在这个0.5版本中,我们将TensorFlow模型评分作为ML.NET的转换类添加。这样可以在ML.NET实验中使用现有的TensorFlow模型。社区提出的各种问题和反馈可以在这里找到。
作为即将到来的ML.NET之路的一部分,我们正在开发一种新的ML.NET API,它可以提高灵活性和易用性。当新API准备得足够好时,我们计划弃用当前的LearningPipelineAPI。因为这将是一个重大变化,本文末尾分享我们对多个API选项和比较的建议。
此博客文章提供了有关ML.NET中以下主题的详细信息:
-
在ML.NET v0.5中添加了TensorFlow模型评分转换(TensorFlowTransform)
-
新的ML.NET API建议
TensorFlow模型评分转换(TensorFlowTransform)
TensorFlow是一种流行的深度学习和机器学习工具包,可以训练深度神经网络(和通用数值计算)。
深度学习是人工智能和机器学习的一个子集,它教授程序来做人类自然而然的事情:通过实例学习。
与传统机器学习相比,它的主要区别在于深度学习模型可以学习直接从图像,声音或文本中执行对象检测和分类任务,甚至可以提供语音识别和语言翻译等任务,而传统的ML方法则严重依赖于特征工程和数据处理。
深度学习模型需要通过使用包含多个层的大量标记数据和神经网络进行训练。它目前的流行是由几个原因引起的。首先,它在计算机视觉等一些任务上表现更好 第二,因为它可以利用现在变得可用的大量数据(并且需要该量以便表现良好)。
使用ML.NET 0.5,我们开始在ML.NET中添加对深度学习的支持。今天,我们通过新引进与TensorFlow在ML.NET整合的第一级TensorFlowTransform这使得能够以现有的TensorFlow模型,无论是你训练或从别的地方下载的,并得到来自ML.NET的TensorFlow模型的分数。
这种新的TensorFlow评分功能不需要您具备TensorFlow内部细节的工作知识。从长远来看,我们将致力于使用ML.NET进行深度学习的体验变得更加容易。
此转换的实现基于TensorFlowSharp的代码。
如下图所示,您只需在.NET Core或.NET Framework应用程序中添加对ML.NET NuGet包的引用。在封面下,ML.NET包含并引用了本机TensorFlow库,它允许您编写加载现有训练的TensorFlow模型文件以进行评分的代码。
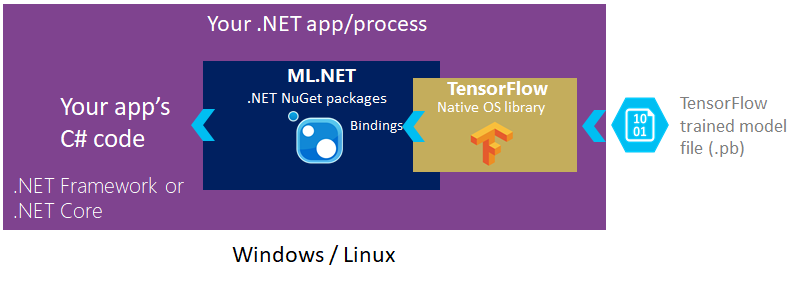
// ... Additional transformations in the pipeline code pipeline.Add(new TensorFlowScorer() { ModelFile = "model/tensorflow_inception_graph.pb", // Example using the Inception v3 TensorFlow model InputColumns = new[] { "input" }, // Name of input in the TensorFlow model OutputColumn = "softmax2_pre_activation" // Name of output in the TensorFlow model }); // ... Additional code specifying a learner and training process for the ML.NET model
您可以在此处找到与上述代码片段相关的完整代码示例TensorFlowTransform,使用TensorFlow Inception v3模型和现有LearningPipelineAPI。
上面的代码示例使用名为Inception v3的预先训练的TensorFlow模型,您可以从此处下载。在成立之初V3是受过训练的非常流行的图像识别模型ImageNet数据集,其中TensorFlow模型试图整个图像分成千类,如“伞”,“泽西”和“厨房”。
该盗梦空间V3模型可以被归类为深卷积神经网络,可以实现对硬盘的视觉识别任务,匹配或超过在某些领域人类行为的合理性能。该模型/算法由多位研究人员根据原始论文开发:“重新思考计算机视觉的初始架构”,Szegedy等。人。
在下一个ML.NET版本中,我们将添加功能,以便识别TensorFlow模型的预期输入和输出。目前,使用TensorFlow API或Netron等工具来探索TensorFlow模型。
如果您tensorflow_inception_graph.pb使用Netron打开上一个示例TensorFlow模型文件()并浏览模型的图形,您可以看到它如何InputColumn与input图形开头的节点相关联:
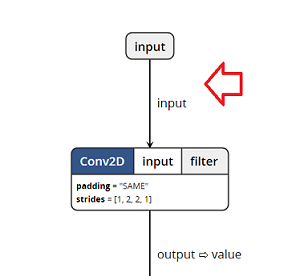
以及如何OutputColumn与softmax2_pre_activation节点的输出相关联几乎在图的末尾。

限制:我们目前正在更新ML.NET API以提高灵活性,因为在今天的ML.NET中使用TensorFlow有一些限制。就目前而言(当使用LearningPipelineAPI时),这些分数只能LearningPipeline作为输入(数字向量)用于像分类器学习者这样的学习者。但是,随着即将推出的新ML.NET API,TensorFlow模型得分将可以直接访问,因此您可以使用TensorFlow模型进行评分,而无需在此示例中实现添加额外的学习者及其相关的训练过程。它使用与数字向量要素相关的标签(对象名称),基于StochasticDualCoordinateAscentClassifier创建多类分类ML.NET模型 TensorFlow模型为每个图像文件生成/评分。
考虑到使用ML.NET提到的TensorFlow代码示例正在使用v0.5中LearningPipeline提供的当前API。接下来,支持使用TensorFlow的ML.NET API将略有不同,而不是基于“pipeline”。这与此博客文章的下一部分有关,该部分重点介绍即将推出的ML.NET新API。
最后,我们还要强调ML.NET框架目前正在出现TensorFlow,但未来我们可能会考虑其他深度学习库集成,例如Torch和CNTK。
您可以在此处使用TensorFlowTransform现有LearningPipelineAPI 查找其他代码示例/测试。
探索即将推出的新ML.NET API(0.5之后)并提供反馈
正如本文开头所提到的,我们非常期待在制作ML.NET时创建新的ML.NET API时得到您的反馈。ML.NET的这种发展提供了比当前LearningPipelineAPI提供的更灵活的功能。在LearningPipeline当这个新的API准备和足够好的API将被弃用。
以下链接到我们以GitHub形式获得的一些示例反馈,这些反馈是关于使用LearningPipelineAPI 时的限制:
因此,基于LearningPipelineAPI的反馈,几周前我们决定切换到新的ML.NET API,以解决LearningPipelineAPI目前的大部分限制。
这个新ML.NET API的设计原则
我们正在根据以下原则设计此新API:
-
使用与Scikit-Learn,TensorFlow和Spark等其他知名框架并行的术语,我们将尝试在命名和概念方面保持一致,使开发人员更容易理解和学习ML.NET Core。
-
保持简单和简洁的ML场景,如简单的训练和预测。
-
允许高级ML场景(使用当前
LearningPipelineAPI 无法实现,如下一节所述)。
我们还探索了诸如Fluent API,声明性和命令式等API方法。
有关原则和所需方案的更深入讨论,请在GitHub中查看此问题。
为什么ML.NET正在从LearningPipelineAPI 切换到新的API?
作为预览版制作过程的一部分(请记住ML.NET仍处于早期预览中),我们一直在获得LearningPipelineAPI反馈,并发现了一些我们需要通过创建更灵活的API来解决的限制。
具体来说,新的ML.NET API提供了当前LearningPipelineAPI 无法实现的有吸引力的功能:
-
强类型API:这种新的强类型API利用了C#功能,因此可以在编译时发现错误,同时改进编辑器中的Intellisense。
-
更好的灵活性:此API提供可分解的训练和预测过程,消除了刚性和线性管道执行。使用新API,执行某个代码路径,然后分叉执行,以便多个路径可以重用初始公共执行。例如,与多个学习者和培训师共享给定变换的执行和转换数据,或分解管道并添加多个学习者。
这个新的API是基于概念,如Estimators,Transforms和DataView,在这篇博客文章下面的代码所示。
-
改进的可用性:从代码直接调用API,不再需要脚手架或日照层,在用户/开发人员编写的内容和内部API之间创建模糊的分隔。入口点不再是强制性的。
-
能够使用TensorFlow模型进行简单评分。由于API中提到的灵活性,您还可以简单地加载TensorFlow模型并使用它进行评分,而无需添加任何其他学习者和培训过程,如TensorFlow部分之前的“限制”主题中所述。
-
更好地查看转换后的数据:在应用变换器时,您可以更好地查看数据。
强类型API与LearningPipelineAPI的比较
另一个重要的比较与新API中的强类型API功能有关。
作为您没有强类型API时可以获得的问题的示例,LearningPipelineAPI(如下面的代码所示)通过将列的名称指定为字符串来提供对数据列的访问,因此如果您输入错字(即,写了“Descrption”没有'i'而不是“Description”,作为示例代码中的拼写错误,你会得到一个运行时异常:
pipeline.Add(new TextFeaturizer("Description", "Descrption"));
但是,当使用新的ML.NET API时,它是强类型的,因此如果你输入错误,它将在编译时捕获,你也可以在编辑器中使用Intellisense。
var estimator = reader.MakeEstimator() .Append(row => ( description: row.description.FeaturizeText()))
有关可分解列车和预测API的详细信息
以下代码片段显示了如何使用ML.NET中的新API实现“GitHub issue labeler”示例应用程序的转换和培训过程。
这是我们当前的提案,根据您的反馈,此API可能会相应地发展。
新的ML.NET API代码示例:
public static async Task BuildAndTrainModelToClassifyGithubIssues() { var env = new MLEnvironment(); string trainDataPath = @"Dataissues_train.tsv"; // Create reader var reader = TextLoader.CreateReader(env, ctx => (area: ctx.LoadText(1), title: ctx.LoadText(2), description: ctx.LoadText(3)), new MultiFileSource(trainDataPath), hasHeader : true); var loss = new HingeLoss(new HingeLoss.Arguments() { Margin = 1 }); var estimator = reader.MakeNewEstimator .Append(row => ( // Convert string label to key. label: row.area.ToKey(), // Featurize 'description' description: row.description.FeaturizeText(), // Featurize 'title' title: row.title.FeaturizeText())) .Append(row => ( // Concatenate the two features into a vector and normalize. features: row.description.ConcatWith(row.title).Normalize(), // Preserve the label - otherwise it will be dropped label: row.label)) .Append(row => ( // Preserve the label (for evaluation) row.label, // Train the linear predictor (SDCA) score: row.label.PredictSdcaClassification(row.features, loss: loss))) .Append(row => ( // Want the prediction, as well as label and score which are needed for evaluation predictedLabel: row.score.predictedLabel.ToValue(), row.label, row.score)); // Read the data var data = reader.Read(new MultiFileSource(trainDataPath)); // Fit the data to get a model var model = estimator.Fit(data); // Use the model to get predictions on the test dataset and evaluate the accuracy of the model var scores = model.Transform(reader.Read(new MultiFileSource(@"Dataissues_test.tsv"))); var metrics = MultiClassClassifierEvaluator.Evaluate(scores, r => r.label, r => r.score); Console.WriteLine("Micro-accuracy is: " + metrics.AccuracyMicro); // Save the ML.NET model into a .ZIP file await model.WriteAsync("github-Model.zip"); } public static async Task PredictLableForGithubIssueAsync() { // Read model from an ML.NET .ZIP model file var model = await PredictionModel.ReadAsync("github-Model.zip"); // Create a prediction function that can be used to score incoming issues var predictor = model.AsDynamic.MakePredictionFunction<GitHubIssue, IssuePrediction>(env); // This prediction will classify this particular issue in a type such as "EF and Database access" var prediction = predictor.Predict(new GitHubIssue { title = "Sample issue related to Entity Framework", description = @"When using Entity Framework Core I'm experiencing database connection failures when running queries or transactions. Looks like it could be related to transient faults in network communication agains the Azure SQL Database." }); Console.WriteLine("Predicted label is: " + prediction.predictedLabel); }
与以下LearningPipeline缺乏灵活性的旧API代码段相比较,因为管道执行不可分解但是线性:
旧的LearningPipelineAPI代码示例:
public static async Task BuildAndTrainModelToClassifyGithubIssuesAsync() { // Create the pipeline var pipeline = new LearningPipeline(); // Read the data pipeline.Add(new TextLoader(DataPath).CreateFrom<GitHubIssue>(useHeader: true)); // Dictionarize the "Area" column pipeline.Add(new Dictionarizer(("Area", "Label"))); // Featurize the "Title" column pipeline.Add(new TextFeaturizer("Title", "Title")); // Featurize the "Description" column pipeline.Add(new TextFeaturizer("Description", "Description")); // Concatenate the provided columns pipeline.Add(new ColumnConcatenator("Features", "Title", "Description")); // Set the algorithm/learner to use when training pipeline.Add(new StochasticDualCoordinateAscentClassifier()); // Specify the column to predict when scoring pipeline.Add(new PredictedLabelColumnOriginalValueConverter() { PredictedLabelColumn = "PredictedLabel" }); Console.WriteLine("=============== Training model ==============="); // Train the model var model = pipeline.Train<GitHubIssue, GitHubIssuePrediction>(); // Save the model to a .zip file await model.WriteAsync(ModelPath); Console.WriteLine("=============== End training ==============="); Console.WriteLine("The model is saved to {0}", ModelPath); } public static async Task<string> PredictLabelForGitHubIssueAsync() { // Read model from an ML.NET .ZIP model file _model = await PredictionModel.ReadAsync<GitHubIssue, GitHubIssuePrediction>(ModelPath); // This prediction will classify this particular issue in a type such as "EF and Database access" var prediction = _model.Predict(new GitHubIssue { Title = "Sample issue related to Entity Framework", Description = "When using Entity Framework Core I'm experiencing database connection failures when running queries or transactions. Looks like it could be related to transient faults in network communication agains the Azure SQL Database..." }); return prediction.Area; }
旧LearningPipelineAPI是完全线性的代码路径,因此您无法将其分解为多个部分。
例如,BikeSharing ML.NET示例(在机器学习样本GitHub repo中可用)正在使用当前的LearningPipelineAPI。
此示例使用评估程序API通过以下方式比较回归学习者的准确性:
- 执行多个数据转换为原始数据集
- 基于七种不同的回归训练器/算法(如FastTreeRegressor,FastTreeTweedieRegressor,StochasticDualCoordinateAscentRegressor等)训练和创建七种不同的ML.NET模型
目的是帮助您比较给定问题的回归学习者。
由于这些模型的数据转换是相同的,因此您可能希望重用与转换相关的代码执行。但是,由于LearningPipelineAPI仅提供单个线性执行,因此您需要为您创建/训练的每个模型运行相同的数据转换步骤,如以下代码摘录自BikeSharing ML.NET示例所示。
var fastTreeModel = new ModelBuilder(trainingDataLocation, new FastTreeRegressor()).BuildAndTrain(); var fastTreeMetrics = modelEvaluator.Evaluate(fastTreeModel, testDataLocation); PrintMetrics("Fast Tree", fastTreeMetrics); var fastForestModel = new ModelBuilder(trainingDataLocation, new FastForestRegressor()).BuildAndTrain(); var fastForestMetrics = modelEvaluator.Evaluate(fastForestModel, testDataLocation); PrintMetrics("Fast Forest", fastForestMetrics); var poissonModel = new ModelBuilder(trainingDataLocation, new PoissonRegressor()).BuildAndTrain(); var poissonMetrics = modelEvaluator.Evaluate(poissonModel, testDataLocation); PrintMetrics("Poisson", poissonMetrics); //Other learners/algorithms //...
BuildAndTrain()方法需要同时具有数据转换和每种情况下的不同算法,如以下代码所示:
public PredictionModel<BikeSharingDemandSample, BikeSharingDemandPrediction> BuildAndTrain() { var pipeline = new LearningPipeline(); pipeline.Add(new TextLoader(_trainingDataLocation).CreateFrom<BikeSharingDemandSample>(useHeader: true, separator: ',')); pipeline.Add(new ColumnCopier(("Count", "Label"))); pipeline.Add(new ColumnConcatenator("Features", "Season", "Year", "Month", "Hour", "Weekday", "Weather", "Temperature", "NormalizedTemperature", "Humidity", "Windspeed")); pipeline.Add(_algorythm); return pipeline.Train<BikeSharingDemandSample, BikeSharingDemandPrediction>(); }
使用旧LearningPipelineAPI,对于使用不同算法的每次培训,您需要再次运行相同的过程,一次又一次地执行以下步骤:
- 从文件加载数据集
- 进行列转换(连续,复制或其他特征或字典,如果需要)
但是,基于新的ML.NET API Estimators,DataView您将能够重用部分执行,就像在这种情况下一样,重新使用数据转换执行作为使用不同算法的多个模型的基础。
您还可以在此处使用新API探索其他代码示例。