1 导入所需要的包
import numpy as np
import torch
from torch import nn
import matplotlib.pyplot as plt
from IPython import display
from torch.utils.data import TensorDataset ,DataLoader
from sklearn.model_selection import train_test_split
2 自定义数据
要求:
1、生成单个数据集。
2、数据集的大小为10000且训练集大小为7000,测试集大小为3000。
3、数据集的样本特征维度p为500,且服从如下的高维线性函数:$y=0.028+\sum \limits _{i=1}^{p} 0.0056 x_{i}+\epsilon$
num_input,num_example = 500,10000
true_w = torch.tensor(np.ones((num_input,1)),dtype = torch.float32)*0.0056
# true_w = torch.ones(500,1)*0.0056
true_b = 0.028
x_data = torch.tensor(np.random.randn(num_example,num_input),dtype = torch.float32)
y_data = torch.mm(x_data ,true_w)+true_b
y_data += torch.normal(mean = 0,std = 0.001,size=y_data.size())
# y_dat += torch.tensor(np.random.normal(0, 0.01, size=y_data.size()), dtype=torch.float)
train_x,test_x,train_y,test_y = train_test_split(x_data,y_data,shuffle=True,test_size=0.3)
print(train_x.shape)
print(train_y.shape)
print(test_x.shape)
print(test_y.shape)
3 读取数据
batch_size = 50
train_datasets = TensorDataset(train_x,train_y)
train_iter = DataLoader(
dataset = train_datasets,
batch_size = batch_size,
shuffle = True,
num_workers = 0
)
test_datasets = TensorDataset(test_x,test_y)
test_iter = DataLoader(
dataset = test_datasets,
batch_size = batch_size,
shuffle = True,
num_workers = 0
)
4 初始化参数
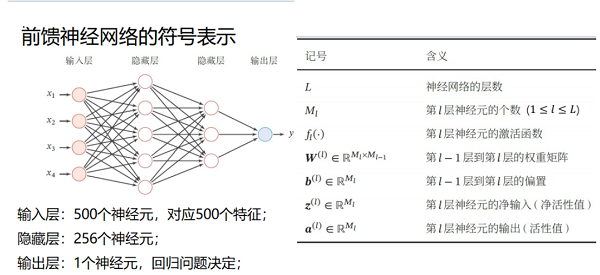
num_hiddens , num_output = 256,1
w1 = torch.normal(mean = 0,std = 0.001,size = (num_hiddens,num_input), dtype=torch.float32)
b1 = torch.ones(1,dtype = torch.float32)
w2 = torch.normal(mean = 0,std = 0.001,size = (num_output,num_hiddens), dtype=torch.float32)
b2 = torch.ones(1,dtype = torch.float32)
params = [w1,w2,b1,b2]
for param in params:
param.requires_grad_(requires_grad=True)
5 定义隐藏层的激活函数
def ReLU(X):
return torch.max(X,other = torch.tensor(0.0))
6 定义模型
def DNN(x):
H = ReLU(torch.matmul(x,w1.t())+b1)
H = ReLU(torch.matmul(H,w2.t())+b2)
return H
7 定义最小化均方误差以及随机梯度下降法
loss = torch.nn.MSELoss()
def SGD(paras,lr,batch_size):
for param in params:
param.data -= lr*param.grad/batch_size
8 定义训练函数
def train(model,train_iter,loss,num_epochs,batch_size,lr,optimizer =None):
train_ls ,test_ls = [],[]
for epoch in range(num_epochs):
train_ls_sum,train_acc_num,n = 0,0,0
for x ,y in train_iter:
y_pred = model(x)
l = loss(y_pred,y)
if params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
SGD(params,lr,batch_size)
train_ls.append(loss(model(train_x),train_y).item())
test_ls.append(loss(model(test_x),test_y).item())
print('epoch %d, train_loss %.6f,test_loss %f'%(epoch+1, train_ls[epoch],test_ls[epoch]))
return train_ls,test_ls
9 训练
lr = 0.001
num_epochs = 500
train_loss ,test_lss =train(DNN,train_iter,loss,num_epochs,batch_size,lr)
10 可视化
x = np.linspace(0,len(train_loss),len(train_loss))
plt.plot(x,train_loss,label="train_loss",linewidth=1.5)
plt.plot(x,test_loss,label="test_loss",linewidth=1.5)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()