Java NIO 入门(二)缓冲区内部细节
概述
本文将介绍 NIO 中两个重要的缓冲区组件:状态变量和访问方法 (accessor)。
状态变量是前一文中提到的"内部统计机制"的关键。每一个读/写操作都会改变缓冲区的状态。通过记录和跟踪这些变化,缓冲区就可能够内部地管理自己的资源。
在从通道读取数据时,数据被放入到缓冲区。在有些情况下,可以将这个缓冲区直接写入另一个通道,但是在一般情况下,您还需要查看数据。这是使用访问方法get()来完成的。同样,如果要将原始数据放入缓冲区中,就要使用访问方法put()。
在本节中,您将学习关于 NIO 中的状态变量和访问方法的内容。我们将描述每一个组件,并让您有机会看到它的实际应用。虽然 NIO 的内部统计机制初看起来可能很复杂,但是您很快就会看到大部分的实际工作都已经替您完成了。您可能习惯于通过手工编码进行簿记 ― 即使用字节数组和索引变量,现在它已在 NIO 中内部地处理了。
状态变量
可以用三个值指定缓冲区在任意时刻的状态:
-
position
-
limit
-
capacity
这三个变量一起可以跟踪缓冲区的状态和它所包含的数据。我们将在下面的小节中详细分析每一个变量,还要介绍它们如何适应典型的读/写(输入/输出)进程。在这个例子中,我们假定要将数据从一个输入通道拷贝到一个输出通道。
1.Position
您可以回想一下,缓冲区实际上就是美化了的数组。在从通道读取时,您将所读取的数据放到底层的数组中。 position 变量跟踪已经写了多少数据。更准确地说,它指定了下一个字节将放到数组的哪一个元素中。因此,如果您从通道中读三个字节到缓冲区中,那么缓冲区的position 将会设置为3,指向数组中第四个元素。
同样,在写入通道时,您是从缓冲区中获取数据。 position 值跟踪从缓冲区中获取了多少数据。更准确地说,它指定下一个字节来自数组的哪一个元素。因此如果从缓冲区写了5个字节到通道中,那么缓冲区的 position 将被设置为5,指向数组的第六个元素。
2.Limit
limit 变量表明还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。
position 总是小于或者等于 limit。
3.Capacity
缓冲区的 capacity 表明可以储存在缓冲区中的最大数据容量。实际上,它指定了底层数组的大小 ― 或者至少是指定了准许我们使用的底层数组的容量。
limit 决不能大于 capacity。
我们首先观察一个新创建的缓冲区。出于本例子的需要,我们假设这个缓冲区的总容量为8个字节。 Buffer 的状态如下所示:

回想一下 ,limit 决不能大于 capacity,此例中这两个值都被设置为 8。我们通过将它们指向数组的尾部之后(如果有第8个槽,则是第8个槽所在的位置)来说明这点。

position 设置为0。如果我们读一些数据到缓冲区中,那么下一个读取的数据就进入 slot 0 。如果我们从缓冲区写一些数据,从缓冲区读取的下一个字节就来自 slot 0 。 position 设置如下所示:

由于 capacity 不会改变,所以我们在下面的讨论中可以忽略它。
第一次读取
现在我们可以开始在新创建的缓冲区上进行读/写操作。首先从输入通道中读一些数据到缓冲区中。第一次读取得到三个字节。它们被放到数组中从 position 开始的位置,这时 position 被设置为 0。读完之后,position 就增加到 3,如下所示:

limit 没有改变。
第二次读取
在第二次读取时,我们从输入通道读取另外两个字节到缓冲区中。这两个字节储存在由 position 所指定的位置上, position 因而增加 2:

limit 没有改变。
flip
现在我们要将数据写到输出通道中。在这之前,我们必须调用 flip() 方法。这个方法做两件非常重要的事:
-
它将 limit 设置为当前 position。
-
它将 position 设置为 0。
前一小节中的图显示了在 flip 之前缓冲区的情况。下面是在 flip 之后的缓冲区:

我们现在可以将数据从缓冲区写入通道了。 position 被设置为 0,这意味着我们得到的下一个字节是第一个字节。limit 已被设置为原来的 position,这意味着它包括以前读到的所有字节,并且一个字节也不多。
第一次写入
在第一次写入时,我们从缓冲区中取四个字节并将它们写入输出通道。这使得 position 增加到 4,而 limit 不变,如下所示:
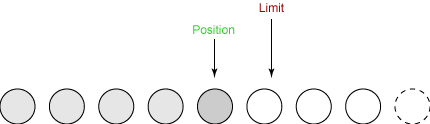
第二次写入
我们只剩下一个字节可写了。 limit在我们调用 flip() 时被设置为 5,并且 position 不能超过 limit。所以最后一次写入操作从缓冲区取出一个字节并将它写入输出通道。这使得 position 增加到 5,并保持 limit 不变,如下所示:
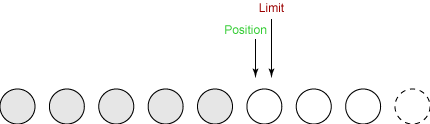
clear
最后一步是调用缓冲区的 clear() 方法。这个方法重设缓冲区以便接收更多的字节。 Clear 做两种非常重要的事情:
-
它将 limit 设置为与 capacity 相同。
-
它设置 position 为 0。
下图显示了在调用 clear() 后缓冲区的状态:

缓冲区现在可以接收新的数据了。
访问方法
到目前为止,我们只是使用缓冲区将数据从一个通道转移到另一个通道。然而,程序经常需要直接处理数据。例如,您可能需要将用户数据保存到磁盘。在这种情况下,您必须将这些数据直接放入缓冲区,然后用通道将缓冲区写入磁盘。
或者,您可能想要从磁盘读取用户数据。在这种情况下,您要将数据从通道读到缓冲区中,然后检查缓冲区中的数据。
在本节的最后,我们将详细分析如何使用 ByteBuffer 类的 get() 和 put() 方法直接访问缓冲区中的数据。
get() 方法
ByteBuffer 类中有四个 get() 方法:
-
byte get();
-
ByteBuffer get( byte dst[] );
-
ByteBuffer get( byte dst[], int offset, int length );
-
byte get( int index );
第一个方法获取单个字节。第二和第三个方法将一组字节读到一个数组中。第四个方法从缓冲区中的特定位置获取字节。那些返回 ByteBuffer的方法只是返回调用它们的缓冲区的 this 值。
此外,我们认为前三个 get() 方法是相对的,而最后一个方法是绝对的。 相对 意味着 get() 操作服从 limit 和 position 值 ― 更明确地说,字节是从当前 position 读取的,而 position 在 get 之后会增加。另一方面,一个 绝对 方法会忽略 limit 和 position 值,也不会影响它们。事实上,它完全绕过了缓冲区的统计方法。
上面列出的方法对应于 ByteBuffer 类。其他类有等价的 get() 方法,这些方法除了不是处理字节外,其它方面是是完全一样的,它们处理的是与该缓冲区类相适应的类型。
put()方法
ByteBuffer 类中有五个 put() 方法:
-
ByteBuffer put( byte b );
-
ByteBuffer put( byte src[] );
-
ByteBuffer put( byte src[], int offset, int length );
-
ByteBuffer put( ByteBuffer src );
-
ByteBuffer put( int index, byte b );
第一个方法 写入(put) 单个字节。第二和第三个方法写入来自一个数组的一组字节。第四个方法将数据从一个给定的源 ByteBuffer 写入这个 ByteBuffer。第五个方法将字节写入缓冲区中特定的 位置 。那些返回 ByteBuffer 的方法只是返回调用它们的缓冲区的 this 值。
与 get() 方法一样,我们将把 put() 方法划分为 相对 或者 绝对 的。前四个方法是相对的,而第五个方法是绝对的。
上面显示的方法对应于 ByteBuffer 类。其他类有等价的 put() 方法,这些方法除了不是处理字节之外,其它方面是完全一样的。它们处理的是与该缓冲区类相适应的类型。
举一个简单的例子,如下代码所示:
1 // TypesInByteBuffer 2 3 import java.nio.*; 4 5 public class TypesInByteBuffer { 6 static public void main( String[] args) throws Exception { 7 ByteBuffer buffer=ByteBuffer.allocate(64); 8 ByteBuffer buffer2=ByteBuffer.allocate(1024); 9 10 buffer.putInt(30); 11 buffer.putDouble(Math.PI); 12 buffer.flip(); 13 // System.out.println(buffer.getInt()); 14 // System.out.println(buffer.getDouble()); 15 // buffer.clear(); 16 17 buffer2.put(buffer); 18 buffer2.flip(); 19 System.out.println(buffer2.getInt()); 20 System.out.println(buffer2.getDouble()); 21 } 22 }

类型化的 get() 和 put() 方法
除了前些小节中描述的 get() 和 put() 方法, ByteBuffer 还有用于读写不同类型的值的其他方法,如下所示:
-
getByte()
-
getChar()
-
getShort()
-
getInt()
-
getLong()
-
getFloat()
-
getDouble()
-
putByte()
-
putChar()
-
putShort()
-
putInt()
-
putLong()
-
putFloat()
-
putDouble()
事实上,这其中的每个方法都有两种类型 ― 一种是相对的,另一种是绝对的。它们对于读取格式化的二进制数据(如图像文件的头部)很有用。
1 // TypesInByteBuffer 2 3 import java.nio.*; 4 5 public class TypesInByteBuffer { 6 static public void main( String[] args) throws Exception { 7 ByteBuffer buffer=ByteBuffer.allocate(64); 8 9 buffer.putInt(30); 10 buffer.putDouble(Math.PI); 11 buffer.flip(); 12 System.out.println(buffer.getInt()); 13 System.out.println(buffer.getDouble()); 14 buffer.clear(); 15 } 16 }
缓冲区的使用:一个内部循环
下面的内部循环概括了使用缓冲区将数据从输入通道拷贝到输出通道的过程。
1 while (true) { 2 buffer.clear(); 3 int r = fcin.read( buffer ); 4 if (r==-1) { 5 break; 6 } 7 buffer.flip(); 8 fcout.write( buffer ); 9 }
read() 和 write() 调用得到了极大的简化,因为许多工作细节都由缓冲区完成了。 clear() 和 flip() 方法用于让缓冲区在读和写之间切换。