TCP提供可靠的运输层。它使用的方法之一就是确认从另一端收到的数据。但数据和确认都有可能会丢失,如果网络上的延时突然增加,就可能导致丢包,如果TCP只进行重传丢失的报文,则会导致网络的负担更重,所以TCP就使用拥塞控制机制来处理拥塞问题,拥塞控制主要有四个算法:1.慢启动 2.拥塞避免 3.快速重传 4.快速恢复
在此之前需要介绍一下TCP的滑动窗口机制:
首先由三次握手中接收端通告这个窗口,这个窗口用来接受端告诉发送端自己还有多少缓冲区可以接受数据,于是发送端就可以根据这个这个通告窗口来发送数据,其中得窗口的左右边沿的活动存在三种描述 ①:窗口合拢 ②窗口张开 ③窗口收缩
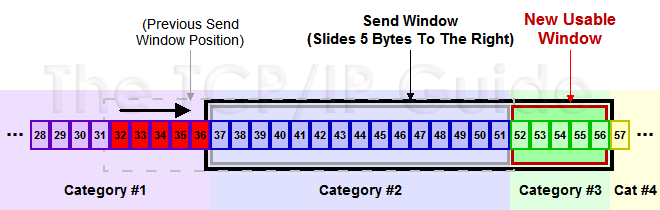
下图就是发送方的滑动窗口示意图

发送方的滑动窗口示意图
上图中分成了四个部分,分别是:(其中那个黑模型就是滑动窗口)
#1已收到ack确认的数据。
#2已经发出去,但是还没收到ack的。
#3在窗口中还没有发出的(接收方还有空间)。
#4还不能发送(接收方没空间)
下面是个滑动后的示意图(收到36的ack,并发出了46-51的字节):
下面我们来看一个接受端控制发送端的图示:
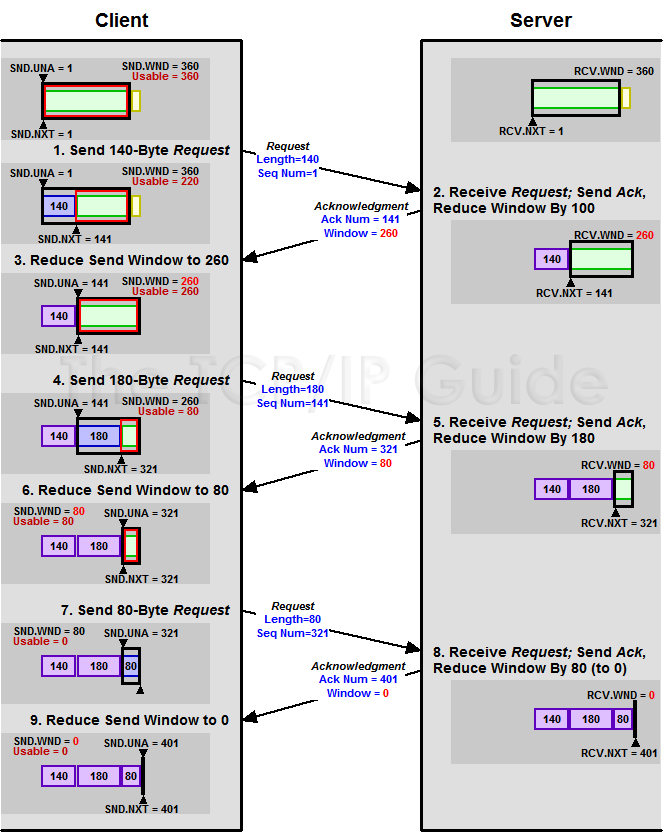
TCP的滑动窗口机制依赖于发送端和接口端进行流速的调整,但是还要考虑到网络传输过程中的拥堵情况
下面介绍TCP的拥塞处理
1.慢启动
如果发送方一开始便向网络中发送多个报文段,直至达到接收方通告的窗口大小为止。但是如果发送方与接收方之间存在多个路由器或者速率较慢的链路的时候,就会发送拥塞。所以建立了新的连接后,发送方不能一开始就发送大量数据,只能逐步增加发送的数据量,以免发送拥塞。慢启动为发送方的TCP增加了另一个窗口:拥塞窗口(congestion window),记为cwnd。当与另一个网络的主机建立TCP连接时,拥塞窗口被初始化为1个报文段(即另一端通告的报文段大小)。每收到一个ACK,拥塞窗口就增加一个报文段( cwnd以字节为单位,但是慢启动以报文段大小为单位进行增加)。发送方取拥塞窗口与通告窗口中的最小值作为发送上限。拥塞窗口是发送方使用的流量控制,而通告窗口则是接收方使用的流量控制,通过接收方的可用缓存大小来控制发送方可以发送多少报文。前者是发送方感受到的网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关,这样持续增加拥塞窗口,拥塞窗口开的太大,势必发生拥塞,所以需要一个慢启动阈值(慢启动门限)超过这个阈值就要进入拥塞避免阶段
慢启动的算法如下:
1)连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
2)每当收到一个ACK,cwnd++; 呈线性上升
3)每当过了一个RTT,cwnd = cwnd*2; 呈指数让升(RTT就是一个数据报从发出去到回来的时间)
4)还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会
进入拥塞避免算法
2.拥塞避免
这里存在一个慢启动门限ssthresh,对于一个给定的连接,ssthresh为65535字节,当cwnd达到ssthresh就会进入拥塞避免阶段。当cwnd达到这个值时后就会如此处理:
1)收到一个ACK时,cwnd = cwnd + 1/cwnd
2)当每过一个RTT时,cwnd = cwnd + 1
这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。很明显,是一个线性上升的算法。我们希望在一个往返时间内最多为cwnd增加1个报文段,(不管在这个RTT中收到了多少个ACK),拥塞避免阶段其实也是在增加拥塞窗口,只不过比慢启动的增长更慢了。如果发生丢包,该如何处理呢,丢包有两种情况:①定时器超时 ②收到3个或者3个以上的重复ACK对于情况①:ssthresh会被设置为拥塞窗口的一半,然后拥塞窗口重置为1,再进入慢启动流程TCP认为这种情况太糟糕,反应也很强烈。对于情况②,就需要使用快速恢复算法
3. 快速重传与快速恢复
快速重传
如果接受方一连串的收到3个或者3个以上的重复ACK,就非常有可能是一个报文段丢失了,那么发送端就重传丢失的报文,并不用等待定时器超时,在收到重复ACK后,将ssthresh会被设置为拥塞窗的一半。然后进入快速恢复阶段。算法如下:
1)cwnd = cwnd /2
2)sshthresh = cwnd
3)进入快速恢复算法——Fast Recovery
这里为什么说收到3个或者3个以上的重复ACK,就非常可能有一个报文段丢失了?比如说发送端发了1,2,3,4,5一共五份数据,接收端收到了1,2,于是回ack 3,然后收到了4(注意此时3没收到),这里不会回ack 4,还是选择回ack 3,这里只能确认最大连续收到的包。这样收到连续收到3次相同的ack,就不等待超时,直接重传丢失的报文
快速恢复
可以收到3个重复的ack,说明网络也不差,至少被丢的包后续的包收到了。所以不需要像RTO(Retransmission TimeOut 重传超时时间)超时那样把拥塞窗口设置为1,这样处理就进入了慢启动,窗口又要从1开始增加了。在快速恢复之前,cwnd和sshthresh已经设置过了。即cwnd变为以半,阈值变为cwnd一样大。然后进入快速恢复阶段:
1)cwnd = sshthresh + 3 * MSS (3的意思是确认有3个数据包被收到了)
2)重传Duplicated ACKs指定的数据包
3)每次收到duplicated Acks,那么cwnd = cwnd +1并发送一个1个分组(如果新的cwnd允许发送)
4)如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法了(这里因为cwnd
已经等于阈值了,再增加超过了)