两篇讲ELMO的好文,mark
from : https://zhuanlan.zhihu.com/p/63115885
and: https://blog.csdn.net/triplemeng/article/details/82380202
介绍
之前的glove以及word2vec的word embedding在nlp任务中都取得了最好的效果,,现在几乎没有一个NLP的任务中不加word embedding。我们常用的获取embedding方法都是通过训练language model,将language model中预测的hidden state做为word的表示,给定N个tokens的序列(t1,t2,...,tn), 前向language model就是通过前k-1个输入序列(t1,t2,...,tk)的hidden表示, 预测第k个位置的token, 反向的language model就是给定后面的序列, 预测之前的。然后将language model的第k个位置的hidden输出做为word embedding。之前的做法的缺点是对于每一个单词都有唯一的一个embedding表示, 而对于多义词显然这种做法不符合直觉, 而单词的意思又和上下文相关, ELMo的做法是我们只预训练language model,而word embedding是通过输入的句子实时输出的, 这样单词的意思就是上下文相关的了,这样就很大程度上缓解了歧义的发生
在此之前的 Word Embedding 本质上是个静态的方式,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的 Word Embedding 不会跟着上下文场景的变化而改变,所以对于比如 Bank 这个词,它事先学好的 Word Embedding 中混合了几种语义,在应用中来了个新句子,即使从上下文中(比如句子包含 money 等词)明显可以看出它代表的是「银行」的含义,但是对应的 Word Embedding 内容也不会变,它还是混合了多种语义。这是为何说它是静态的,这也是问题所在
ELMo用到上文提到的双向的language model,给定N个tokens (t1, t2,…,tN), language model通过给定前面的k-1个位置的token序列计算第k个token的出现的概率:
后向的计算方法与前向相似:
biLM训练过程中的目标就是最大化:
ELMo对于每个token , 通过一个L层的biLM计算出2L+1个表示:
其中 是对token进行直接编码的结果(这里是字符通过CNN编码),
代表
是每个biLSTM层输出的结果。在实验中还发现不同层的biLM的输出的token表示对于不同的任务效果不同.最上面一层的输出
是用softmax来预测下面一个单词
应用中将ELMo中所有层的输出R压缩为单个向量, ,最简单的压缩方法是取最上层的结果做为token的表示:
,更通用的做法是通过一些参数来联合所有层的信息:
其中 是一个softmax出来的结果, γ是一个任务相关的scale参数,我试了平均每个层的信息和学出来
发现学习出来的效果会好很多。 文中提到γ在不同任务中取不同的值效果会有较大的差异, 需要注意, 在SQuAD中设置为0.01取得的效果要好于设置为1时。
文章中提到的Pre-trained的language model是用了两层的biLM, 对token进行上下文无关的编码是通过CNN对字符级进行编码, 然后将三层的输出scale到1024维, 最后对每个token输出3个1024维的向量表示。 这里之所以将3层的输出都作为token的embedding表示是因为实验已经证实不同层的LM输出的信息对于不同的任务作用是不同的, 也就是所不同层的输出捕捉到的token的信息是不相同的。
ELMO 的本质思想是:我事先用语言模型学好一个单词的 Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用 Word Embedding 的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以 ELMO 本身是个根据当前上下文对 Word Embedding 动态调整的思路。
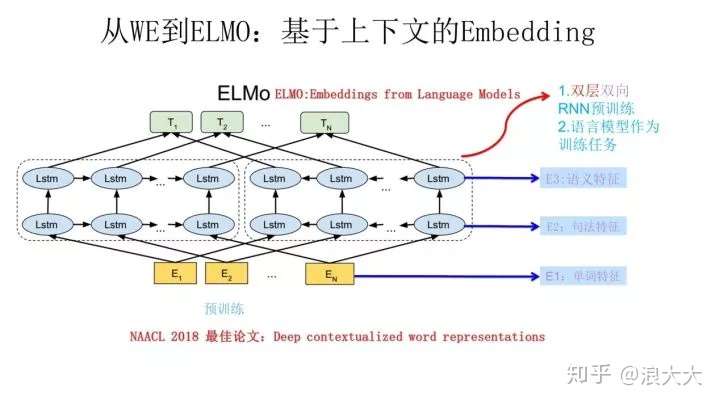
ELMO 采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的 Word Embedding 作为新特征补充到下游任务中。
上图展示的是其预训练过程,它的网络结构采用了双层双向 LSTM,目前语言模型训练的任务目标是根据单词 的上下文去正确预测单词
,
之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外
的上文 Context-before;右端的逆向双层 LSTM 代表反方向编码器,输入的是从右到左的逆序的句子下文 Context-after;每个编码器的深度都是两层 LSTM 叠加。这个网络结构其实在 NLP 中是很常用的。
使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子Snew,句子中每个单词都能得到对应的三个Embedding:最底层是单词的 Word Embedding,往上走是第一层双向LSTM中对应单词位置的 Embedding,这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的 Embedding,这层编码单词的语义信息更多一些。也就是说,ELMO 的预训练过程不仅仅学会单词的 Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。
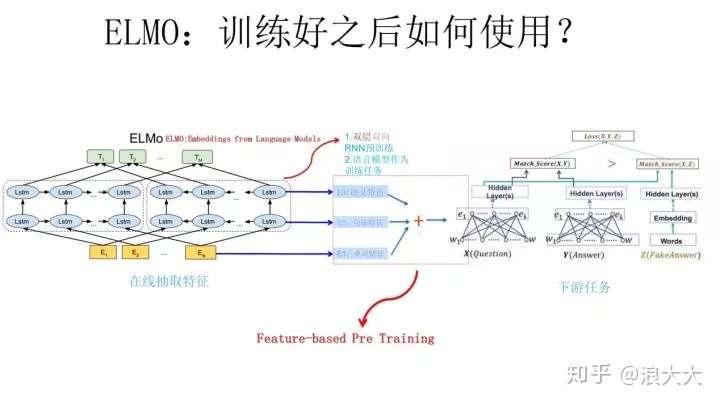
上面介绍的是 ELMO 的第一阶段:预训练阶段。那么预训练好网络结构后,如何给下游任务使用呢?上图展示了下游任务的使用过程,比如我们的下游任务仍然是 QA 问题,此时对于问句 X,我们可以先将句子 X 作为预训练好的 ELMO 网络的输入,这样句子 X 中每个单词在 ELMO 网络中都能获得对应的三个 Embedding,之后给予这三个 Embedding 中的每一个 Embedding 一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个 Embedding 整合成一个。
然后将整合后的这个 Embedding 作为 X 句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。对于上图所示下游任务 QA 中的回答句子 Y 来说也是如此处理。
因为 ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。至于为何这么做能够达到区分多义词的效果,你可以想一想,其实比较容易想明白原因。

上面这个图是 TagLM 采用类似 ELMO 的思路做命名实体识别任务的过程,其步骤基本如上述 ELMO 的思路,所以此处不展开说了。TagLM 的论文发表在 2017 年的 ACL 会议上,作者就是 AllenAI 里做 ELMO 的那些人,所以可以将 TagLM 看做 ELMO 的一个前导工作。

前面我们提到静态 Word Embedding 无法解决多义词的问题,那么 ELMO 引入上下文动态调整单词的 embedding 后多义词问题解决了吗?解决了,而且比我们期待的解决得还要好。
上图给了个例子,对于 Glove 训练出的 Word Embedding 来说,多义词比如 play,根据它的 embedding 找出的最接近的其它单词大多数集中在体育领域,这很明显是因为训练数据中包含 play 的句子中体育领域的数量明显占优导致;而使用 ELMO,根据上下文动态调整后的 embedding 不仅能够找出对应的「演出」的相同语义的句子,而且还可以保证找出的句子中的 play 对应的词性也是相同的,这是超出期待之处。之所以会这样,是因为我们上面提到过,第一层 LSTM 编码了很多句法信息,这在这里起到了重要作用。
ELMO 经过这般操作,效果如何呢?实验效果见上图,6 个 NLP 任务中性能都有幅度不同的提升,最高的提升达到 25% 左右,而且这 6 个任务的覆盖范围比较广,包含句子语义关系判断,分类任务,阅读理解等多个领域,这说明其适用范围是非常广的,普适性强,这是一个非常好的优点。

那么站在现在这个时间节点看,ELMO 有什么值得改进的缺点呢?首先,一个非常明显的缺点在特征抽取器选择方面,ELMO 使用了LSTM而不是新贵 Transformer,Transformer 是谷歌在 17 年做机器翻译任务的“Attention is all you need”的论文中提出的,引起了相当大的反响,很多研究已经证明了 Transformer 提取特征的能力是要远强于LSTM的。如果 ELMO 采取 Transformer 作为特征提取器,那么估计 Bert 的反响远不如现在的这种火爆场面。另外一点,ELMO 采取双向拼接这种融合特征的能力可能比 Bert 一体化的融合特征方式弱,但是,这只是一种从道理推断产生的怀疑,目前并没有具体实验说明这一点。
这篇介绍一下ELMo算法(论文)。按道理应该加入前面的《关于句子embedding的一些工作简介》系列,但是严格来讲,只能说它通过自己产生的word embedding来影响了句子embedding, 所以干脆另写一篇吧。
Introduction
Bidirectional language models
ELMo
Evaluation and Analysis
总结
Introduction
作者认为好的词表征模型应该同时兼顾两个问题:一是词语用法在语义和语法上的复杂特点;二是随着语言环境的改变,这些用法也应该随之改变。作者提出了deep contextualized word representation 方法来解决以上两个问题。
这种算法的特点是:每一个词语的表征都是整个输入语句的函数。具体做法就是先在大语料上以language model为目标训练出bidirectional LSTM模型,然后利用LSTM产生词语的表征。ELMo故而得名(Embeddings from Language Models)。为了应用在下游的NLP任务中,一般先利用下游任务的语料库(注意这里忽略掉label)进行language model的微调,这种微调相当于一种domain transfer; 然后才利用label的信息进行supervised learning。
ELMo表征是“深”的,就是说它们是biLM的所有层的内部表征的函数。这样做的好处是能够产生丰富的词语表征。高层的LSTM的状态可以捕捉词语意义中和语境相关的那方面的特征(比如可以用来做语义的消歧),而低层的LSTM可以找到语法方面的特征(比如可以做词性标注)。如果把它们结合在一起,在下游的NLP任务中会体现优势。
Bidirectional language models
ELMo顾名思义是从Language Models得来的embeddings,确切的说是来自于Bidirectional language models。具体可以表示为:
和
这里的(t1,t2,...,tN)(t1,t2,...,tN)是一系列的tokens
作为语言模型可能有不同的表达方法,最经典的方法是利用多层的LSTM,ELMo的语言模型也采取了这种方式。所以这个Bidirectional LM由stacked bidirectional LSTM来表示。
假设输入是token的表示xLMkxkLM。在每一个位置kk,每一层LSTM上都输出相应的context-dependent的表征h→LMk,jh→k,jLM。这里j=1,...,Lj=1,...,L。顶层的LSTM的输出,h→LMk,Lh→k,LLM,通过Softmax层来预测下一个tokentk+1tk+1。
log likelihood表达如下:
这里的ΘxΘx代表token embedding, ΘsΘs代表softmax layer的参数。
ELMo
对于每一个token,一个L层的biLM要计算出共2L+12L+1个表征:
这里hLMk,jhk,jLM是简写,当j=0j=0时,代表token层。j>0j>0时,同时包括两个方向的h。
在下游的任务中, ELMo把所有层的R压缩在一起形成一个单独的vector。(在最简单的情况下,可以只保留最后一层的hLMk,Lhk,LLM。)
具体来讲如何使用ElMo产生的表征呢?对于一个supervised NLP任务,可以分以下三步:
产生pre-trained biLM模型。模型由两层bi-LSTM组成,之间用residual connection连接起来。
在任务语料上(注意是语料,忽略label)fine tuning上一步得到的biLM模型。可以把这一步看为biLM的domain transfer。
利用ELMo的word embedding来对任务进行训练。通常的做法是把它们作为输入加到已有的模型中,一般能够明显的提高原模型的表现。
印象中太深的NLP方面的模型基本没有,这和Computer Vision领域非常不一样。 当然这也是所解决问题的本质决定: Image的特征提取在人脑里就是从低阶到高阶的过程,深层网络有助于高级特征的实现。对于语言来讲很难定义这样的一个过程,这篇文章的两层biLM加residual connection的架构比较少见(Google的transformor是多层网络+residual connection一个例子)。文章认为低层和高层的LSTM功能有差异:低层能够提取语法方面的信息;高层擅于捕捉语义特征。
Evaluation and Analysis
效果
先看一下在QA,Textual entailment,Semanic role labeling, Coreference resolution, NER, 和 Sentiment analysis上的表现。
和state of art比基本上每个任务都有明显的改善。表中的OUR BASELINE在论文中有详细介绍,它指的是作者选定的某些已有的模型。ELMo+BASELINE指的是作者把ELMo的word representation作为输入提供给选定的模型。这样我们可以清楚的比较在使用和不使用ELMo词嵌入时的效果。
多层和最后一层
公式(1)用各层表征的叠加来代表相应位置的向量,作者在下表中比较了仅仅使用最后一层的效果。
显然多层的叠加效果好于仅使用最后的一层。
最后一列里的λλ代表的是网络参数regularization的大小。结果说明合适的regularization有好处。
存在于输入层和输出层
其实ELMo不仅可以作为下游模型的输入,也可以直接提供给下游模型的输出层。
上表说明有时候同时提供给下游模型的输入和输出层效果更好。
biLM捕捉到的词语信息
ELMo提高了模型的效果,这说明它产生的word vectors捕捉到其他的word vectors没有的信息。直觉上来讲,biLM一定能够根据context区别词语的用法。下表比较了Glove和biLM在play这个多义词上的解释。
对于Glove来说,play的近义词同时涵盖了不同的语法上的用法:动词(playing, played), 名词(players,game)。
但是biLM能够同时区分语法和语义:第一个例子里的play名词,表示击球,第二个例子中play也是名词,表示表演。显然biLM能够在表示词语嵌入时考虑到context的信息。
总结
ELMo在处理很多NLP下游任务中表现非常优异。但是我想这跟它集中在产生更好的词语级别的embedding是有关系的。过去介绍到的一些其他的算法,比如Quick thoughts也是利用了语言模型作为句子的encoder;还有InferSent使用biLSTM作为encoder。和ELMo相比,它们都显得“野心”太大:它们为下游的NLP任务提供了句子embedding的解决方案:即直接利用它们的pretrained encoder,最终的预测无非是加上softmax的classifier。
对比而言ELMo要单纯很多,它只提供了word级别的解决方案:利用它的pretrained biLM来产生word embedding,然后提供给下游的模型。这里的模型往往是sequence model,其效果已经在相应的NLP任务上得到验证。这时有了新的兼具语法语义及环境特征的word embedding的加持,难怪效果会更好。更不要说,ELMo还在任务语料库上小心翼翼的再进行过一轮微调,更是保证了对新domain的adaptation。
关注公众号《没啥深度》有关自然语言处理的深度学习应用,偶尔也有关计算机视觉
---------------------
作者:triplemeng
来源:CSDN
原文:https://blog.csdn.net/triplemeng/article/details/82380202
版权声明:本文为博主原创文章,转载请附上博文链接!