HDFS Federation (读书笔记)
HDFS的架构
HDFS包含两个层次:命名空间管理(Namespace) 和 块/存储管理(Block Storage)。
-
命名空间管理(Namespace)
HDFS的命名空间包含目录、文件和块。命名空间管理是指命名空间支持对HDFS中的目录、文件和块做类似文件系统的创建、修改、删除、列表文件和目录等基本操作。 -
块/存储管理(Block Storage)
在块存储服务中包含两部分工作:块管理和物理存储。这是一个更通用的存储服务。其他的应用可以直接建立在Block Storage上,如HBase,Foreign Namespaces等。- 块管理
- 处理Data Node向Name Node注册的请求,处理datanode的成员关系,处理来自Data Node周期性的心跳。
- 处理来自块的报告信息,维护块的位置信息。
- 处理与块相关的操作:块的创建、删除、修改及获取块信息。
- 管理副本放置(replica placement)和块的复制及多余块的删除。
- 物理存储
所谓物理存储就是:Data Node把块存储到本地文件系统中,对本地文件系统的读、写。
- 块管理
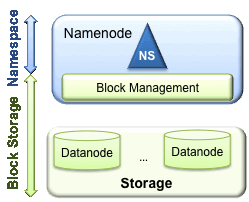
整个HDFS集群中只有一个Namenode,还有一个Backup Namenode。Namenode会实时将变化的HDFS的信息同步给Backup Namenode。Backup Namenode顾名思义是用来做Namenode的备份的。Namenode中命名空间以层次结构组织中存储着文件名和BlockID的对应关系、BlockID和具体Block位置的对应关系。这个单独的Namenode管理着数个Datanode,Block分布在各个Datanode中,每个Datanode会周期性的向此Namenode发送心跳消息,报告自己所在Datanode的使用状态。Block是用来存储数据的最小单元,通常一个文件会存储在一个或者多个Block中,默认Block大小为64MB。
HDFS架构的局限
当前HDFS架构只允许整个集群中存在一个namespace,而该namespace被仅有的一个namenode管理。这个架构使得HDFS非常容易实现,但是,它在具体实现过程中耦合度比较高,进而导致了很多局限性,当然这些局限性只有在拥有规模大集群的公司,像baidu,腾讯等出现。HDFS的局限性主要为:
- Block Storage和namespace高耦合
当前namenode中的namespace和block management的结合使得这两层架构耦合在一起,难以让其他可能namenode实现方案直接使用block storage。 - namenode扩展性
HDFS的底层存储是可以水平扩展的(解释:底层存储指的是datanode,当集群存储空间不够时,可简单的添加机器已进行水平扩展),但namespace不可以。当前的namespace只能存放在单个namenode上,而namenode在内存中存储了整个分布式文件系统中的元数据信息,这限制了集群中数据块,文件和目录的数目。 - 性能
文件操作的性能制约于单个namenode的吞吐量,单个namenode当前仅支持约60K的task,而下一代Apache MapReduce将支持多余100K的并发任务,这隐含着要支持多个namenode。 - 隔离性
现在大部分公司的集群都是共享的,每天有来自不同group的不同用户提交作业。单个namenode难以提供隔离性,即:某个用户提交的负载很大的job会减慢其他用户的job,单一的namenode难以像HBase按照应用类别将不同作业分派到不同namenode上。
HDFS Federation
概述
HDFS Federation是Hadoop最新发布版本Hadoop-0.23.0中为解决HDFS单点故障而提出的namenode水平扩展方案。该方案允许HDFS创建多个namespace以提高集群的扩展性和隔离性。采用Federation的最主要原因是简单,Federation能够快速的解决了大部分单Namenode的问题。
HDFS Federation架构
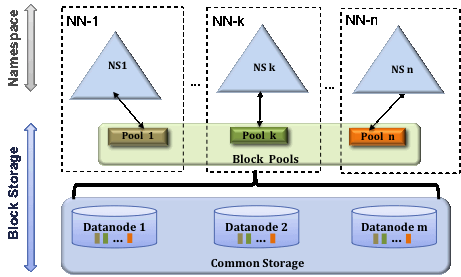
为了水平扩展namenode,federation使用了多个独立的namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
一个block pool由属于同一个namespace的数据块组成,每个datanode可能会存储集群中所有block pool的数据块。
每个block pool内部自治,也就是说各自管理各自的block,不会与其他block pool交流。一个namenode挂掉了,不会影响其他namenode。
某个namenode上的namespace和它对应的block pool一起被称为namespace volume(命名空间卷)。它是管理的基本单位。当一个namenode/nodespace被删除后,其所有datanode上对应的block pool也会被删除。当集群升级时,每个namespace volume作为一个基本单元进行升级。
Federation关键技术点
-
命名空间管理
Federation中存在多个命名空间,如何划分和管理这些命名空间非常关键。在Federation中并采用“文件名hash”的方法,因为该方法的locality非常差,比如:查看某个目录下面的文件,如果采用文件名hash的方法存放文件,则这些文件可能被放到不同namespace中,HDFS需要访问所有namespace,代价过大。为了方便管理多个命名空间,HDFS Federation采用了经典的Client Side Mount Table。

如上图所示,下面四个深色三角形代表一个独立的命名空间,上方浅色的三角形代表从客户角度去访问的子命名空间。各个深色的命名空间Mount到浅色的表中,客户可以访问不同的挂载点来访问不同的命名空间,这就如同在Linux系统中访问不同挂载点一样。这就是HDFS Federation中命名空间管理的基本原理:将各个命名空间挂载到全局mount-table中,就可以做将数据到全局共享;同样的命名空间挂载到个人的mount-table中,这就成为应用程序可见的命名空间视图。 -
Block Pool(块池)
所谓Block pool(块池)就是属于单个命名空间的一组block(块)。每一个datanode为所有的block pool存储块。Datanode是一个物理概念,而block pool是一个重新将block划分的逻辑概念。同一个datanode中可以存着属于多个block pool的多个块。Block pool允许一个命名空间在不通知其他命名空间的情况下为一个新的block创建Block ID。同时,一个Namenode失效不会影响其下的datanode为其他Namenode的服务。
当datanode与Namenode建立联系并开始会话后自动建立Block pool。每个block都有一个唯一的标识,这个标识我们称之为扩展的块ID(Extended Block ID)= BlockID+BlockID。这个扩展的块ID在HDFS集群之间都是唯一的,这为以后集群归并创造了条件。
Datanode中的数据结构都通过块池ID(BlockPoolID)索引,即datanode中的BlockMap,storage等都通过BPID索引。
在HDFS中,所有的更新、回滚都是以Namenode和BlockPool为单元发生的。即同一HDFS Federation中不同的Namenode/BlockPool之间没有什么关系。
Hadoop V0.23版本中Block Pool的管理功能依然放在了Namenode中,将来的版本中会将Block Pool的管理功能移动的新的功能节点中。
主要优点
- 扩展性和隔离性
支持多个namenode水平扩展整个文件系统的namespace。可按照应用程序的用户和种类分离namespace volume,进而增强了隔离性。 - 通用存储服务
Block Pool抽象层为HDFS的架构开启了创新之门。分离block storage layer使得:- 新的文件系统(non-HDFS)可以在block storage上构建
- 新的应用程序(如HBase)可以直接使用block storage层
- 分离的block storage层为将来完全分布式namespace打下基础
- 设计简单
Federation 整个核心设计实现大概用了4个月。大部分改变是在Datanode、Config和Tools中,而Namenode本身的改动非常少,这样 Namenode原先的鲁棒性不会受到影响。虽然这种实现的扩展性比起真正的分布式的Namenode要小些,但是可以迅速满足需求,另外Federation具有良好的向后兼容性,已有的单Namenode的部署配置不需要任何改变就可以继续工作
HDFS Federation不足
- 单点故障问题
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。 - 负载均衡问题
HDFS Federation采用了Client Side Mount Table分摊文件和负载,该方法更多的需要人工介入已达到理想的负载均衡。
引用资料
http://zh.hortonworks.com/blog/an-introduction-to-hdfs-federation/
http://dongxicheng.org/mapreduce/hdfs-federation-introduction/
http://blog.csdn.net/strongerbit/article/details/7013221/
注:本博客引用了上面的博客内容,如有侵权,请联系博主。