整个爬虫是基于selenium和Python来运行的,运行需要的包
1 mysql,matplotlib,selenium
需要安装selenium火狐浏览器驱动,百度的搜寻。
整个爬虫是模块化组织的,不同功能的函数和类放在不同文件中,最后将需要配置的常量放在constant.py中
项目地址:github(点击直达)
整个爬虫的主线程是Main.py文件,在设置好constant.py后就可以直接运行Main.py
从主线分析
Main.py
1 # /bin/python 2 # author:leozhao 3 # author@email: dhzzy88@163.com 4 5 """ 6 这是整个爬虫系统的主程序 7 """ 8 import numpy as np 9 10 import dataFactory 11 import plotpy 12 import sqlDeal 13 import zhilian 14 from Constant import JOB_KEY 15 16 # 17 # 启动爬虫程序 18 zhilian.spidefmain(JOB_KEY) 19 20 """ 21 爬取数据结束后对数据可视化处理 22 """ 23 # 从数据库读取爬取的数据 24 # 先得到的是元组name,salray,demand,welfare 25 26 value = sqlDeal.sqlselect() 27 # 工资上限,下限,平均值 28 updata = np.array([], dtype=np.int) 29 downdata = np.array([], dtype=np.int) 30 average = np.array([], dtype=np.int) 31 for item in value: 32 salray = dataFactory.SarayToInt(item[1]) 33 salray.slove() 34 updata = np.append(updata, salray.up) 35 downdata = np.append(downdata, salray.down) 36 average = np.append(average, (salray.up + salray.down) / 2) 37 38 # 工资上下限 39 average.sort() 40 41 # 匹配城市信息 暂时还未实现 42 43 # 统计信息 44 # 两种图形都加载出来 方便查看 45 plotpy.plotl(average) 46 plotpy.plots(average) 47 48 print(average, average.sum()) 49 print("平均工资:", average.sum() / len(average)) 50 print("最高:", average.max()) 51 print("最低", average.min()) 52 print("职位数", len(average)) 53 54 # 画图
基本是以爬虫整个执行流程来组织的
从功能文件中导入zhilian.py
1 # /bin/python 2 # author:leo 3 # author@email : dhzzy88@163.com 4 from selenium import webdriver 5 from selenium.webdriver.common.by import By 6 from selenium.webdriver.common.keys import Keys 7 from selenium.webdriver.support import expected_conditions as EC 8 from selenium.webdriver.support.ui import WebDriverWait 9 10 import sqlDeal 11 from Constant import PAGE_NUMBER 12 13 14 def init(key="JAVA"): 15 # 智联招聘的主页搜索关键字,初始化到采集页面 16 url = "https://www.zhaopin.com/" 17 opt = webdriver.FirefoxOptions() 18 opt.set_headless() #设置无头浏览器模式 19 driver = webdriver.Firefox(options=opt) 20 driver.get(url) 21 driver.find_element_by_class_name("zp-search-input").send_keys(key) 22 # driver.find_element_by_class_name(".zp-search-btn zp-blue-button").click() 23 driver.find_element_by_class_name("zp-search-input").send_keys(Keys.ENTER) 24 import time 25 time.sleep(2) 26 all = driver.window_handles 27 driver.switch_to_window(all[1]) 28 url = driver.current_url 29 return url 30 31 32 class ZhiLian: 33 34 def __init__(self, key='JAVA'): 35 # 默认key:JAVA 36 indexurl = init(key) 37 self.url = indexurl 38 self.opt = webdriver.FirefoxOptions() 39 self.opt.set_headless() 40 self.driver = webdriver.Firefox(options=self.opt) 41 self.driver.get(self.url) 42 43 def job_info(self): 44 45 # 提取工作信息 可以把详情页面加载出来 46 job_names = self.driver.find_elements_by_class_name("job_title") 47 job_sarays = self.driver.find_elements_by_class_name("job_saray") 48 job_demands = self.driver.find_elements_by_class_name("job_demand") 49 job_welfares = self.driver.find_elements_by_class_name("job_welfare") 50 for job_name, job_saray, job_demand, job_welfare in zip(job_names, job_sarays, job_demands, job_welfares): 51 sqlDeal.sqldeal(str(job_name.text), str(job_saray.text), str(job_demand.text), str(job_welfare.text)) 52 53 # 等待页面加载 54 print("等待页面加载") 55 WebDriverWait(self.driver, 10, ).until( 56 EC.presence_of_element_located((By.CLASS_NAME, "job_title")) 57 ) 58 59 def page_next(self): 60 try: 61 self.driver.find_elements_by_class_name("btn btn-pager").click() 62 except: 63 return None 64 self.url = self.driver.current_url 65 return self.driver.current_url 66 67 68 def spidefmain(key="JAVA"): 69 ZHi = ZhiLian(key) 70 ZHi.job_info() 71 # 设定一个爬取的页数 72 page_count = 0 73 while True: 74 ZHi.job_info() 75 ZHi.job_info() 76 page_count += 1 77 if page_count == PAGE_NUMBER: 78 break 79 # 采集结束后把对象清除 80 del ZHi 81 82 83 if __name__ == '__main__': 84 spidefmain("python")
这是调用selenium模拟浏览器加载动态页面的程序,整个爬虫的核心都是围绕这个文件来进行的。
每爬取一页信息以后就把解析的数据存储到数据库里,数据库处理函数的定义放在另外一个文件里,这里只处理加载和提取信息的逻辑
将数据存入本机的mysql数据库
1 # /bin/python 2 # author:leozhao 3 # author@email :dhzzy88@163.com 4 5 import mysql.connector 6 7 from Constant import SELECT 8 from Constant import SQL_USER 9 from Constant import database 10 from Constant import password 11 12 13 def sqldeal(job_name, job_salray, job_demand, job_welfare): 14 conn = mysql.connector.connect(user=SQL_USER, password=password, database=database, use_unicode=True) 15 cursor = conn.cursor() 16 infostring = "insert into zhilian value('%s','%s','%s','%s')" % ( 17 job_name, job_salray, job_demand, job_welfare) + ";" 18 cursor.execute(infostring) 19 conn.commit() 20 conn.close() 21 22 23 def sqlselect(): 24 conn = mysql.connector.connect(user=SQL_USER, password=password, database=database, use_unicode=True) 25 print("连接数据库读取信息") 26 cursor = conn.cursor() 27 28 cursor.execute(SELECT) 29 values = cursor.fetchall() 30 conn.commit() 31 conn.close() 32 return values
两个函数
第一个负责存入数据
第二个负责读取数据
读取数据以后在另外的类中处理得到的数据
例如10K-20K这样的信息,为可视化做准备
# /bin/python # author:leozhao # author@email : dhzzy88@163.com import matplotlib.pyplot as plt import numpy as np from Constant import JOB_KEY # 线型图 def plotl(dta): dta.sort() print("dta", [dta]) num = len(dta) x = np.linspace(0, num - 1, num) print([int(da) for da in dta]) print(len(dta)) plt.figure() line = plt.plot(x, [sum(dta) / num for i in range(num)], dta) # plt.xlim(0, 250) plt.title(JOB_KEY + 'Job_Info') plt.xlabel(JOB_KEY + 'Job_Salray') plt.ylabel('JobNumbers') plt.show() # 条形图 def plots(dta): fig = plt.figure() ax = fig.add_subplot(111) ax.hist(dta, bins=15) plt.title(JOB_KEY + 'Job_Info') plt.xlabel(JOB_KEY + 'Job_Salray') plt.ylabel('JobNumbers') plt.show()
最后将得到的数据放入在画图程序中画图
最后计算相关数据
在爬取过程中及时将数据存入数据库,减少虚拟机内存的占比。
下面放上数据结果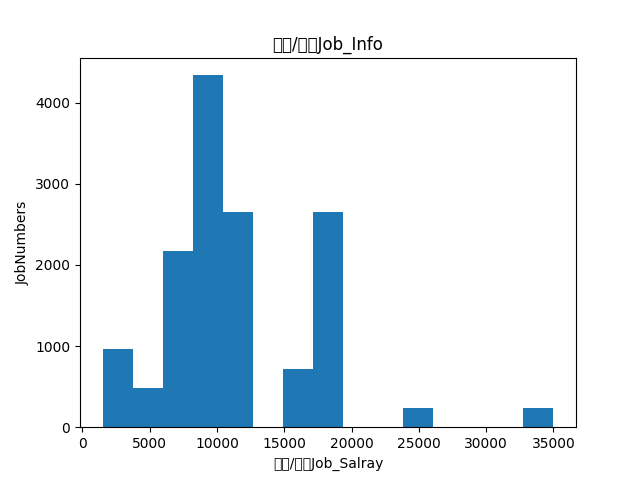
上面是金融的工作的薪酬调查
下面是材料科学的薪酬调查
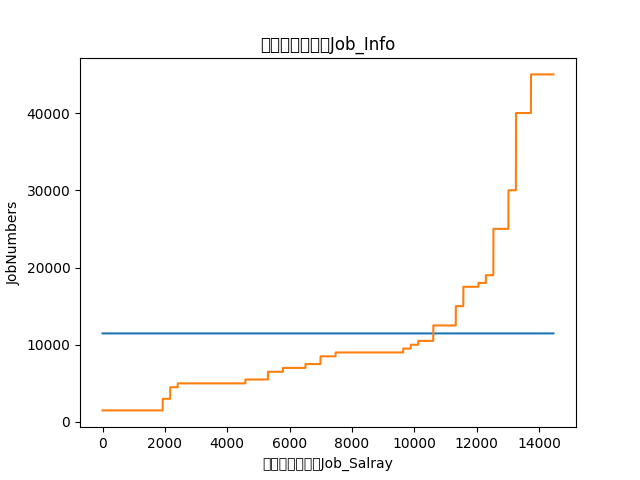
蓝色为平均工资。
注意在平均线以上的基本为博士和硕士的学历要求。
具体的数据处理没时间弄,有时间再做。