论文信息
论文标题:Supervised Contrastive Learning with Structure Inference for Graph Classification
论文作者:Hao Jia, Junzhong Ji, Minglong Lei
论文来源:2022, ArXiv
论文地址:download
论文代码:download
Abstract
任务:Graph Classification
-
- Node classification,从局部邻居获得的节点表示向量 可以直接用于获得节点标签。
$\begin{array}{l}a_{v}^{(k)}=\operatorname{AGGREGATE}^{(k)}\left(\left\{h_{u}^{(k-1)}: u \in \mathcal{N}(v)\right\}\right) \\h_{v}^{(k)}=\operatorname{COMBINE}^{(k)}\left(h_{v}^{(k-1)}, a_{v}^{(k)}\right)\end{array}$
-
- Graph classification,需要获得不同层次的图结构信息, 从而获得具有判别性的图表示向量。
$h_{G}=\operatorname{READOUT}\left(\left\{h_{v}^{(K)} \mid v \in G\right\}\right)$
背景知识
-
- 从当前节点以相同概率选择邻居节点进行游走;
- 每个随机游走序列的长度为 $k$ ;
- 对图中每个节点生成 $r$ 个随机游走序列;
随机游走产生的问题
-
- 不稳定,当采样频率或节点序列数目发生改变。
- 在带有高度偏见的网络中,随机游走倾向于度高 的节点,从而忽略了全局信息。
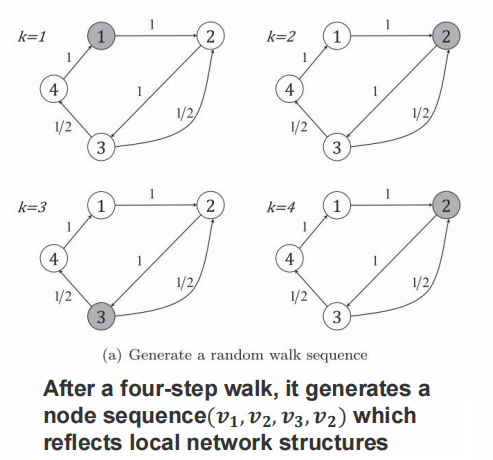
先前工作存在的问题
图对比学习方面:图上广泛使用的框架常是自监督形式,该类框架的对比损失基于 一个正样本与一个负样本对比或一个正样本与多个负样本对比 ,这导致了对比能力有限。
InfoNCE Loss
$\mathcal{L}_{N}=-\mathbb{E}_{X}\left[\log \frac{\overline{\exp \left(f(x)^{T} f\left(x^{+}\right)\right)}}{\underline{\exp \left(f(x)^{T} f\left(x^{+}\right)\right)}+\sum_{j=1}^{N-1} \exp \left(f(x)^{T} f\left(x_{j}\right)\right)}\right]$
最小化这一损失能够最大化锚点数据和正样本互信息的下界,加大互信息。
介绍
本文工作
● 首先,开发了一种新的图增强策略来探索图中的全局结构。
○ 关键思想是模拟扩散过程,对被称为 cascade 的有序节点序列进行采样,然后利用结构推 理(structure inference)从 cascade 中恢复图。
○ 好处:
① 结构推理过程中考虑了图内对比信息,使学习到的图结构在全局视图中具有更强的鉴 别能力;
② 与以前的方法相比,构建了一个优化问题,以数据驱动的方式构造增广图,其中不需 要先验;
● 其次,为提高对比能力,提出使用一个监督对比损失来代替原来的自监督损失,进一步利用 标签信息来改进图的对比学习。
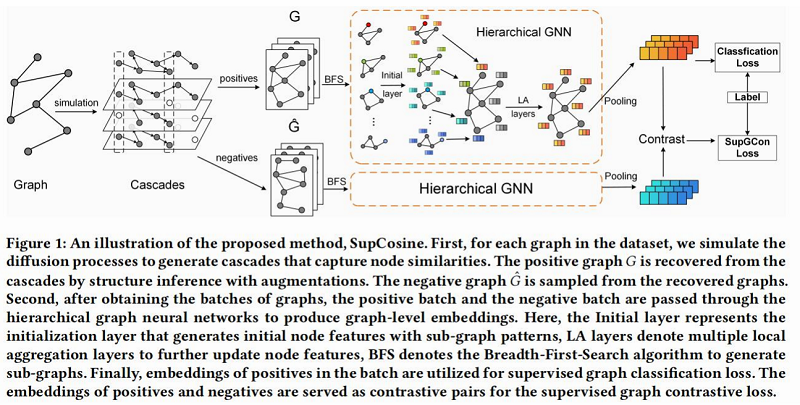
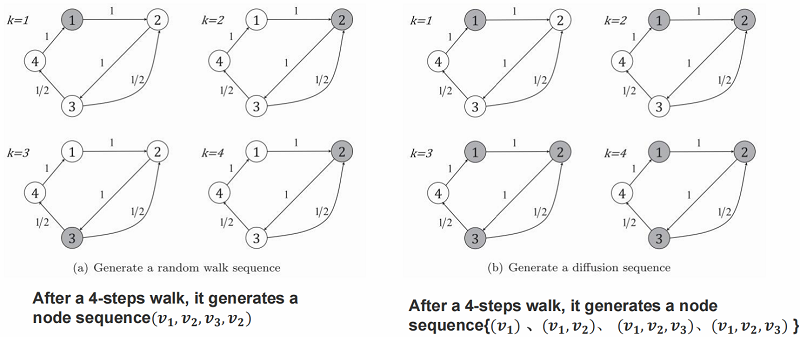
随机游走和扩散过程对比:
方法
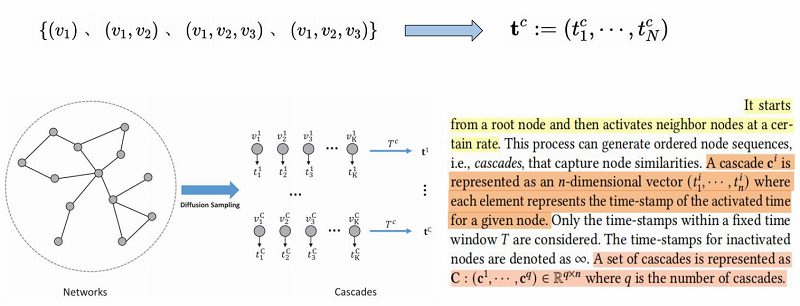
为什么引入 Cascades?
● 相似性假设:在同一 Cascade 中同时出现的节点具有更高的相似性,从而在增强图中具有更高的连接概率。
Positive graph
● The positive graph $G$ is recovered from the cascades by structure inference with augmentations.
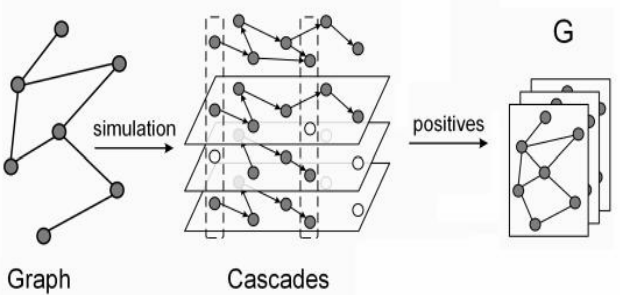











算法流程图
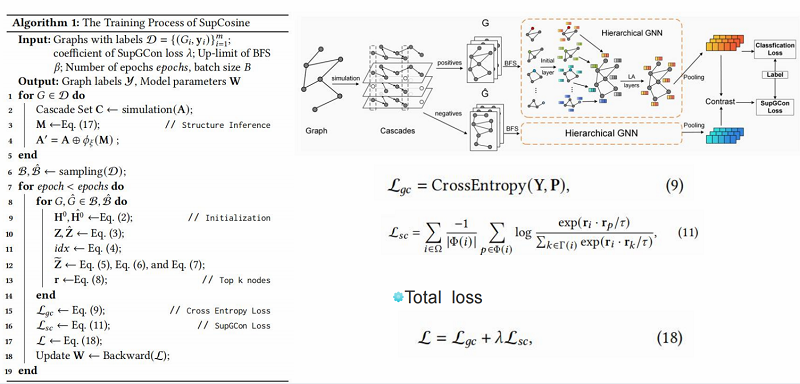
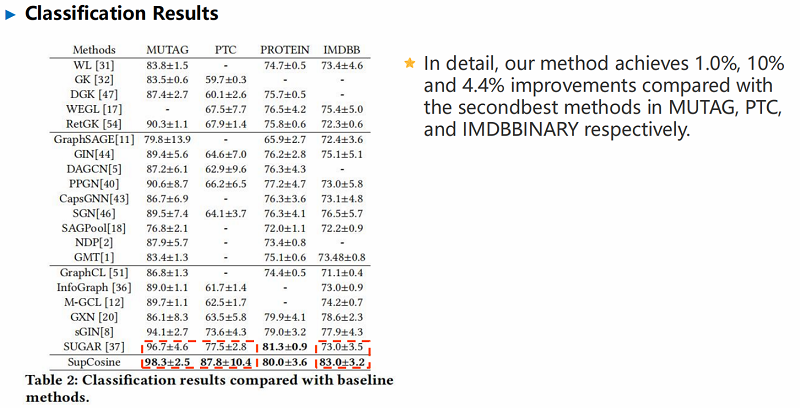
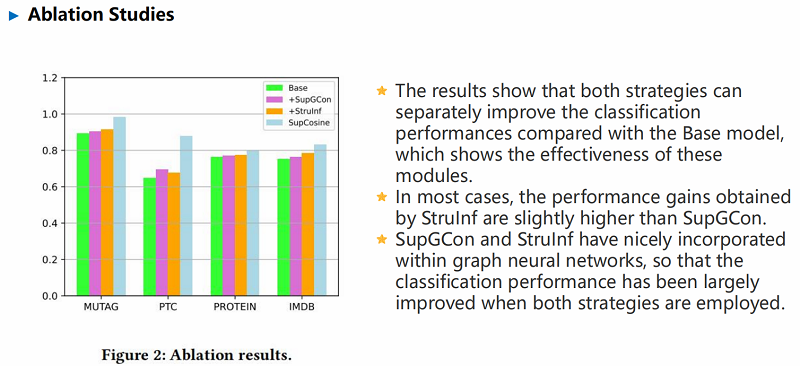
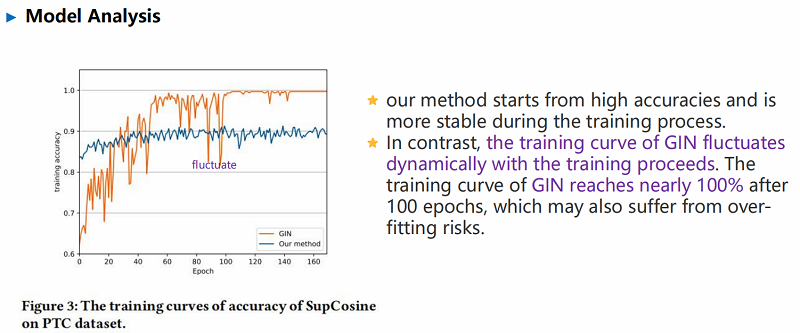
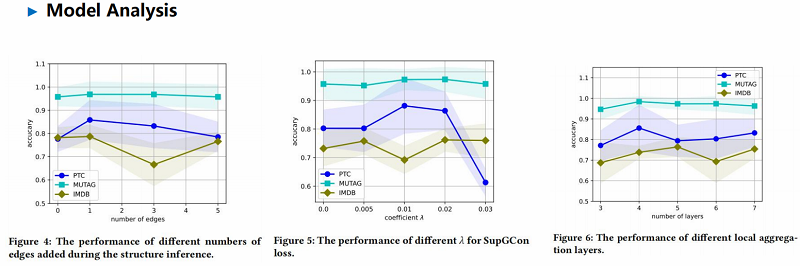
实验