首先打开抽屉网址:
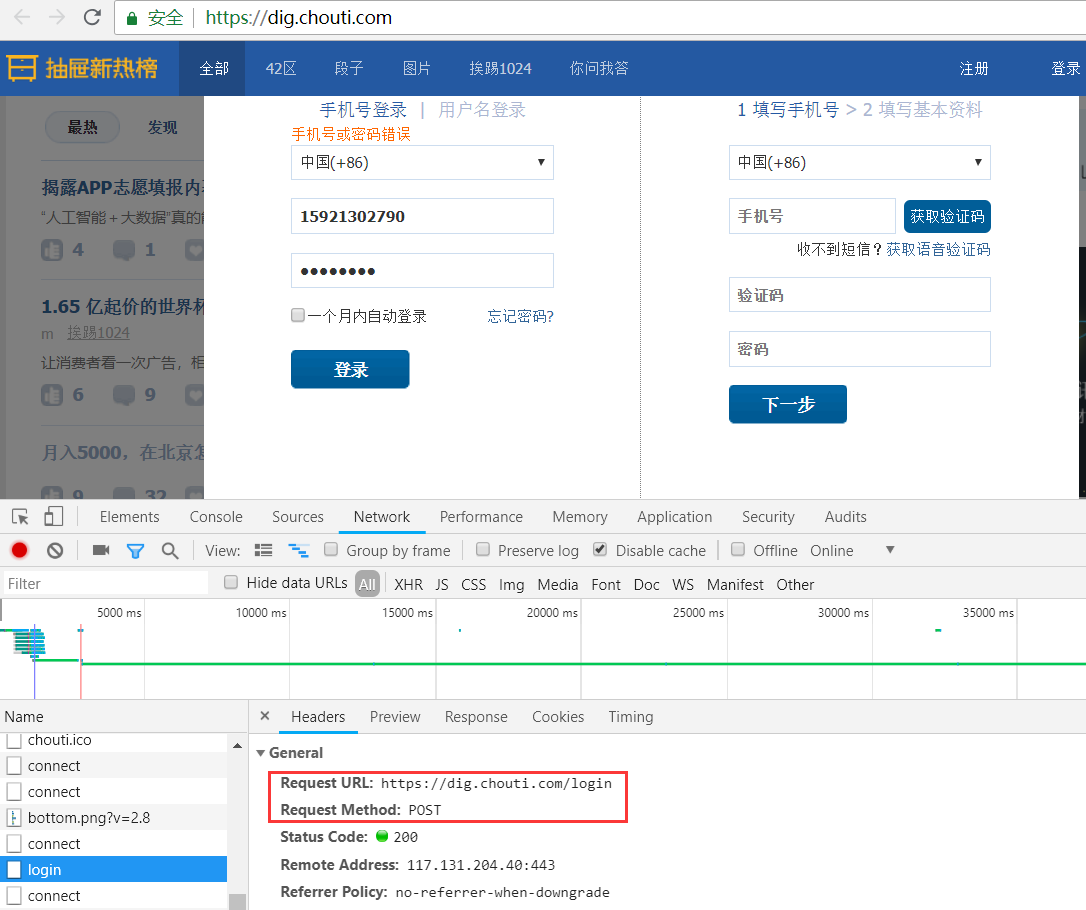
从这里可以看到登陆抽屉的请求url和请求方式;继续拉到底部可以看到form表单传递的数据
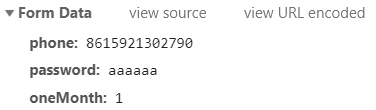
这样我们可以先写一个简单的请求
import requests response = requests.post( url='https://dig.chouti.com/login', data = { 'phone': '8615921302790', 'password': 'aaaaaa', 'oneMonth': '1' } )
然后我们print(response.text)来初步看看拿到了什么
我们在浏览器上输入用户名和不正确的密码,然后分析看到下面的提示
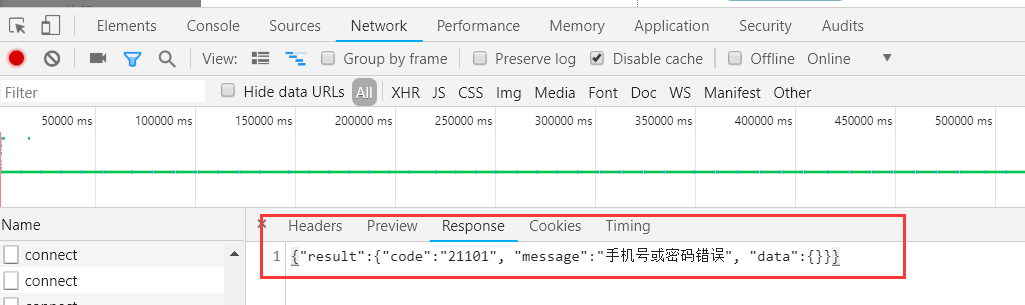
我们再爬取当前页网址
response = requests.get( url='https://dig.chouti.com/all/hot/recent/1' ) print(response.text)
print之后发现还是一样的结果,这时,已经可以推测出网站有防爬虫策略。说明爬虫伪装浏览器访问模仿的不够彻底。我们再来分析浏览器访问当前页面的请求
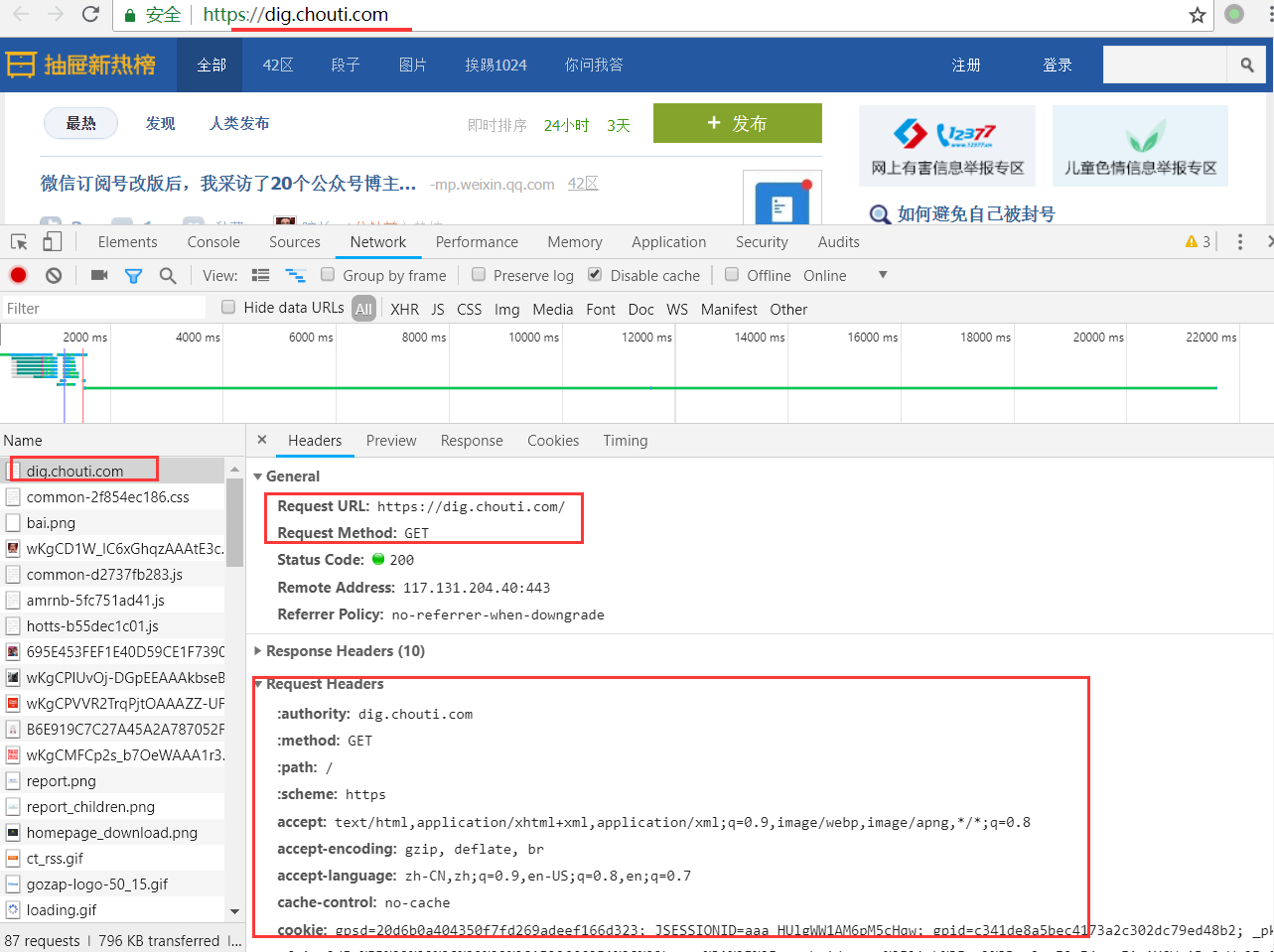
可以看出请求时有很多请求头,后面还有个user-agent,是用户访问的设备信息,复制这个信息,我们再对刚才的请求进行改造
response = requests.get( url='https://dig.chouti.com/all/hot/recent/1', headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' } ) print(response.text)
这次print发现终于能爬下页面了。说明已经绕过防爬虫策略。我们再来更改登陆请求代码
response = requests.post( url='https://dig.chouti.com/login', data = { 'phone': '8615921302790', 'password': 'a123456789!', 'oneMonth': '1' }, headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' } ) print(response.text)
print之后得到:

我把自己登陆密码改对后再print一次

已经能成功模拟登陆,9999表示已经登陆成功。