LSH:将向量进行哈希分桶,使得原语义上相似的文本大概率被哈希到同一个桶中,同个桶内的文本可以认为是大概率是相似的。
LSH:局部敏感哈希算法,是一种针对海量高维数据的快速最近邻查找算法,主要有如下用法:
- 全基因组的相关研究:生物学家经常使用 LSH 在基因组数据库中鉴定相似的基因表达。
- 大规模的图片搜索: Google 使用 LSH 和 PageRank 来构建他们的图片搜索技术VisualRank。
- 音频/视频指纹识别:在多媒体技术中,LSH 被广泛用于 A/V 数据的指纹识别。
- 近似重复的检测: LSH 通常用于对大量文档,网页和其他文件进行去重处理。
在推荐系统等应用中,经常会遇到的一个问题就是面临着海量的高维数据,查找最近邻。如果使用线性查找对于高维数据计算量和耗时都是灾难性的。为了解决这样的问题,出现了一种特殊的hash函数,使得2个相似度很高的数据以较高的概率映射成同一个hash值,而令2个相似度很低的数据以极低的概率映射成同一个hash值。我们把这样的函数,叫做LSH(局部敏感哈希)。
局部敏感散列(LSH)是一类重要的散列技术,常用于大数据集的聚类、近似最近邻搜索和异常值检测。 LSH 的总体思路是使用一个函数族(“LSH family”)将数据点散列到桶中,使得彼此靠近的数据点很有可能在同一个桶中,而距离较远的数据点 彼此远离的很可能在不同的桶中。 LSH 家族的正式定义如下:
在度量空间 (M, d) 中,其中 M 是一个集合,d 是 M 上的距离函数,LSH 族是满足以下属性的函数 h 族:
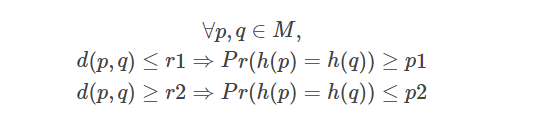
这个 LSH 家族被称为 (r1, r2, p1, p2) 敏感的。
在 Spark 中,不同的 LSH 系列在不同的类中实现(例如 MinHash),并且在每个类中提供了用于特征变换、近似相似连接和近似最近邻的 API。
在 LSH 中,我们将误报定义为一对远处的输入特征(d(p,q)≥r2),它们散列到同一个桶中,我们将误报定义为一对附近的特征(d( p,q)≤r1) 被散列到不同的桶中。
一、LSH Operations
描述了 LSH 可用于的主要操作类型。 拟合的 LSH 模型具有用于这些操作中的每一个的方法。
1.1 Feature Transformation(特征转换)
特征转换是将散列值添加为新列的基本功能。 这对于降维很有用。 用户可以通过设置 inputCol 和 outputCol 来指定输入和输出列名。
LSH 还支持多个 LSH 哈希表。 用户可以通过设置 numHashTables 来指定哈希表的数量。 这也用于近似相似连接和近似最近邻中的 OR-amplification。 增加哈希表的数量会提高准确性,但也会增加通信成本和运行时间。
outputCol 的类型是 Seq[Vector],其中数组的维度等于 numHashTables,向量的维度当前设置为 1。
1.2 Approximate Similarity Join(近似相似连接)
近似相似连接采用两个数据集,并近似返回数据集中距离小于用户定义阈值的行对。 近似相似连接既支持连接两个不同的数据集,也支持自连接。 自连接会产生一些重复的对。
近似相似连接接受转换和未转换的数据集作为输入。 如果使用未转换的数据集,它将自动转换。 在这种情况下,哈希签名将被创建为 outputCol。 在joined dataset中,可以在datasetA和datasetB中查询原始数据集。 距离列将添加到输出数据集中,以显示返回的每对行之间的真实距离。
1.3 Approximate Nearest Neighbor Search(近似最近邻搜索)
近似最近邻搜索采用数据集(特征向量)和键(单个特征向量),它近似返回数据集中与向量最近的指定行数。 近似最近邻搜索接受转换和未转换的数据集作为输入。 如果使用未转换的数据集,它将自动转换。 在这种情况下,哈希签名将被创建为 outputCol。 距离列将添加到输出数据集中,以显示每个输出行与搜索键之间的真实距离。
注意:当哈希桶中没有足够的候选者时,近似最近邻搜索将返回少于 k 行。
二、LSH Algorithms
2.1 Bucketed Random Projection for Euclidean Distance
Bucketed Random Projection 是欧几里得距离的 LSH 系列。 欧几里得距离定义如下:
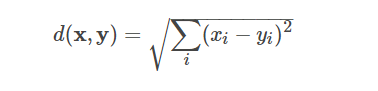
它的 LSH 系列将特征向量 x 投影到随机单位向量 v 上,并将投影结果分成哈希桶:
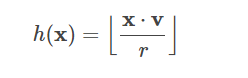
其中 r 是用户定义的桶长度。 桶长度可用于控制哈希桶的平均大小(以及桶的数量)。 更大的桶长度(即更少的桶)会增加特征被散列到同一个桶的概率(增加真假阳性的数量)。
Bucketed Random Projection 接受任意向量作为输入特征,并支持稀疏向量和密集向量。
%spark // 特征处理局部敏感散列 —— —— BucketedRandomProjectionLSH // 输入是密集或稀疏向量,每个向量代表欧几里得距离空间中的一个点。 输出将是可配置维度的向量。 同一维度的哈希值由相同的哈希函数计算得出。 import org.apache.spark.ml.feature.BucketedRandomProjectionLSH import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession import org.apache.spark.sql.functions.col val dfA = spark.createDataFrame(Seq( (0, Vectors.dense(1.0, 1.0)), (1, Vectors.dense(1.0, -1.0)), (2, Vectors.dense(-1.0, -1.0)), (3, Vectors.dense(-1.0, 1.0)) )).toDF("id", "features") val dfB = spark.createDataFrame(Seq( (4, Vectors.dense(1.0, 0.0)), (5, Vectors.dense(-1.0, 0.0)), (6, Vectors.dense(0.0, 1.0)), (7, Vectors.dense(0.0, -1.0)) )).toDF("id", "features") val key = Vectors.dense(1.0, 0.0) val brp = new BucketedRandomProjectionLSH() // 每个哈希桶的长度,较大的桶降低了误报率。 // 桶的数量将是(输入向量的最大 L2 范数)/桶长度。 // 如果输入向量被归一化,1-10 倍 pow(numRecords, -1/inputDim) 将是一个合理的值 .setBucketLength(2.0) // LSH OR-amplification 中使用的哈希表数量的参数。 // LSH OR-amplification 可用于降低假阴性率。 此参数的较高值会降低假阴性率,但会增加计算复杂性。 .setNumHashTables(3) // 随机种子的参数。 // .setSeed() .setInputCol("features") .setOutputCol("hashes") // 拟合数据训练转换器 val model = brp.fit(dfA) // 1、特征转换 println("哈希值存储在“哈希”列中的哈希数据集: ") model.transform(dfA).show(false) // 2、计算输入行的局部敏感哈希,然后执行近似相似性连接。 // 可以通过传入已经转换的数据集来避免计算哈希,例如 `model.approxSimilarityJoin(transformedA,transformedB,1.5)` // approxSimilarityJoin方法:连接两个数据集以近似找到距离小于阈值的所有行对。 如果 outputCol 缺失,该方法将转换数据; 如果 outputCol 存在,它将使用 outputCol。 println("在小于 1.5 的欧几里得距离上近似加入 dfA 和 dfB: ") model.approxSimilarityJoin(dfA, dfB, 1.5, "EuclideanDistance") .select(col("datasetA.id").alias("idA"), col("datasetB.id").alias("idB"), col("EuclideanDistance")).show() // 3、计算输入行的局部敏感哈希,然后执行近似最近邻搜索。 // 可以通过传入已经转换的数据集来避免计算哈希,例如`model.approxNearestNeighbors(transformedA, key, 2)` // 给定一个大数据集和一个项目,大约找到与该项目最近距离的 k 个项目。 如果 outputCol 缺失,该方法将转换数据; 如果 outputCol 存在,它将使用 outputCol。 println("近似搜索 dfA 的 2 个最近邻居: ") model.approxNearestNeighbors(dfA, key, 2).show(false) 输出: 哈希值存储在“哈希”列中的哈希数据集: +---+-----------+-----------------------+ |id |features |hashes | +---+-----------+-----------------------+ |0 |[1.0,1.0] |[[0.0], [0.0], [-1.0]] | |1 |[1.0,-1.0] |[[-1.0], [-1.0], [0.0]]| |2 |[-1.0,-1.0]|[[-1.0], [-1.0], [0.0]]| |3 |[-1.0,1.0] |[[0.0], [0.0], [-1.0]] | +---+-----------+-----------------------+ 在小于 1.5 的欧几里得距离上近似加入 dfA 和 dfB: +---+---+-----------------+ |idA|idB|EuclideanDistance| +---+---+-----------------+ | 1| 4| 1.0| | 0| 6| 1.0| | 1| 7| 1.0| | 3| 5| 1.0| | 0| 4| 1.0| | 3| 6| 1.0| | 2| 7| 1.0| | 2| 5| 1.0| +---+---+-----------------+ 近似搜索 dfA 的 2 个最近邻居: +---+----------+-----------------------+-------+ |id |features |hashes |distCol| +---+----------+-----------------------+-------+ |0 |[1.0,1.0] |[[0.0], [0.0], [-1.0]] |1.0 | |1 |[1.0,-1.0]|[[-1.0], [-1.0], [0.0]]|1.0 | +---+----------+-----------------------+-------+
2.2 MinHash for Jaccard Distance
MinHash 是 Jaccard 距离的 LSH 系列,其中输入特征是自然数集。 两个集合的 Jaccard 距离由它们的交集和并集的基数定义:
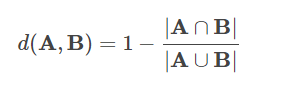
MinHash 将随机散列函数 g 应用于集合中的每个元素,并取所有散列值中的最小值:
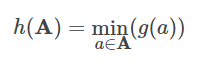
MinHash 的输入集表示为二进制向量,其中向量索引表示元素本身,向量中的非零值表示该元素在集合中的存在。 虽然支持密集和稀疏向量,但通常建议使用稀疏向量以提高效率。 例如 Vectors.sparse(10, Array[(2, 1.0), (3, 1.0), (5, 1.0)]) 表示空间中有 10 个元素。 该集合包含元素 2、元素 3 和元素 5。所有非零值都被视为二进制“1”值。
注意:空集不能被 MinHash 转换,这意味着任何输入向量必须至少有 1 个非零条目。
%spark // 特征处理局部敏感散列 —— —— MinHashLSH // Jaccard 距离的 LSH 类。 // 输入可以是密集或稀疏向量,但如果是稀疏的,则效率更高。 // 例如 Vectors.sparse(10, Array((2, 1.0), (3, 1.0), (5, 1.0))) 表示空间中有 10 个元素。 该集合包含元素 2、3 和 5。此外,任何输入向量必须至少有 1 个非零索引,并且所有非零值都被视为二进制“1”值。 import org.apache.spark.ml.feature.MinHashLSH import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession import org.apache.spark.sql.functions.col val dfA = spark.createDataFrame(Seq( (0, Vectors.sparse(6, Seq((0, 1.0), (1, 1.0), (2, 1.0)))), (1, Vectors.sparse(6, Seq((2, 1.0), (3, 1.0), (4, 1.0)))), (2, Vectors.sparse(6, Seq((0, 1.0), (2, 1.0), (4, 1.0)))) )).toDF("id", "features") val dfB = spark.createDataFrame(Seq( (3, Vectors.sparse(6, Seq((1, 1.0), (3, 1.0), (5, 1.0)))), (4, Vectors.sparse(6, Seq((2, 1.0), (3, 1.0), (5, 1.0)))), (5, Vectors.sparse(6, Seq((1, 1.0), (2, 1.0), (4, 1.0)))) )).toDF("id", "features") val key = Vectors.sparse(6, Seq((1, 1.0), (3, 1.0))) val mh = new MinHashLSH() // LSH OR-amplification 中使用的哈希表数量的参数。 // LSH OR-amplification 可用于降低假阴性率。 此参数的较高值会降低假阴性率,但会增加计算复杂性。 .setNumHashTables(5) // 随机种子的参数。 // .setSeed() .setInputCol("features") .setOutputCol("hashes") val model = mh.fit(dfA) // 1、特征转换 println("哈希值存储在“哈希”列中的哈希数据集: ") model.transform(dfA).show() // 计算输入行的局部敏感哈希,然后执行近似相似连接。 // 我们可以通过传入已经转换的数据集来避免计算哈希,例如 `model.approxSimilarityJoin(transformedA,transformedB,0.6)` println("在小于 0.6 的 Jaccard 距离上近似加入 dfA 和 dfB: ") model.approxSimilarityJoin(dfA, dfB, 0.6, "JaccardDistance") .select(col("datasetA.id").alias("idA"), col("datasetB.id").alias("idB"), col("JaccardDistance")).show() // 计算输入行的局部敏感哈希,然后执行近似最近邻搜索。 // 我们可以通过传入已经转换的数据集来避免计算哈希,例如 // `model.approxNearestNeighbors(transformedA, key, 2)` // 当没有找到足够的近似近邻候选时,它可能返回少于 2 行。 println("近似搜索 dfA 的 2 个最近邻居: ") model.approxNearestNeighbors(dfA, key, 2).show() 输出: 哈希值存储在“哈希”列中的哈希数据集: +---+--------------------+--------------------+ | id| features| hashes| +---+--------------------+--------------------+ | 0|(6,[0,1,2],[1.0,1...|[[2.25592966E8], ...| | 1|(6,[2,3,4],[1.0,1...|[[2.25592966E8], ...| | 2|(6,[0,2,4],[1.0,1...|[[2.25592966E8], ...| +---+--------------------+--------------------+ 在小于 0.6 的 Jaccard 距离上近似加入 dfA 和 dfB: +---+---+---------------+ |idA|idB|JaccardDistance| +---+---+---------------+ | 1| 4| 0.5| | 0| 5| 0.5| | 1| 5| 0.5| | 2| 5| 0.5| +---+---+---------------+ 近似搜索 dfA 的 2 个最近邻居: +---+--------------------+--------------------+-------+ | id| features| hashes|distCol| +---+--------------------+--------------------+-------+ | 1|(6,[2,3,4],[1.0,1...|[[2.25592966E8], ...| 0.75| +---+--------------------+--------------------+-------+