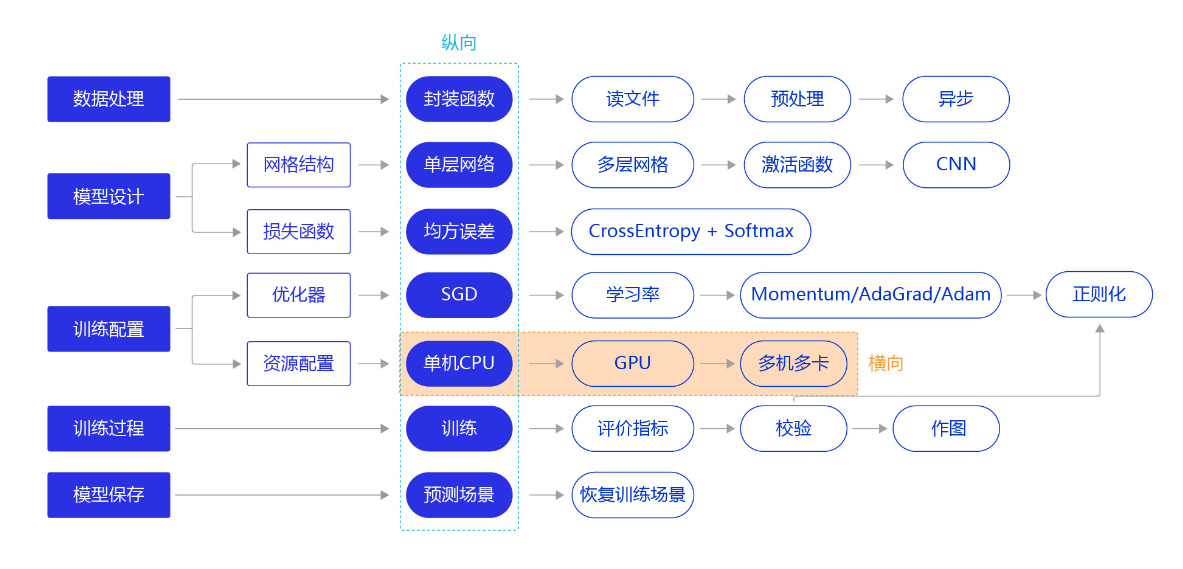
[手写数字识别]资源配置
概述
从前几节的训练看,无论是房价预测任务还是MNIST手写字数字识别任务,训练好一个模型不会超过十分钟,主要原因是我们所使用的神经网络比较简单。但实际应用时,常会遇到更加复杂的机器学习或深度学习任务,需要运算速度更高的硬件(如GPU、NPU),甚至同时使用多个机器共同训练一个任务(多卡训练和多机训练)。本节我们依旧横向展开"横纵式"教学方法,如 图1 所示,探讨在手写数字识别任务中,通过资源配置的优化,提升模型训练效率的方法。
单机训练
在框架中使用接口来配置模型的训练场所,可以选择在CPU或GPU上进行训练,使用GPU可以加速模型的训练过程,飞桨动态图通过fluid.dygraph.guard(place=None)里的place参数,设置在GPU上训练还是CPU上训练。
with fluid.dygraph.guard(place=fluid.CPUPlace()) #设置使用CPU资源训神经网络。
with fluid.dygraph.guard(place=fluid.CUDAPlace(0)) #设置使用GPU资源训神经网络,默认使用服务器的第一个GPU卡。"0"是GPU卡的编号,比如一台服务器有的四个GPU卡,编号分别为0、1、2、3。
分布式训练
在工业实践中,很多较复杂的任务需要使用更强大的模型。强大模型加上海量的训练数据,经常导致模型训练耗时严重。比如在计算机视觉分类任务中,训练一个在ImageNet数据集上精度表现良好的模型,大概需要一周的时间,因为过程中我们需要不断尝试各种优化的思路和方案。如果每次训练均要耗时1周,这会大大降低模型迭代的速度。在机器资源充沛的情况下,建议采用分布式训练,大部分模型的训练时间可压缩到小时级别。
分布式训练有两种实现模式:模型并行和数据并行。
模型并行
模型并行是将一个网络模型拆分为多份,拆分后的模型分到多个设备上(GPU)训练,每个设备的训练数据是相同的。模型并行的实现模式可以节省内存,但是应用较为受限。
模型并行的方式一般适用于如下两个场景:
-
模型架构过大: 完整的模型无法放入单个GPU。如2012年ImageNet大赛的冠军模型AlexNet是模型并行的典型案例,由于当时GPU内存较小,单个GPU不足以承担AlexNet,因此研究者将AlexNet拆分为两部分放到两个GPU上并行训练。
-
网络模型的结构设计相对独立: 当网络模型的设计结构可以并行化时,采用模型并行的方式。如在计算机视觉目标检测任务中,一些模型(如YOLO9000)的边界框回归和类别预测是独立的,可以将独立的部分放到不同的设备节点上完成分布式训练。
数据并行
数据并行与模型并行不同,数据并行每次读取多份数据,读取到的数据输入给多个设备(GPU)上的模型,每个设备上的模型是完全相同的,飞桨采用的就是这种方式。
说明:
当前GPU硬件技术快速发展,深度学习使用的主流GPU的内存已经足以满足大多数的网络模型需求,所以大多数情况下使用数据并行的方式。
数据并行的方式与众人拾柴火焰高的道理类似,如果把训练数据比喻为砖头,把一个设备(GPU)比喻为一个人,那单GPU训练就是一个人在搬砖,多GPU训练就是多个人同时搬砖,每次搬砖的数量倍数增加,效率呈倍数提升。值得注意的是,每个设备的模型是完全相同的,但是输入数据不同,因此每个设备的模型计算出的梯度是不同的。如果每个设备的梯度只更新当前设备的模型,就会导致下次训练时,每个模型的参数都不相同。因此我们还需要一个梯度同步机制,保证每个设备的梯度是完全相同的。
梯度同步有两种方式:PRC通信方式和NCCL2通信方式(Nvidia Collective multi-GPU Communication Library)。
PRC通信方式
PRC(Remote Procedure Call,远程过程调用,允许像调用本地服务一样调用远程服务)通信方式通常用于CPU分布式训练,它有两个节点:参数服务器Parameter server和训练节点Trainer,结构如 图2 所示。
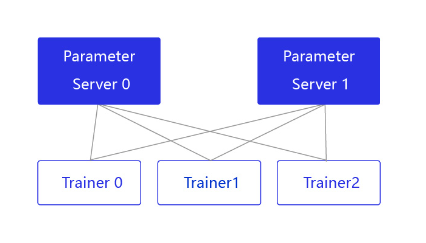
图2:Pserver通信方式的结构
parameter server收集来自每个设备的梯度更新信息,并计算出一个全局的梯度更新。Trainer用于训练,每个Trainer上的程序相同,但数据不同。当Parameter server收到来自Trainer的梯度更新请求时,统一更新模型的梯度。
NCCL2通信方式(Collective)
当前飞桨的GPU分布式训练使用的是基于NCCL2的通信方式,结构如 图3 所示。
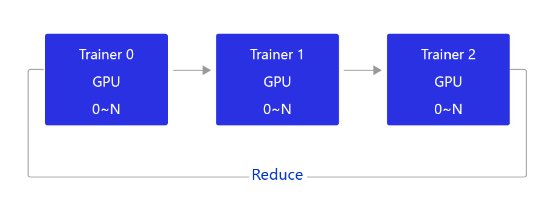
图3:NCCL2通信方式的结构
相比PRC通信方式,使用NCCL2(Collective通信方式)进行分布式训练,不需要启动Parameter server进程,每个Trainer进程保存一份完整的模型参数,在完成梯度计算之后通过Trainer之间的相互通信,Reduce梯度数据到所有节点的所有设备,然后每个节点在各自完成参数更新。
飞桨提供了便利的数据并行训练方式,用户只需要对程序进行简单修改,即可实现在多GPU上并行训练。接下来将讲述如何将一个单机程序通过简单的改造,变成多机多卡程序。
在启动训练前,需要配置如下参数:
- 从环境变量获取设备的ID,并指定给CUDAPlace。
device_id = fluid.dygraph.parallel.Env().dev_id
place = fluid.CUDAPlace(device_id)
- 对定义的网络做预处理,设置为并行模式。
strategy = fluid.dygraph.parallel.prepare_context() ## 新增
model = MNIST()
model = fluid.dygraph.parallel.DataParallel(model, strategy) ## 新增
- 定义多GPU训练的reader,不同ID的GPU加载不同的数据集。
valid_loader = paddle.batch(paddle.dataset.mnist.test(), batch_size=16, drop_last=true)
valid_loader = fluid.contrib.reader.distributed_batch_reader(valid_loader)
- 收集每批次训练数据的loss,并聚合参数的梯度。
avg_loss = model.scale_loss(avg_loss) ## 新增
avg_loss.backward()
mnist.apply_collective_grads() ## 新增
def train_multi_gpu():
##修改1-从环境变量获取使用GPU的序号
place = fluid.CUDAPlace(fluid.dygraph.parallel.Env().dev_id)
with fluid.dygraph.guard(place):
##修改2-对原模型做并行化预处理
strategy = fluid.dygraph.parallel.prepare_context()
model = MNIST()
model = fluid.dygraph.parallel.DataParallel(model, strategy)
model.train()
#调用加载数据的函数
train_loader = load_data('train')
##修改3-多GPU数据读取,必须确保每个进程读取的数据是不同的
train_loader = fluid.contrib.reader.distributed_batch_reader(train_loader)
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())
EPOCH_NUM = 5
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
predict = model(image)
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss)
# 修改4-多GPU训练需要对Loss做出调整,并聚合不同设备上的参数梯度
avg_loss = model.scale_loss(avg_loss)
avg_loss.backward()
model.apply_collective_grads()
# 最小化损失函数,清除本次训练的梯度
optimizer.minimize(avg_loss)
model.clear_gradients()
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#保存模型参数
fluid.save_dygraph(model.state_dict(), 'mnist')
启动多GPU的训练,还需要在命令行中设置一些参数变量。打开终端,运行如下命令:
$ python -m paddle.distributed.launch --selected_gpus=0,1,2,3 --log_dir ./mylog train_multi_gpu.py
- paddle.distributed.launch:启动分布式运行。
- selected_gpus:设置使用的GPU的序号(需要是多GPU卡的机器,通过命令watch nvidia-smi查看GPU的序号)。
- log_dir:存放训练的log,若不设置,每个GPU上的训练信息都会打印到屏幕。
- train_multi_gpu.py:多GPU训练的程序,包含修改过的train_multi_gpu()函数。
说明:
AI Studio当前仅支持单卡GPU,因此本案例需要在本地GPU上执行,无法在AI Studio上演示。
训练完成后,在指定的./mylog文件夹下会产生四个日志文件,其中worklog.0的内容如下: