一直在寻找如何存储大数据的解决办法,碰巧在技术网站上了解到了Clickhouse,能支撑几十亿甚至百亿以上的数据量,顿时我觉得有必要去部署一套用用。
clickhouse是存入数据的,但是还缺少监听mysql的工具,让binlog变化存入到clickhouse中。试了下clickhouse自带的MaterializeMySQL,不支持json,刚好我用到了,尴尬!不然这个就是最简单的方式,直接clickhouse内置的cdc就解决了。
后来了解到了多款cdc框架,最后选择了用Debezium。
接下来是使用kafka和zookeeper作为中间件,接收和转发数据。在了解的过程中又发现了confluent,包含了kafka和zookeeper,于是愉快的选择了confluent。
环境信息:
Centos:6.10
Mysql:5.7
confluent: 6.0.0
实现功能:
目前是只支持数据的插入,不会修改和删除
一、mysql配置
1.配置mysql的配置,在[mysqld] 下面添加或启用如下配置
[mysqld] server-id = 223344 log_bin = mysql-bin binlog_format = row binlog_row_image = full expire_logs_days = 10
然后重启Mysql
创建数据库和表
CREATE DATABASE `test` CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `age` int(10) unsigned zerofill NOT NULL PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
二、安装配置confluent(注:以下是单机模式部署)(Centos)
1.下载confluent https://www.confluent.io/download/
2.配置confluent的环境变量 (/etc/profile 或者 ~/.bashrc)
export CONFLUENT_HOME=/datadisk/conflunt/confluent-6.0.0 export PATH=$PATH:$CONFLUENT_HOME/bin
3.启动confluent
confluent local services start
显示如下信息(注:不知为啥,我每次都要多次执行启动,才能顺序启动完下列服务)
ZooKeeper is [UP]
Kafka is [UP]
Schema Registry is [UP]
Kafka REST is [UP]
Connect is [UP]
ksqlDB Server is [UP]
Control Center is [UP]
4.在confluent目录下的etc文件夹下,创建kafka-connect-debezium目录,并在新建的目录下创建文件register-mysql.json
{ "name":"test-connector", "config":{ "connector.class":"io.debezium.connector.mysql.MySqlConnector", "tasks.max":"1", "database.hostname":"127.0.0.1", "database.port":"3306", "database.user":"root", "database.password":"123456", "database.server.id":"1", "database.server.name":"testserver2", "database.whitelist":"test", "database.history.kafka.bootstrap.servers":"localhost:9092", "database.history.kafka.topic":"schema-changes.test", "transforms":"unwrap,changetopic,dropFieldBefore", "transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState", "transforms.changetopic.type":"org.apache.kafka.connect.transforms.RegexRouter", "transforms.changetopic.regex":"(.*)", "transforms.changetopic.replacement":"$1-smt", "transforms.dropFieldBefore.type":"org.apache.kafka.connect.transforms.ReplaceField$Value", "transforms.dropFieldBefore.blacklist":"before" } }
以上配置是用于连接数据库,并监听数据库test,然后写入kafka。其中transforms是用于转换数据格式。
5.安装mysql connector,具体可查看https://docs.confluent.io/current/connect/debezium-connect-mysql/index.html
confluent-hub install debezium/debezium-connector-mysql:latest
6.启动连接,在register-mysql.json所在的目录,直接执行:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @register-mysql.json
就创建了与Mysql的连接
7.启动kafka消费者监听
kafka-avro-console-consumer --topic testserver2.test.user-smt --bootstrap-server 127.0.0.1:9092 --from-beginning
其中testserver2.test.user-smt可以通过如下命令查看:
kafka-topics --list --zookeeper localhost:2181
8.测试
根据第8步中配置的,在已存在的user表中插入数据,就可以看到有数据打印
{"id":1,"name":{"string":"awen"},"age":10}
到这里confluent就配置好了
三、安装、配置clickhouse
1.安装clickhouse (Centos)参考https://www.cnblogs.com/gomysql/p/11199856.html
curl -s https://packagecloud.io/install/repositories/altinity/clickhouse/script.rpm.sh | sudo bash yum install -y clickhouse-server clickhouse-client clickhouse-server
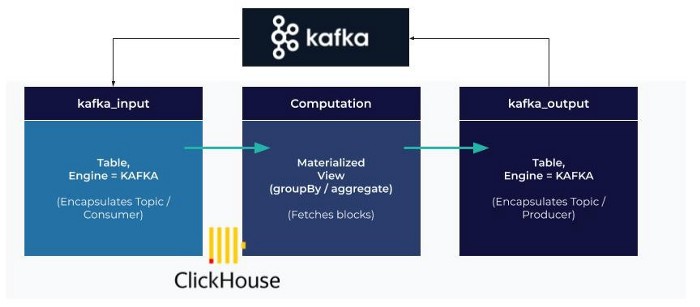
2.创建监听kafka的表
启动clickhouse-client:
CREATE TABLE queue (id UInt64, name Nullable(String), age UInt64) ENGINE = Kafka SETTINGS kafka_broker_list='localhost:9092', kafka_topic_list='testserver2.test.user-smt', kafka_group_name ='group1', kafka_format='AvroConfluent', format_avro_schema_registry_url = 'http://localhost:8081/subjects/testserver2.test.user-smt-value/versions/latest';
(注queue表就是消费kafka的消息,不会存储)
format_avro_schema_registry_url 内容可以根据下面命令查找(jq是json格式化工具):
curl --silent -X GET http://localhost:8081/subjects/ | jq .
创建接收的表
CREATE TABLE user (id UInt64, name Nullable(String), age UInt64) ENGINE = MergeTree() order by id ;
创建MATERIALIZED VIEW,将queue中的数据消费,并存储到user表中
CREATE MATERIALIZED VIEW queue_consumer TO user as select * from queue;
当mysql表中数据变化,使用clickhouse-client查询user表:
ecs-15d4.novalocal :) select * from user;
SELECT * FROM user
┌─id─┬─name─┬─age─┐
│ 7 │ ggg │ 21 │
└───┴──────┴────┘
1 rows in set. Elapsed: 0.005 sec.
至此就配置完成了整个流程。
参考: