1.理解分类与监督学习、聚类与无监督学习。
简述分类与聚类的联系与区别。
简述什么是监督学习与无监督学习。
答:
(1)分类和聚类:
联系:分类和聚类都是把每一条记录归应到对应的类别,对于想用分析的目标点,都会在数据集钟寻找离它最近的点,即二者都用到了NN算法。
区别:
①分类的目的是为了确定一个点的类别 ,聚类的目的是将一系列点分成若干类,事先是没有类别的,即分类是已知的,聚类是未知的;
②分类是一种监督学习,聚类是一种无监督学习;
③常用算法不同,分类一般用KNN算法,聚类一般用K-Means算法
(2)监督学习:利用已标记的有限训练数据集,通过某种学习策略/方法建立一个模型,实现对新数据/实例的标记(分类)/映射。每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成;目的是分类和回归。
无监督学习:无监督学习是利用无标记的有限数据描述隐藏在未标记数据中的结构/规律。缺乏足够的先验知识,在数据(没有被标记)中发现一些规律;目的是聚类和降维。
2.朴素贝叶斯分类算法 实例
利用关于心脏病患者的临床历史数据集,建立朴素贝叶斯心脏病分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:
–心梗
–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I',饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
上传手工演算过程。
|
|
性别 |
年龄 |
KILLP |
饮酒 |
吸烟 |
住院天数 |
疾病 |
|
1 |
男 |
>80 |
1 |
是 |
是 |
7-14 |
心梗 |
|
2 |
女 |
70-80 |
2 |
否 |
是 |
<7 |
心梗 |
|
3 |
女 |
70-81 |
1 |
否 |
否 |
<7 |
不稳定性心绞痛 |
|
4 |
女 |
<70 |
1 |
否 |
是 |
>14 |
心梗 |
|
5 |
男 |
70-80 |
2 |
是 |
是 |
7-14 |
心梗 |
|
6 |
女 |
>80 |
2 |
否 |
否 |
7-14 |
心梗 |
|
7 |
男 |
70-80 |
1 |
否 |
否 |
7-14 |
心梗 |
|
8 |
女 |
70-80 |
2 |
否 |
否 |
7-14 |
心梗 |
|
9 |
女 |
70-80 |
1 |
否 |
否 |
<7 |
心梗 |
|
10 |
男 |
<70 |
1 |
否 |
否 |
7-14 |
心梗 |
|
11 |
女 |
>80 |
3 |
否 |
是 |
<7 |
心梗 |
|
12 |
女 |
70-80 |
1 |
否 |
是 |
7-14 |
心梗 |
|
13 |
女 |
>80 |
3 |
否 |
是 |
7-14 |
不稳定性心绞痛 |
|
14 |
男 |
70-80 |
3 |
是 |
是 |
>14 |
不稳定性心绞痛 |
|
15 |
女 |
<70 |
3 |
否 |
否 |
<7 |
心梗 |
|
16 |
男 |
70-80 |
1 |
否 |
否 |
>14 |
心梗 |
|
17 |
男 |
<70 |
1 |
是 |
是 |
7-14 |
心梗 |
|
18 |
女 |
70-80 |
1 |
否 |
否 |
>14 |
心梗 |
|
19 |
男 |
70-80 |
2 |
否 |
否 |
7-14 |
心梗 |
|
20 |
女 |
<70 |
3 |
否 |
否 |
<7 |
不稳定性心绞痛 |
答:

3.使用朴素贝叶斯模型对iris数据集进行花分类。
尝试使用3种不同类型的朴素贝叶斯:
- 高斯分布型
- 多项式型
- 伯努利型
并使用sklearn.model_selection.cross_val_score(),对各模型进行交叉验证。
代码如下:
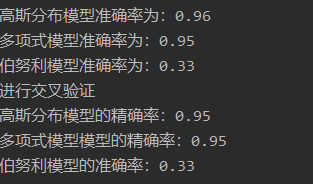
# -*- coding:utf-8 -*- from sklearn.datasets import load_iris #引入sklean的鸢尾花数据集 from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB #引入sklean的高斯贝叶斯,多项式型高斯贝叶斯,伯努利型高斯贝叶斯 from sklearn.model_selection import cross_val_score #引入sklean的交叉验证分数 # 引入鸢尾花数据集 iris = load_iris() data = iris['data'] target = iris['target'] # 高斯分布型 Gnb_model = GaussianNB() # 构建高斯分布模型 Gnb_model.fit(data, target) # 训练模型 Gnb_pre = Gnb_model.predict(data) # 预测模型 print("高斯分布模型准确率为:%.2F" % (sum(Gnb_pre == target) / len(data))) # 多项式型 Mnb_model = MultinomialNB() # 构建多项式模型 Mnb_model.fit(data, target) # 训练模型 Mnb_pre = Mnb_model.predict(data) # 预测模型 print("多项式模型准确率为:%.2F" % (sum(Mnb_pre == target) / len(data))) # 伯努利型 Bnb_model = BernoulliNB() # 构建伯努利模型 Bnb_model.fit(data, target) # 训练模型 Bnb_pre = Bnb_model.predict(data) # 预测模型 print("伯努利模型准确率为:%.2F" % (sum(Bnb_pre == target) / len(data))) print("进行交叉验证:") # 进行交叉验证 Gnb_score = cross_val_score(Gnb_model, data, target, cv=10) print('高斯分布模型的精确率:%.2F' % Gnb_score.mean()) Mnb_score = cross_val_score(Mnb_model, data, target, cv=10) print('多项式模型模型的精确率:%.2F' % Mnb_score.mean()) Bnb_score = cross_val_score(Bnb_model, data, target, cv=10) print('伯努利模型的准确率:%.2F' % Bnb_score.mean())
运行结果: