数据结构与算法
什么是数据结构
- 数据项:一个数据元素可以由若干数据项组成
- 数据对象:由相同性质的数据元素的集合,是数据子集
- 数据结构:相互之间存在的一种或多种特定关系数据元素的结合
逻辑结构和物理结构
- 逻辑结构:是指数据对象中数据元素之间的相互关系
- 集合结构
- 线性结构
- 树形结构
- 图形结构
- 物理结构
- 顺序存储结构
- 链式存储结构
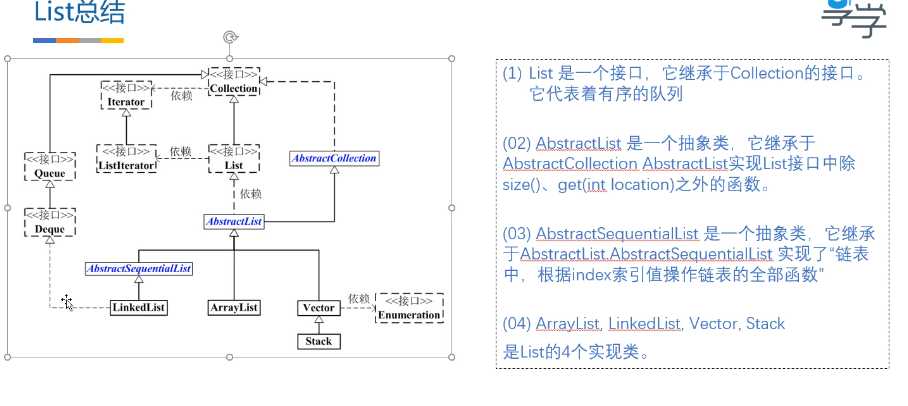
线性表与链表篇
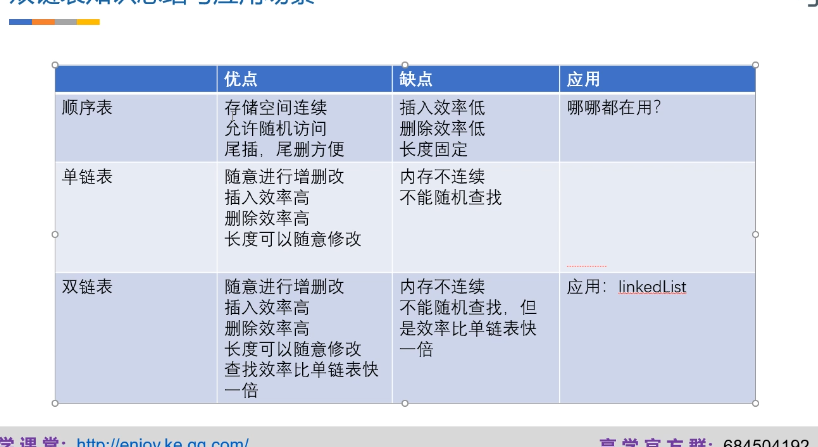
线性表之顺序表

类的关系

什么情况下使用ArrayList?
优点
- 尾插效率高,支持随机访问(内部使用数组)
缺点
- 中间插入或者删除效率低(整个数组进行位移,ararycopy )
应用
- 需要进行排序,不要用ArrayList。linkedlist好用
- 很少的删除操作用 ArrayList
在索引中ArrayList的增加或者删除某个对象的运行 过程?效率很低吗?解释以下为什么?
效率低,因为反复的Arraycopy。耗内存,耗时间
ArrayList如果顺序删除节点?
通过本身的迭代器顺序删除节点
for循环也可以 删除,但必须从尾部开始
ArrayList的遍历方法
next()
foreach()方法
链表
用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。
- 单向链表
- 双向链表
单链表分析

- 随意增加删除,插入效率高,长度可以随意更改
- 内存上不连续,不能随机查找
应用
- 要进行排序,要用LinkedList
双链表分析

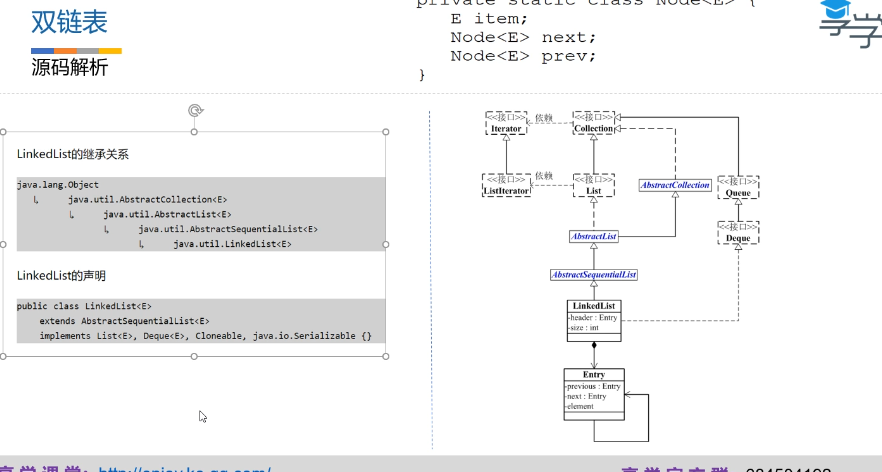
- 删除后孤立的节点会被 JVM自动回收
- 查找速度比单链表快一倍
面试总结
ArrayList和LinkedList有什么区别?
list总结
好文章推荐 内存
什么是内存缓存
预先将数据写到容器(list,map,set)等数据存储单元中,就是内存缓存
链表实现LRU算法
是吗是URL算法
内存缓存淘汰机制
- FIFO (First in First Out)
- LFU(Least Frequently Used) 最不经常使用的
- LRU (Least Recently Used) 最近使用的保留时间长
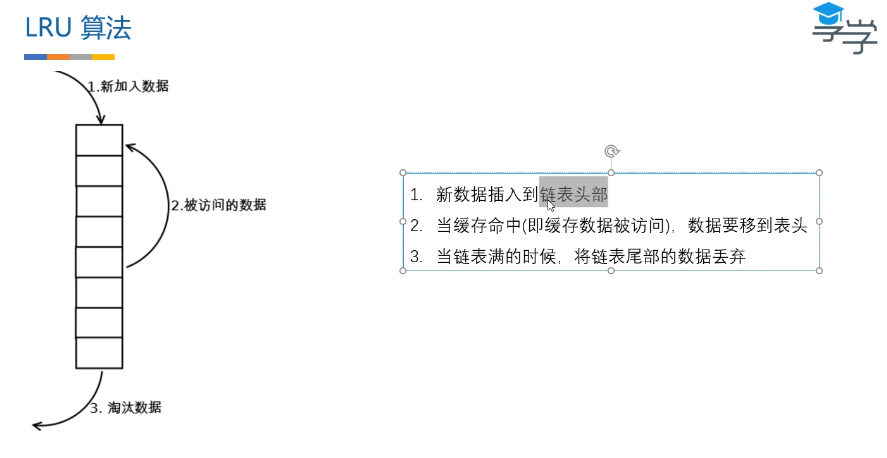
代码实现:
自定义链表:
package 数据结构;
public class LinkedList<T> {
Node list;
int size;//多少个节点
public LinkedList(){
size = 0;
}
//增加节点
//在头部添加
public void put(T data) {
Node head = list;
Node curNode = new Node(data, list);
list = curNode;
size++;
}
//检查Index是否在链表范围以内
public void checkPositionIndex(int index) {
if(!(index>=0&&index<=size)){
throw new IndexOutOfBoundsException("Index:" + index+",size:"+size);
}
}
//在链表index位置插入数据
public void put(int index,T data) {
checkPositionIndex(index);
Node cur = list;
Node head = list;
for(int i = 0; i < index; i++) {
head = cur;
cur = cur.next;
}
Node node = new Node(data, cur);
head.next = node;
size++;
}
//删除节点
//删除头部节点
public T remove(){
if(list != null){
Node node =list;
list = list.next;
node.next = null;//GC回收
size--;
return node.data;
}
return null;
}
public T remove(int index){
checkPositionIndex(index);
Node cur = list;//拿到链表头部
Node head = list;
for(int i = 0;i<index;i++){
head = cur;
cur = cur.next;
}
head.next = cur.next;
cur.next = null;//Gc回收
return cur.data;
}
public T removeLast(){
if(list != null){
Node node = list;
Node cur = list;
while (cur.next != null){
node = cur;
cur = cur.next;
}
node.next = null;
size--;
return cur.data;
}
return null;
}
//修改节点
public void set(int index,T newData){
checkPositionIndex(index);
Node head = list;
for(int i = 0;i<index;i++){
head = head.next;
}
head.data = newData;
}
//查询节点
//get 头节点
public T get(){
Node node =list;
if(node!=null){
return node.data;
}else {
return null;
}
}
public T get(int index){
checkPositionIndex(index);
Node node = list;
for (int i = 0;i < index;i++){
node = node.next;
}
return node.data;
}
//节点信息
class Node{
T data;
Node next;
public Node(T data,Node node) {
this.data = data;
this.next = node ;
}
}
@Override
public String toString() {
Node node = list;
for (int i = 0; i < size; i++) {
System.out.print(node.data + " ");
// System.out.print(" ");
node = node.next;
}
System.out.println();
return super.toString();
}
//LRU添加节点
public void lruPut(T data){
}
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
for(int i = 0; i < 5; i++) {
list.put(i);
}
list.toString();
list.put(3,3);
list.toString();
list.put(8);
list.toString();
System.out.println(list.get(2));
}
}
================================================
4 3 2 1 0
4 3 2 3 1 0
8 4 3 2 3 1 0
3
Lru算法实现
package 数据结构;
public class LruLinkedList<T> extends LinkedList<T> {
int memory_size;// 用于限定内存空间大小,也是缓存的大小
static final int DEFAULT_CAP = 5;
public LruLinkedList(){
memory_size = DEFAULT_CAP;
}
public LruLinkedList(int default_memory_size){
memory_size = default_memory_size;
}
//增加 Lru节点
public void LruPut(T data){
if(size >= memory_size){
removeLast();
put(data);
}else {
put(data);
}
}
//Lru删除
public T Lruremove(){
return removeLast();
}
//lru 访问
public T Lruget(int index){
checkPositionIndex(index);
Node node = list;
Node pre = list;
for (int i = 0; i < index; i++){
pre = node;
node = node.next;
}
T resultData = node.data;
// 将访问的节点移到lisk的表头
pre.next = node.next;
Node head = list;
node.next = head;
list = node;
return resultData;
}
public static void main(String[] args) {
LruLinkedList<Integer> lruLinkedList = new LruLinkedList<>();
for (int i = 0; i<4;i++){
lruLinkedList.put(i);
}
lruLinkedList.toString();
System.out.println(lruLinkedList.Lruget(3));
lruLinkedList.toString();
lruLinkedList.LruPut(20);
lruLinkedList.toString();
lruLinkedList.LruPut(5);
lruLinkedList.toString();
}
}
====================================================
3 2 1 0
0
0 3 2 1
20 0 3 2 1
5 20 0 3 2
队列和栈
Java线程操作


什么是队列
队列又叫先进先出表,一种运算受限的线性表 。
入队叫 队头
出队 叫 队尾
队列做缓存中比较常用
- 队列为空,队头队尾指向同一个节点
- 假移除 队头前面空着(有的走了)队尾满了 到头了(继续增加,发生假溢出)
**循环队列 **

队列存储结构-链式存储
队列的链式存储结构,其实就是线性表的单链表,只不过只能从尾进头出。
作业:实现循环队列
队列的变行
双端队列
优先级队列

栈
手机页面切换等用的就是栈
后进先出表
顺序结构:数组实现
链式结构:链表实现
栈的面试题
Java的Stack是通过Vector来实现的,这种设计被认为是不良的设计,说说你的看法。
vector实现了很多栈不用的方法,例如add[index,object ] 索引插入等,Java程序员偷懒,完全可以自己实现一个
作业:用栈和队列实现逆波兰序列
栈用来存 操作符
队列来存 操作数
JVM内存栈
- StackoverflowError 栈溢出
- 递归的函数调用,容易出现栈溢出。超出了栈的大小
- OutOfMemoryError 堆溢出
栈和堆得区别
- 栈解决了程序的运行问题,即程序如何指向,如何处理数据
- 负责 运算逻辑
- 栈分为栈帧,每个栈帧为 4byt Java中每个引用占一个栈帧(slot)
- 堆解决了数据存储的问题,即数据放在那,怎样放
- 负责存储逻辑
Stack和heap都运行在内存上,在内存空间上字节码指令不必担心不同机器上的区别,所以JVM实现了平台无关性
JVM控制了栈和堆的大小。
深入解刨HashMap
**你不知道而又必须指定的原理 **
ArrayList 基于数组实现的
Hash表 结合了 顺序表和链表
- 用顺序存储数据,保存数据的方式(动态增值,动态删除)
- 链表练习下面节点
顺序表和链表的结合
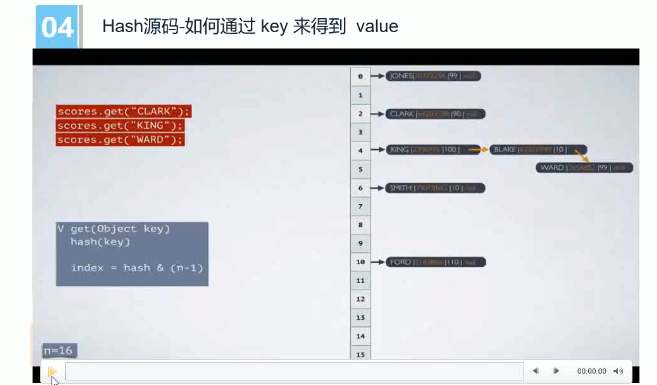
为啥叫Hash表,
- object有一个HachCode函数(永远都是Int类型,目的就是得到一个int类型的Hash值,根据int值求 <key,value>)
- 通过 把key hash得到一个整数型数据,再对table的length求模,得到table 对应得[index] (table是数组),然后得到table[index] 的 value
- 如果key1 key2 key3 相等
- 发生hash冲突
- key1 index1
- key2 index1 存在 key1后面 链表的形式存储。
- key3 index3
- **key的作用就是快速定位 **
- value
- hash把一个 与 int无关的类型转换成了int下标
- hash用作位运算(计算机 位运算 效率最高)
- hashmap也用位运算
往hash表里面添加节点,添加到节点头部
什么是HashMap
key value 键值对
**扩容 **
当 hash表满了 就要 扩容。
加载因子
例子 加载因子=0.75
数组大小 位 16
则当 存储了12 个节点后 就满了
然后就要扩容
threadLocalHashCode
一个线程对应一个ThreadLocalMap
一个map对象多个键值对。
- key 是ThreadLocal
- value是v
多线程必定会用到的,运用了 hashMap的思想
总结:
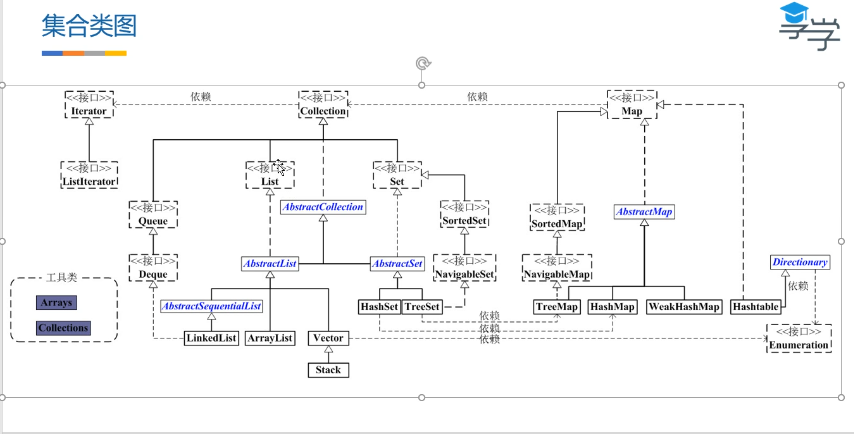
集合总统架构