Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
安装Scrapy的过程比较复杂而且容易出错,贴出一个参考链接:windows下scrapy安装步骤。
安装完成后,在自定义目录下输入
scrapy startproject Project_Name //创建新爬虫项目 scrapy genspider -t crawl Crawl_Name Url_addr//创建爬虫,模板,爬虫名和待爬网址
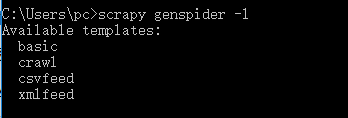
Scrapy内置的爬虫模板可使用:scrapy genspider -l 来查询,查询结果如下:包括basic crawl csvfeed xmlfeed四种类型。
使用以上命令后,便会在目录中自动生成爬虫项目,包含的内容如下图:
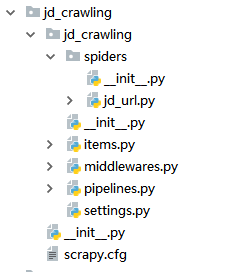
分别代表的意义为:
scrapy.cfg:项目的配置文件
jd_crawling/:项目的Python模块,将会从这里引用代码
jd_crawling/items.py:项目的items文件
jd_crawling/pipelines.py:项目的pipelines文件 (pipeline意为管道,即将数据传递过来进行储存或处理)
jd_crawling/settings.py:项目的设置文件
jd_crawling/spiders/:存储爬虫的目录
进入目录中,在item中定义待爬的关键字(target),目的是封装进Item中,做为整个项目的一个对象进行引用和处理
class JdCrawlingItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() goods_name = scrapy.Field()#定义商品名称 goods_link = scrapy.Field()#定义商品链接
items创建完成后进入spider创建爬虫规则:先爬,再取。可以看到在子佛那个创建的项目中已经为我们自动创建了一些内容:
class JdUrlSpider(CrawlSpider): name = 'jd_url' #爬虫的识别名称,必须唯一 allowed_domains = ['jd.com'] # 允许执行的url范围 start_urls = ['http://www.jd.com/'] # 爬取的URL列表
创建匹配规则:
def parse_item(self, response): #解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item) item = JdCrawlingItem() #此处便引用了之前定义的item item['goods_name'] = response.xpath("//a[@class='pic']/@title").extract() item['goods_link'] = response.xpath("//a[@class='pic']/@href").extract() print(item['goods_name'])
xpath的使用方法详见:关于scrapy网络爬虫的xpath书写经验总结
最后执行:scrapy crawl jd_url 则可以开始我们的爬虫了。
这是最基本的爬虫,之后还会涉及到:1通过pipeline 写进数据库(pymsql)2突破反爬虫限制3爬虫数据分析和处理等内容。会在接下来的内容中完善