最近几天在研究爬虫爬取音频网站如何高效的访问并下载,说实话,我一开始还不知道有协程这个东东~~~并且之前一直觉得爬网站用啥方法都一样,能爬就行,自从发现了协程,爱不释手~~~~~
好了废话少说~进入正题:
首先,我们先说一下什么是多线程,在网上的一些教程中都给出这个例子(涉及类和队列)
1 #Example.py 2 ''' 3 Standard Producer/Consumer Threading Pattern 4 ''' 5 6 import time 7 import threading 8 import Queue 9 10 class Consumer(threading.Thread): 11 def __init__(self, queue): 12 threading.Thread.__init__(self) 13 self._queue = queue 14 15 def run(self): 16 while True: 17 # queue.get() blocks the current thread until 18 # an item is retrieved. 19 msg = self._queue.get() 20 # Checks if the current message is 21 # the "Poison Pill" 22 if isinstance(msg, str) and msg == 'quit': 23 # if so, exists the loop 24 break 25 # "Processes" (or in our case, prints) the queue item 26 print "I'm a thread, and I received %s!!" % msg 27 # Always be friendly! 28 print 'Bye byes!' 29 30 31 def Producer(): 32 # Queue is used to share items between 33 # the threads. 34 queue = Queue.Queue() 35 36 # Create an instance of the worker 37 worker = Consumer(queue) 38 # start calls the internal run() method to 39 # kick off the thread 40 worker.start() 41 42 # variable to keep track of when we started 43 start_time = time.time() 44 # While under 5 seconds.. 45 while time.time() - start_time < 5: 46 # "Produce" a piece of work and stick it in 47 # the queue for the Consumer to process 48 queue.put('something at %s' % time.time()) 49 # Sleep a bit just to avoid an absurd number of messages 50 time.sleep(1) 51 52 # This the "poison pill" method of killing a thread. 53 queue.put('quit') 54 # wait for the thread to close down 55 worker.join() 56 57 58 if __name__ == '__main__': 59 Producer()
这个栗子让我想起了大三的课设虽然用的是java实现生产者-消费者模式~~~万恶的java
第一点你需要一个model类,其次需要一个队列来传递对象,是的如果你需要双向通信的话则需要再加入一个一个队列。。
下面,我们需要一个worker线程池,在网页检索中通过多线程加速~~~
1 #Example2.py 2 ''' 3 A more realistic thread pool example 4 ''' 5 6 import time 7 import threading 8 import Queue 9 import urllib2 10 11 class Consumer(threading.Thread): 12 def __init__(self, queue): 13 threading.Thread.__init__(self) 14 self._queue = queue 15 16 def run(self): 17 while True: 18 content = self._queue.get() 19 if isinstance(content, str) and content == 'quit': 20 break 21 response = urllib2.urlopen(content) 22 print 'Bye byes!' 23 24 25 def Producer(): 26 urls = [ 27 'http://www.python.org', 'http://www.yahoo.com' 28 'http://www.scala.org', 'http://www.google.com' 29 # etc.. 30 ] 31 queue = Queue.Queue() 32 worker_threads = build_worker_pool(queue, 4) 33 start_time = time.time() 34 35 # Add the urls to process 36 for url in urls: 37 queue.put(url) 38 # Add the poison pillv 39 for worker in worker_threads: 40 queue.put('quit') 41 for worker in worker_threads: 42 worker.join() 43 44 print 'Done! Time taken: {}'.format(time.time() - start_time) 45 46 def build_worker_pool(queue, size): 47 workers = [] 48 for _ in range(size): 49 worker = Consumer(queue) 50 worker.start() 51 workers.append(worker) 52 return workers 53 54 if __name__ == '__main__': 55 Producer()
可怕,我写不下去了,太复杂了。
我们换一个方法~~~map
1 urls = ['http://www.yahoo.com', 'http://www.reddit.com']
2 results = map(urllib2.urlopen, urls)
对,你没有看错,直接就可以了,result直接遍历urls然后返回的结果存在里面类型是list。
map直接可以实现并行操作了
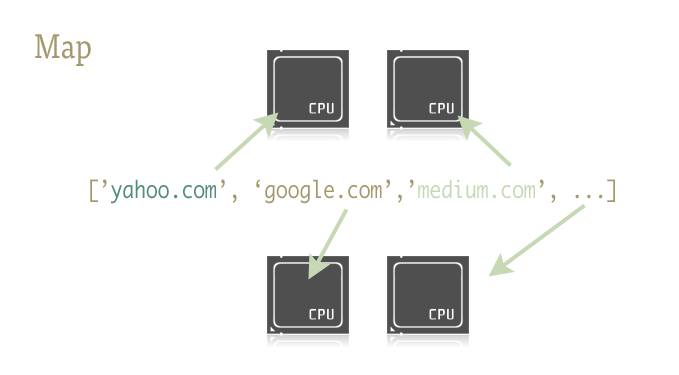
线程过多,切换时所消耗的时间甚至超过实际工作时间,对于实际工作需求,通过尝试来找到合适线程池大小最合适不过了
1 import urllib2 2 from multiprocessing.dummy import Pool as ThreadPool 3 4 urls = [ 5 'http://www.python.org', 6 'http://www.python.org/about/', 7 'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html', 8 'http://www.python.org/doc/', 9 'http://www.python.org/download/', 10 'http://www.python.org/getit/', 11 'http://www.python.org/community/', 12 'https://wiki.python.org/moin/', 13 'http://planet.python.org/', 14 'https://wiki.python.org/moin/LocalUserGroups', 15 'http://www.python.org/psf/', 16 'http://docs.python.org/devguide/', 17 'http://www.python.org/community/awards/' 18 # etc.. 19 ] 20 21 # Make the Pool of workers 22 pool = ThreadPool(4) 23 # Open the urls in their own threads 24 # and return the results 25 results = pool.map(urllib2.urlopen, urls) 26 #close the pool and wait for the work to finish 27 pool.close() 28 pool.join()
其中最关键只有一行,map函数轻易取代前文40多行复杂的例子。
说了这么多,我要讲的东西还没说~~~无语
好了,我要开始了~~~
我用了半天时间研究了一下喜马拉雅听书的网站,并成功写了一个单进程的小爬虫,下载所需要的类型的全部音频资源~~~~听起来很酷,其实吧爬的时候真的慢,于是乎我就加入了协程这个东西,发现速度上去了一大截,其实就是缩短了访问的时间我主要加了两个协程
1 #第一个协程 2 def get_url(): 3 try: 4 start_urls = ['http://www.ximalaya.com/dq/book-%E6%82%AC%E7%96%91/{}/'.format(pn) for pn in range(1,85)] 5 print(start_urls) 6 urls_list = [] 7 for start_url in start_urls: 8 urls_list.append(start_url) 9 # response = fetch_url_text(start_url) 10 # soup = BeautifulSoup(response,'lxml') 11 # print(soup) 12 # break 13 # for item in soup.find_all('div',class_='albumfaceOutter'): 14 # print(item) 15 # href = item.a['href'] 16 # title = item.img['alt'] 17 # img_url = item.img['src'] 18 # # print(title) 19 # content = { 20 # 'href':href, 21 # 'title':title, 22 # 'img_url':img_url 23 # } 24 # get_mp3(href,title) 25 #协程模块1 26 jobs = [gevent.spawn(fetch_url_text,url) for url in urls_list] 27 gevent.joinall(jobs) 28 [job.value for job in jobs] 29 for response in [job.value for job in jobs]: 30 soup = BeautifulSoup(response,'lxml') 31 for item in soup.find_all('div',class_='albumfaceOutter'): 32 print(item) 33 href = item.a['href'] 34 title = item.img['alt'] 35 img_url = item.img['src'] 36 # print(title) 37 content = { 38 'href':href, 39 'title':title, 40 'img_url':img_url 41 } 42 get_mp3(href,title) 43 except Exception as e: 44 print(e) 45 return ''
第二个协程
1 def get_mp3(url,title): 2 response = fetch_url_text(url) 3 num_list = etree.HTML(response).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',') 4 print(num_list) 5 6 mkdir(title) 7 os.chdir(r'F:xmly\'+title) 8 ii=1 9 list_ids = [] 10 for id in num_list: 11 list_ids.append(id) 12 # print(id) 13 # # json_url = 'http://www.ximalaya.com/tracks/{}.json'.format(id) 14 # html = fetch_json(id) 15 # # print(html) 16 # mp3_url = html.get('play_path') 17 # # print(mp3_url) 18 # # download(mp3_url) 19 # content = requests.get(mp3_url, headers=headers).content 20 # name = title + '_%i.m4a'%ii 21 # with open(name, 'wb') as file: 22 # file.write(content) 23 # print("{} download is ok".format(mp3_url)) 24 # ii+=1 25 #协程模块2 26 jobs = [gevent.spawn(fetch_json,id) for id in list_ids] 27 gevent.joinall(jobs) 28 [job.value for job in jobs] 29 for html in [job.value for job in jobs]: 30 mp3_url = html.get('play_path') 31 content = requests.get(mp3_url, headers=headers).content 32 name = title + '_%i.m4a' % ii 33 with open(name, 'wb') as file: 34 file.write(content) 35 print("{} download is ok".format(mp3_url)) 36 ii += 1
代码很冗余啊~~~看看就好了,毕竟刚学,现学现用嘛~~~~
其实吧,我感觉速度还是不够
可以再添加多进程模块进去,速度可能又会上去,如果再分布式呢?岂不是分分钟爬完整个站的内容,哈哈
好了,不做白日梦了,我只有一个笔记本,而且实验室服务器就两个,并且都在跑训练模型,就不给他们添加负担了~~~~~
还没说协程是什么啊~~~~~
协程可以理解为绿色的线程,或者微线程,起作用是在执行function_a()时可以随时中断去执行function_b(),然后中断继续function_a(),可自由切换。整个过程看似多线程,然而只有一个线程执行,也就是gevent中的monkeyAPI实现了异步的过程~~~~好神奇是不是
1 #! -*- coding:utf-8 -*- 2 #version:2.7 3 import gevent 4 from gevent import monkey;monkey.patch_all() 5 import urllib2 6 def get_body(i): 7 print "start",i 8 urllib2.urlopen("http://cn.bing.com") 9 print "end",i 10 tasks=[gevent.spawn(get_body,i) for i in range(3)] 11 gevent.joinall(tasks)
这个简单栗子应该很容易明白~~~~~
我总结了一下,只要是有for而且其中每次都需要大量时间做请求的程序都可以调用协程来完成~~~~~
我的理解可能有偏差,欢迎指正~~~~
总结一下,并发和并行吧~~~~~
并发,就相当于有两个队伍,一个caffe机,轮流用这个caffe机
并行,就相当于有两个队伍,两个coffe机,一个队伍用一个,且同时进行。~~~~~
是不是很浅显~~~~~
拜拜~~~~~~~~~~