机器学习中一类问题称为峰值检测,它旨在识别与大部分时序中明显不同但临时突发的数据值。及时检测到这些可疑的个体、事件或观察值很重要,这样才能尽量减少其产生。异常情况检测是检测时序数据离群值的过程,在给定的输入时序上指向“怪异”或不是预期行为的峰值。
通常有两种类型的时序异常检测:
-
峰值,指示系统中临时突发的异常行为。
-
更改点,指示系统中一段时间内持续更改的开始。
在 ML.NET 中,IID 峰值检测或 IID 更改点检测算法适用于独立且均匀分布的数据集。峰值检测不需要任何训练,这一点不像其他的机器学习场景,代码也非常简单。
我们来看一个真实的例子,假设有这样一组日志数据:
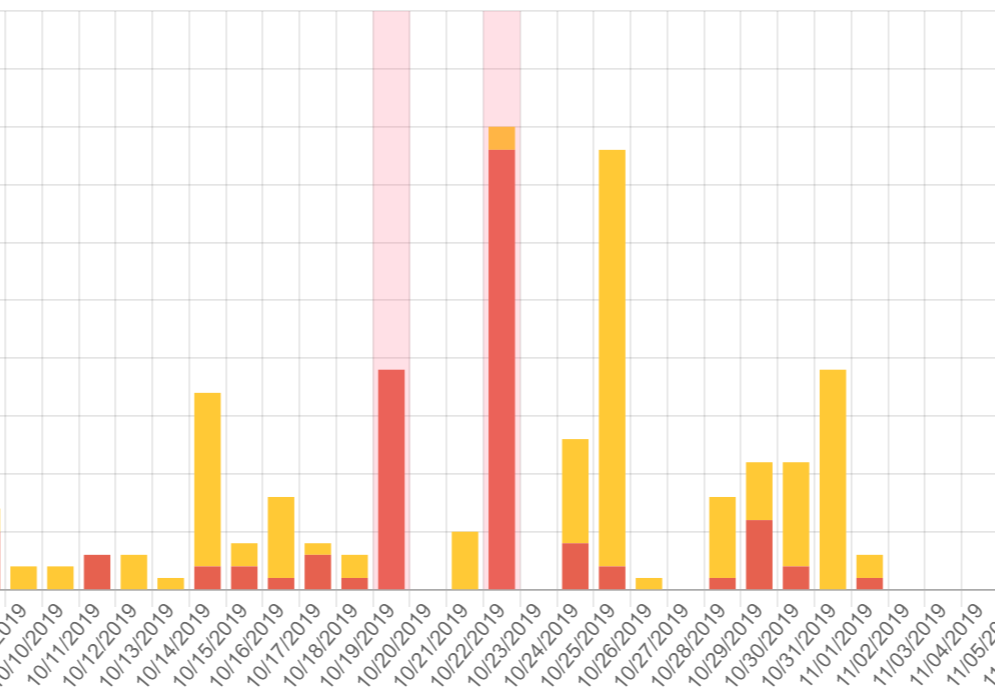
如图所示有红色背景色的条形表明了发生异常。在 2019 年 10 月 19 日之前的错误计数,每天只发生了几例,而当天会突然达到峰值。当修复系统后系统正常运行了两天,不过由于引入了一个新的 Bug 在 2019 年 10 月 22 日又出现一个新的峰值。这个瞬间的峰值反映了系统肯定出现大规模异常。接下来我们就通过 ML.NET 来实现对峰值的识别。
首先安装以下 NuGet 包:
Install-Package Microsoft.ML
Install-Package Microsoft.ML.TimeSeries
Microsoft.MLMicrosoft.ML.TimeSeries 包含时间序列数据的相关对象。
var mlContext = new MLContext();
为了快速示例,我将模拟包含峰值的输入数据如下:
var counts = new[] { 0, 1, 1, 0, 2, 1, 0, 0, 1, 1, 50, 0, 1, 0, 2, 1, 0, 1 };
50这个值很突出的代表了峰值。接下来我们定义一个强类型对象作为输入模型:
class Input { public float Count { get; set; } }
与输入一样,定义一个强类型输出模型:
class Output { [VectorType(3)] public double[] Prediction { get; set; } }
用 VectorType 标注了预测数据为 3 个元素的双精度类型的数组。
接下来,我们定义评估器对象,可用于分析模型的效果:
var estimator = mlContext.Transforms.DetectIidSpike( nameof(Output.Prediction), nameof(Input.Count), confidence:99, pvalueHistoryLength:counts.Length / 4);
DetectIidSpike 方法有 4 个参数,输入属性的名称、输出属性的名称,置信度、峰值出现范围,一般会将范围设置为输入长度的四分之一。
最后,生成转换对象,创建预训练模型,只是这个模型不需要训练,所以传入空数组:
ITransformer transformer = estimator.Fit(mlContext.Data.LoadFromEnumerable(new List<Input>()));
有了模型,我们处理用于预测的输入数据:
var input = counts.Select(x => new Input { Count = x }); IDataView transformedData = transformer.Transform(mlContext.Data.LoadFromEnumerable(input));
最后一步获取预测结果:
var predictions = mlContext.Data.CreateEnumerable<Output>(transformedData, false);
在此步骤中,我们用循环输出每一个预测数据的结果:
foreach (var p in predictions) { Console.WriteLine($"{p.Prediction[0]} {p.Prediction[1]} {p.Prediction[2]}"); }
在这里,你会看到输出预测中每行都是一个包含3个浮点数的数组:
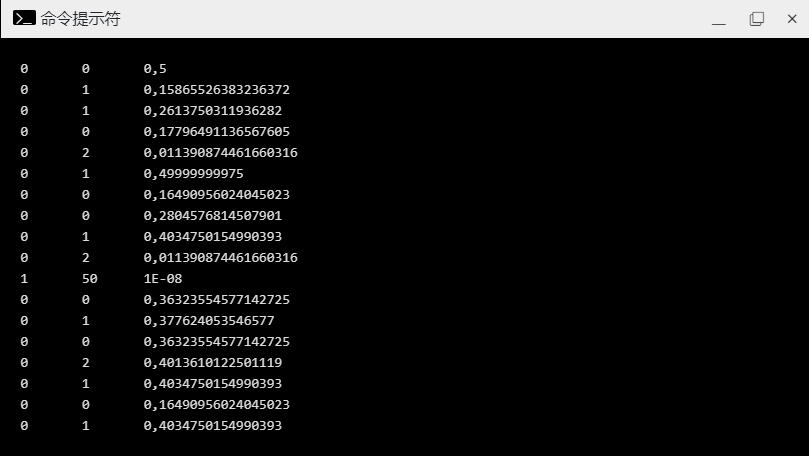
第一列是一个bool值,指示该行是否为峰值。0 表示不是峰值,第二列是原始输入,第三列是逗号分隔的置信值。
以下是到目前为止的完整代码:
var counts = new[] { 0, 1, 1, 0, 2, 1, 0, 0, 1, 1, 50, 0, 1, 0, 2, 1, 0, 1 }; var mlContext = new MLContext(); var estimator = mlContext.Transforms.DetectIidSpike(nameof(Output.Prediction), nameof(Input.Count), confidence:99, pvalueHistoryLength:counts.Length / 4); ITransformer transformer = estimator.Fit(mlContext.Data.LoadFromEnumerable(new List<Input>())); var input = counts.Select(x => new Input { Count = x }); IDataView transformedData = transformer.Transform(mlContext.Data.LoadFromEnumerable(input)); var predictions = mlContext.Data.CreateEnumerable<Output>(transformedData, false); foreach (var p in predictions) { Console.WriteLine($"{p.Prediction[0]} {p.Prediction[1]} {p.Prediction[2]}"); }
乍一看,代码可能看起来有点啰嗦。主要是 ML.NET 无论训练模型与否,管道几乎相同的。
我们再试试改一下 confidence 设置。看看会发生什么:
var estimator = mlContext.Transforms.DetectIidSpike( nameof(Output.Prediction), nameof(Input.Count), confidence:95, pvalueHistoryLength:counts.Length / 4);
对于相同的输入,预测现在如下所示:
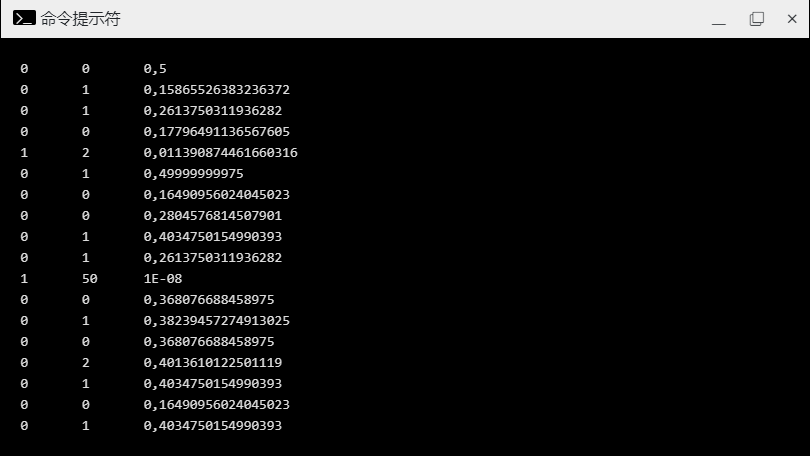
注意到区别了吗?第五行现在也标记为峰值。
我们将输入值更改为以下内容:
var counts = new[] { 1, 3, 0, 4, 5, 5, 4, 3, 3, 0, 13, 8, 1, 61, 21, 40, 7, 7, 5, 6, 8, 33, 11, 5, 2, 10, 11, 18, 14, 23, 8, 17, 15, 13, 24, 29, 15, 20, 29, 19, 18, 17, 23, 47, 7, 14, 26, 28, 5, 22, 47, 22, 20, 9, 40, 6, 8, 4, 10, 10, 1, 4, 27, 3, 3, 7, 6, 12, 8, 3, 1, 2, 0, 0, 2, 0, 2, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 2 };
此时在没有 ML.NET 时就感觉到想要发现异常要困难得多了吧。运行程序后,下面是结果的一部分:
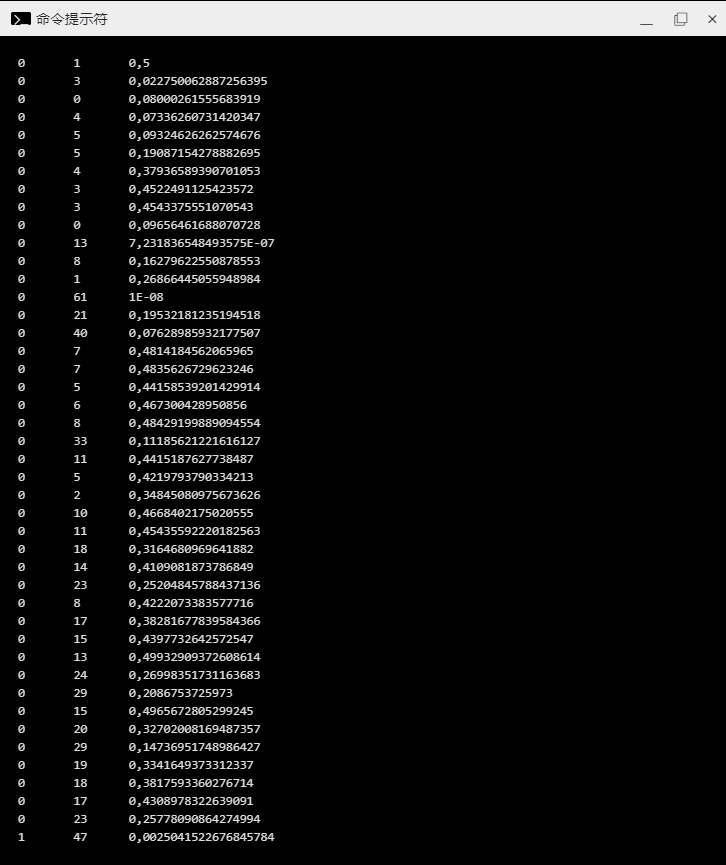
最后一行标记为峰值。但看看第14行绝对看起来像一个异常,ML.NET 似乎有点问题,置信值低于0.05。我们可以稍微处理一下:
if (p.Prediction[2] < (1 - 0.95)) { p.Prediction[0] = 1; }
这虽然有点玩套路,但基本上真的峰值被预测出来,不过弄出了更多不正确的预测。实际上应该在置信度的基础上用额外的二次过滤机制来保证结果倾向于正确:

到目前为止,我们可以使用 ML.NET 来实现机器学习检测异常数据了,这会让我们监控一类的应用更加智能!