
视图函数:
class Pager1View(APIView):
def get(self,request,*args,**kwargs):
roles=models.Role.objects.all()
# 创建分页对象
# pg=MyPageNumberPagination()
# pg=MyLimitOffsetPagination()
pg=MyCursorPagination()
# 在数据库中获取分页数据
pager_roles=pg.paginate_queryset(queryset=roles,request=request,view=self)
# 对数据进行序列化,将分页数据进行序列化
ser=RoleSerializers(instance=pager_roles,many=True)
# 使用渲染器进行放回
# return Response(ser.data)
# 使用方语句生成页码
return pg.get_paginated_response(ser.data)
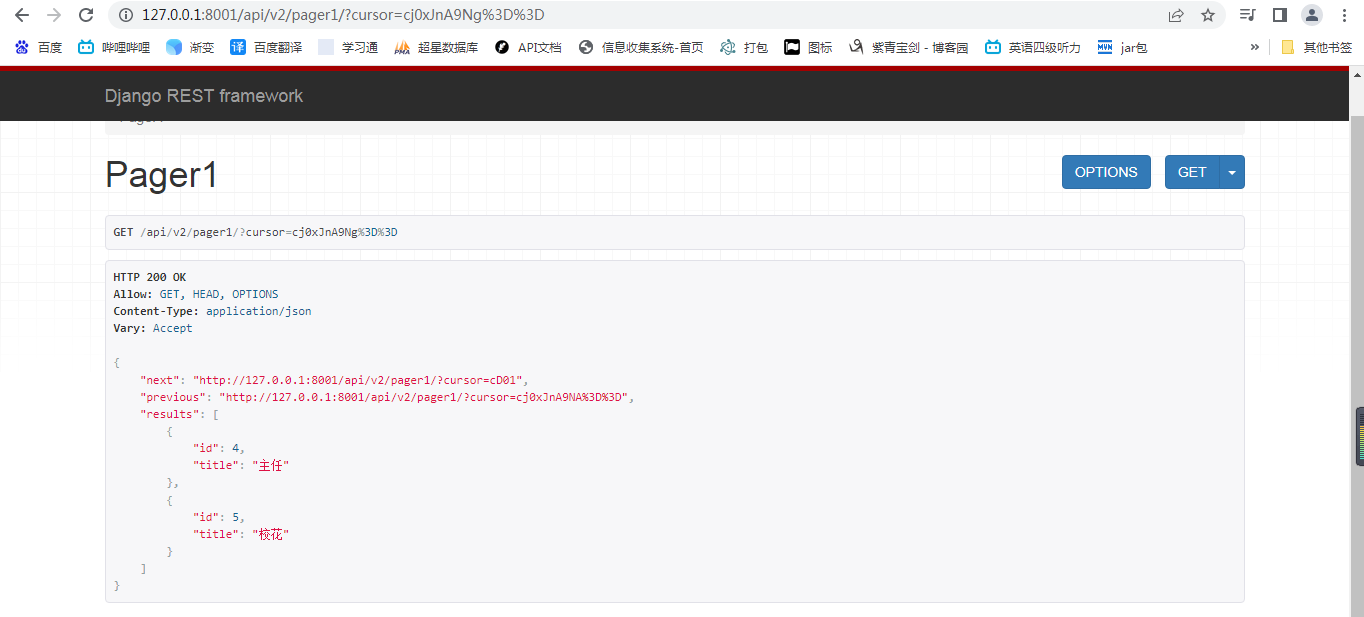
页码参数cursor也是加密字符。
原理与数据库分页相关,数量巨大的时候与数据库的性能也相关;
继续努力,终成大器;