问题
- 为什么需要虚拟内存
- 如何实现
虚拟内存的动机
早期程序员自己写程序还要自己管理内存地址(内存条上的地址),要自己知道分配到内存条的哪个地方, 为了解决这个问题,早期的分页管理就出现了,程序员只要知道逻辑地址就可以,然后真实的物理地址不需要管,由分页管理。 举例 : 当时有一种计算机,其指令中给出的主存地址为16位,而主存容量只有4k字,则指令可寻址范围是多少呢? 答 : 2的16次方,当时内存2的16次方远远大于4k字这个可用范围,怎么办呢?相当于说我的程序非常地长,而我们主存装不下,于是就出现了分页加载,分段加载,段页式加载。个人觉得虚拟内存的原因 :
- 计算机只能加载部分程序,内部不能像硬盘那样的容量
- 内存管理
早期分页方式执行过程
- 只有一个页框,也就是只有一页可以加载到内存中去
- 把执行完的程序放回磁盘中去,新的加载进来
- 改变地址映射(仅改变映射区间(页号))
现在分页
逻辑地址可以无限大,实际是映射在物理地址上的。这里所说的物理地址指的是主存的物理地址!!!!不是磁盘的物理地址!!切记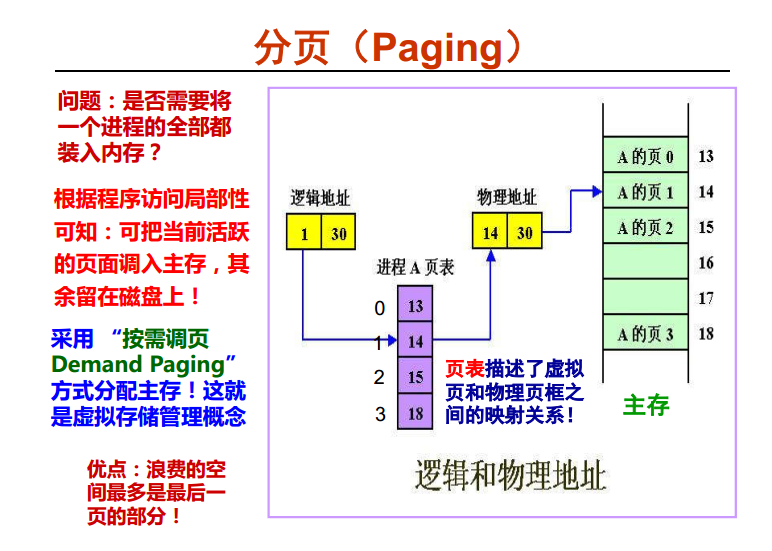 假如进程A有4张表,位于13 14 15 18 这几个页框内(物理地址可以不连续),当此时我需要访问逻辑中的1号的位置,那么操作系统就会去进程A 页表中找到1 对应的是哪个主存的哪个位置,经过查询是 14页框的地址,里面放着是对应的物理地址,于是就拿到了想要访问的物理地址。
假如进程A有4张表,位于13 14 15 18 这几个页框内(物理地址可以不连续),当此时我需要访问逻辑中的1号的位置,那么操作系统就会去进程A 页表中找到1 对应的是哪个主存的哪个位置,经过查询是 14页框的地址,里面放着是对应的物理地址,于是就拿到了想要访问的物理地址。
- 页表左边 : 0123 表示的是逻辑地址上的第一页,第二页,第三页...
- 页表右边 : 表示的是对应的在主存中的哪个页框,上图就是主存的14号页框 也就是说逻辑地址只是一个代号0123456789....,而物理页框是表示真正在内存中的页框位置,那么就有可能假如说我要找逻辑地址为9对应的内存页框是哪个的时候,发现对应的页框是空的(还没有加载进来),就是说缺页了,此时就要从磁盘中加载也到内存中去,有可能页表对应的物理地址在磁盘中(物理地址 : 主存中,磁盘中,空页)。
虚拟存储系统
虚拟存储系统的基本概念

这张图非常重要,虚拟内存解决的问题就是要让程序员在比主存空间大得多的逻辑地址空间中编写程序 ,程序的机器码是放在硬盘中的, 硬盘相对于主存大的很多,所以可以表示的地址大的很多,但是CPU 是在主存中读取程序的,所以就用了一套逻辑地址来表示运行的数据放在哪个地方,而页表就是来表示逻辑地址和物理地址之间的映射的,假如物理地址中没有数据就是缺页了,那么就从磁盘中先加载到内存中再继续运行。
虚拟存储技术的实质
- 程序猿可以比在实际主存空间大得多的逻辑地址空间中编写程序
- 按需调用程序

执行程序 -》 启动进程 -》 调程序到主存中
虚拟地址空间
虚拟地址把内核空间和用户空间一分为二,执行用户空间里的代码后又转向执行内核空间的代码,就会发生 进程的上下文切换 。 下面的是用户栈和堆则是向着一个方向生长着,中间有个 Memory-mapped region for shared libraries ,
一个进程的虚拟地址空间包括内核虚拟内存和用户栈等等。
可执行文件初始化的时候只会建立页表不会马上就加载到内存中去,只有需要的时候才进行加载,所以才会产生缺页。 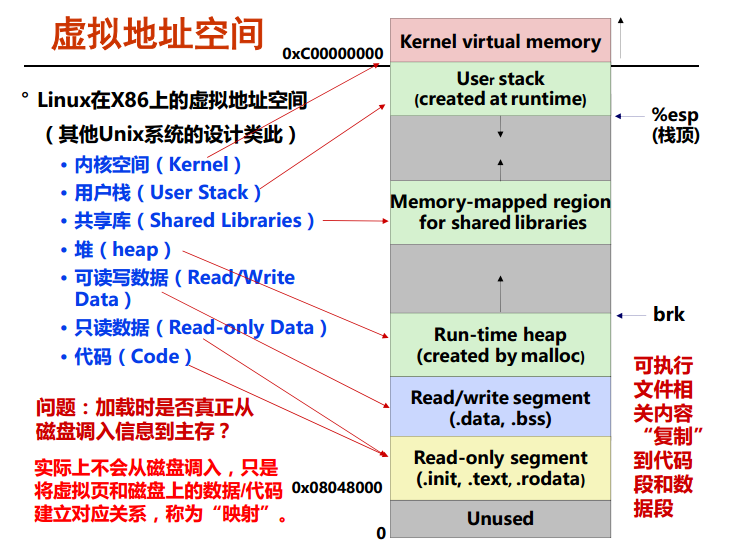
虚拟存储器管理的实现要解决的问题
也就是解决以下问题 :

主存-磁盘层次

这里的 write back 就是java 的 flush 一样的操作,因为 CPU 不可能写内存页的一点内容然后马上就回刷回去,肯定是写内存,然后在某个时间点在flush 回去,那么就必须有个标志来表示脏页。
页表
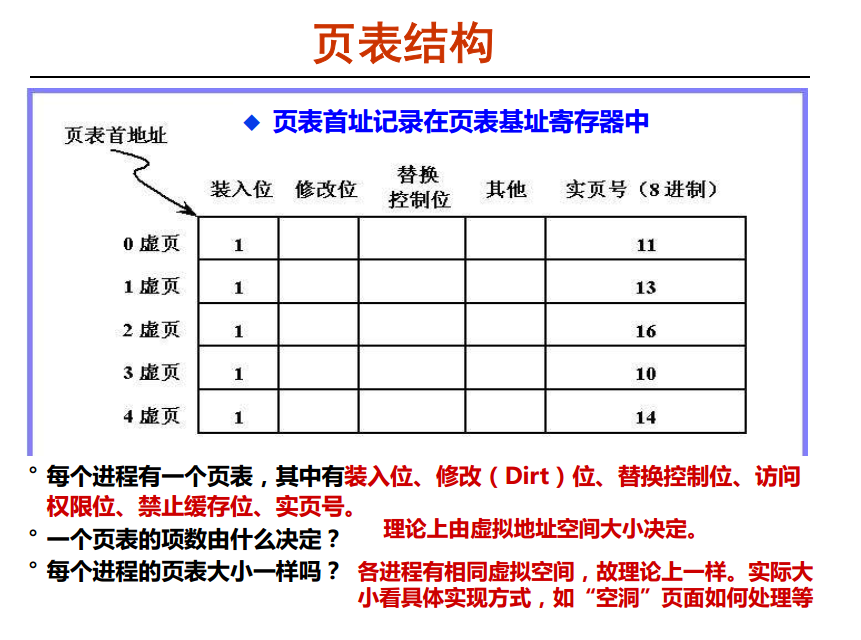
- 装入位 : 表示该页存不存在内存中(是否已经从磁盘中加载进来了)
- 修改位 : 上面所说的,该内存页是否给人修改了,即是否是脏页
- 替换位 : 内存空间不大,所以要用 cache 算法来交换替代那些暂时不需要的内存页。
- 访问位 :
- 禁止缓存位 : 这个要是给其他用的,给不给缓存到cache 里面去
- 实页为 : 该逻辑地址对应的是内存中的哪一页,页框编号,因为每一页的大小都是一样的,那么就相当对内存除以页的大小,就可以算出主存到底可以放多少个页,对每一个页的位置进行编号,就是页框号
一个进程,逻辑地址共 4GB , 一页为 4KB ,所以需要用 2 的 20 次方这么多页来表示一个进程的页表,所以一个进程的页表项数太多了(HashMap 的 size 同理) ,所以对页表也要分页。 页表是放在虚拟空间的内核地址里面。
页项分类
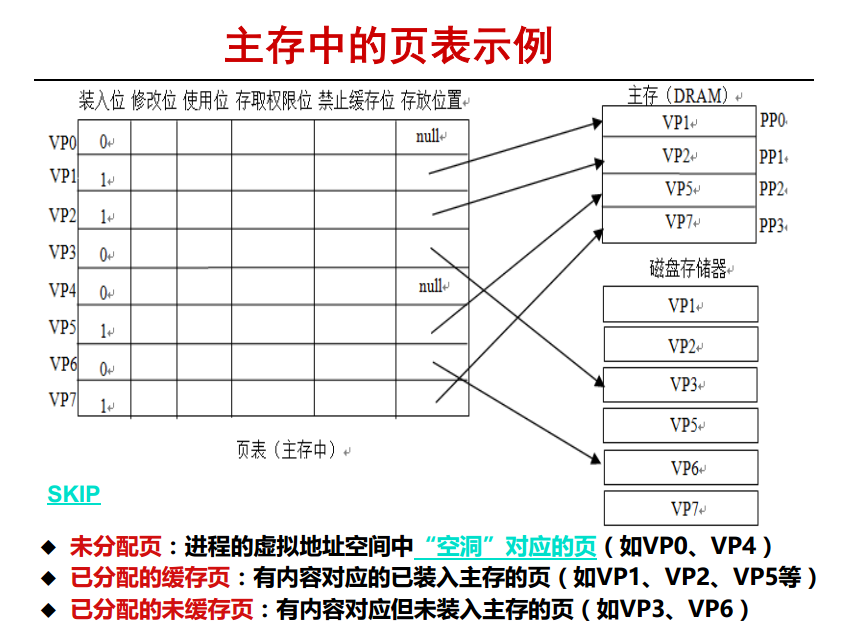
页表中(相当于一个HashMap , key 是逻辑地址,value 逻辑地址对应的信息) 这么多项可以分类为三种
- 未分配页 :未使用
- 已分配的缓存页 : 快要被执行了,磁盘里的数据已经加载到主存中了!!!所以CPU 只要这个地址就够了(假如CPU 此时 read 操作,write 也可以啊,改了数据后再 write back 回刷回硬盘)
- 已分配的未缓存页 : 该页快给使用到了,但是内容还在磁盘中还未加载进来。
页表的缓存

我们上面说了一个进程的页表要有2的20次方项,这太大了,所以我们要对页表进行缓存,把经常用的页表的中的项缓存起来,这个东西就是 TLB 。 这里说一下全相联和组相联,全相联相当于给了某一个HashMap 中的某一个 key 的值,那么就很准确得到 value , 而组相联则是先给你某一个HashMap ,再给你一个 index ,就是从这个HashMap 从 0 开始数,往下找。
CPU 访问示例
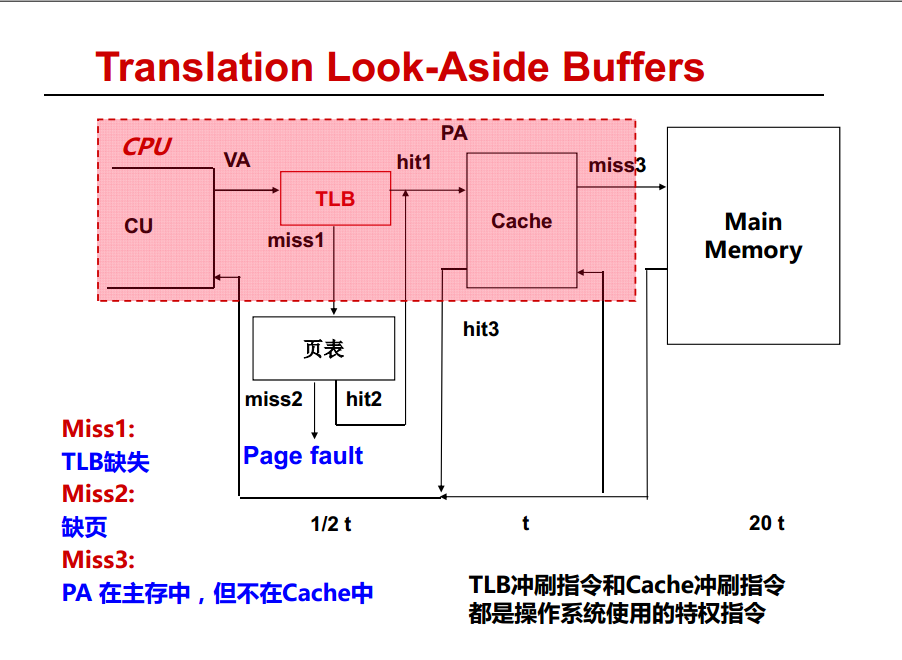
我们看到假如CPU 首先查看 TLS 中有已经缓存的页表项,那么直接到 CaChe 中的拿就好了,走Hit 3 那条路线返回,这是最好的结果,根本不用访问内存,下面这张图要好好理解 。
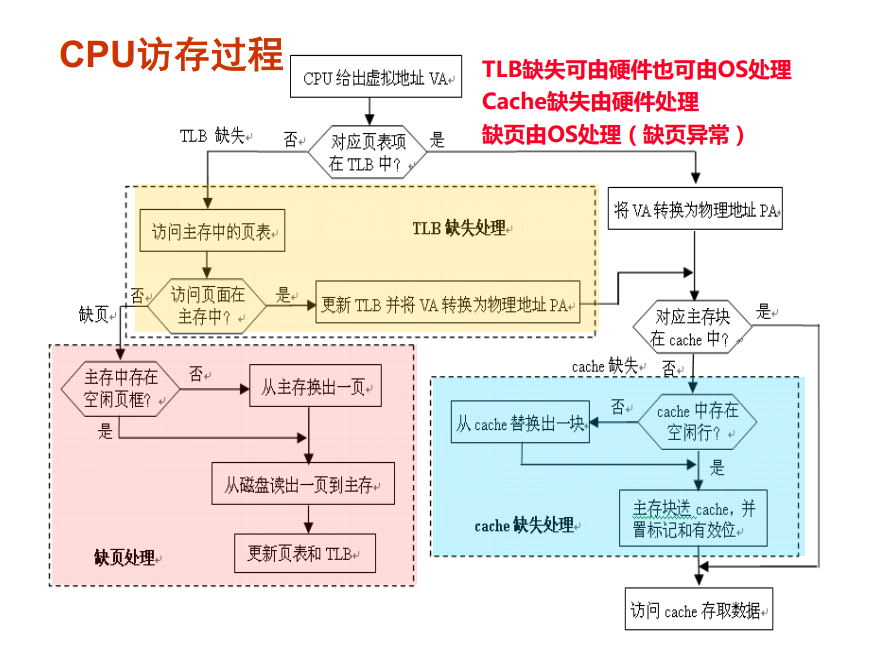
补充
 上图是存储层次图。
上图是存储层次图。
总结
文章对虚拟内存进行复习,后面几篇文章细讲分页式和分段式的实现。
参考文章
- mooc上袁春风老师的课