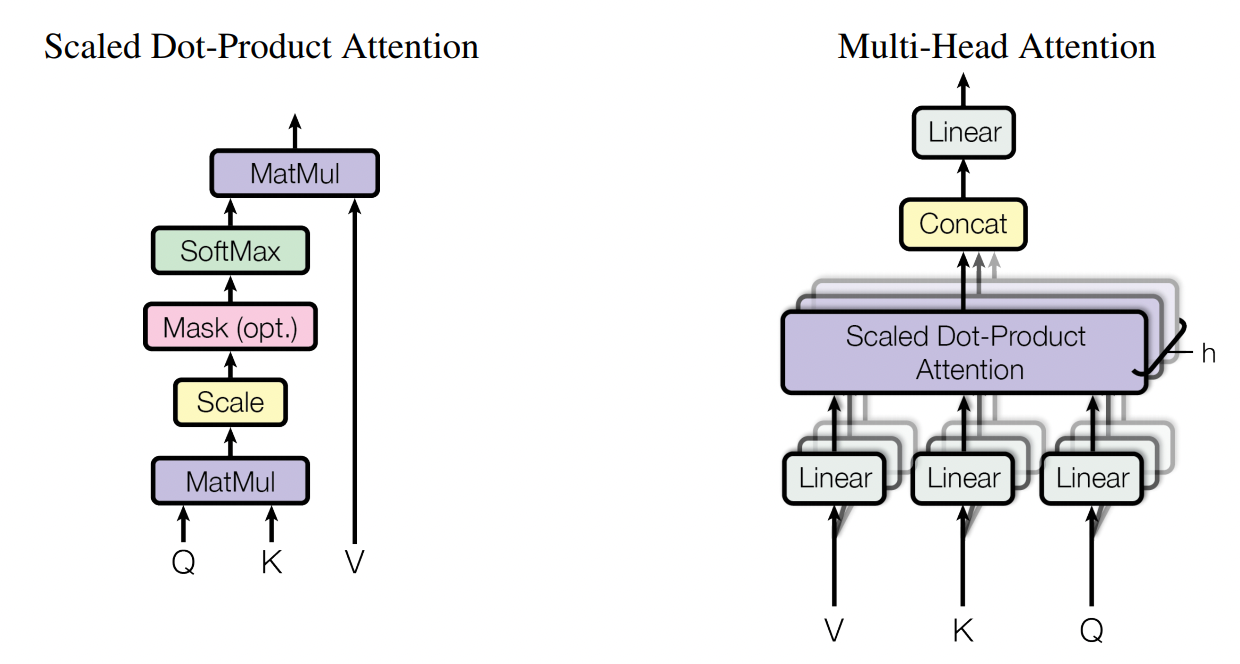
transformer

bert

XLnet
目前主流的nlp预训练模型包括两类 autoregressive (AR) language model 与autoencoding (AE) language model,AR模型的主要任务在于评估语料的概率分布,AR模型的缺点是单向的,我们更希望的是根据上下文来预测目标,而不单是上文或者下文,之前open AI提出的GPT就是采用的AR模式,包括GPT2.0也是该模式,那么为什么open ai头要这么铁坚持采用单向模型呢,看完下文你就知道了。
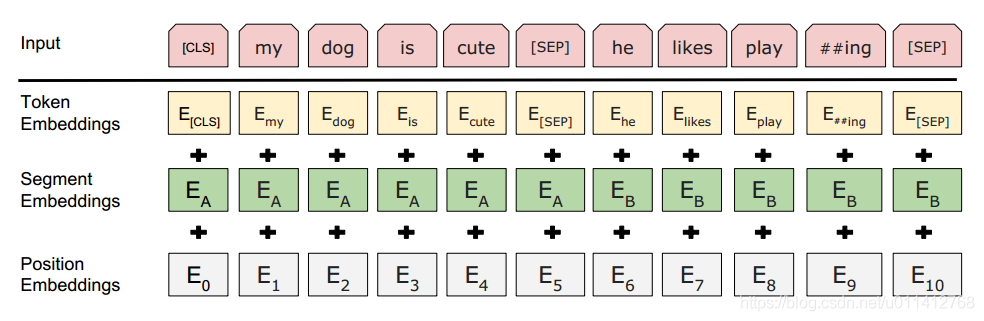
AE模型采用的就是以上下文的方式,最典型的成功案例就是bert。我们简单回顾下bert的预训练阶段,预训练包括了两个任务,Masked Language Model与Next Sentence Prediction,Next Sentence Prediction即判断两个序列的推断关系,Masked Language Model采用了一个标志位[MASK]来随机替换一些词,再用[MASK]的上下文来预测[MASK]的真实值,bert的最大问题也是处在这个MASK的点,因为在微调阶段,没有MASK这就导致预训练和微调数据的不统一,从而引入了一些人为误差,我觉得这应该就是为什么GPT坚持采用AR模型的原因。
在xlnet中,最终还是采用了AR模型,但是怎么解决这个上下文的问题呢,这就是本文的一个重点。通过排列组合的形式,选择一种形式来预测目标词。
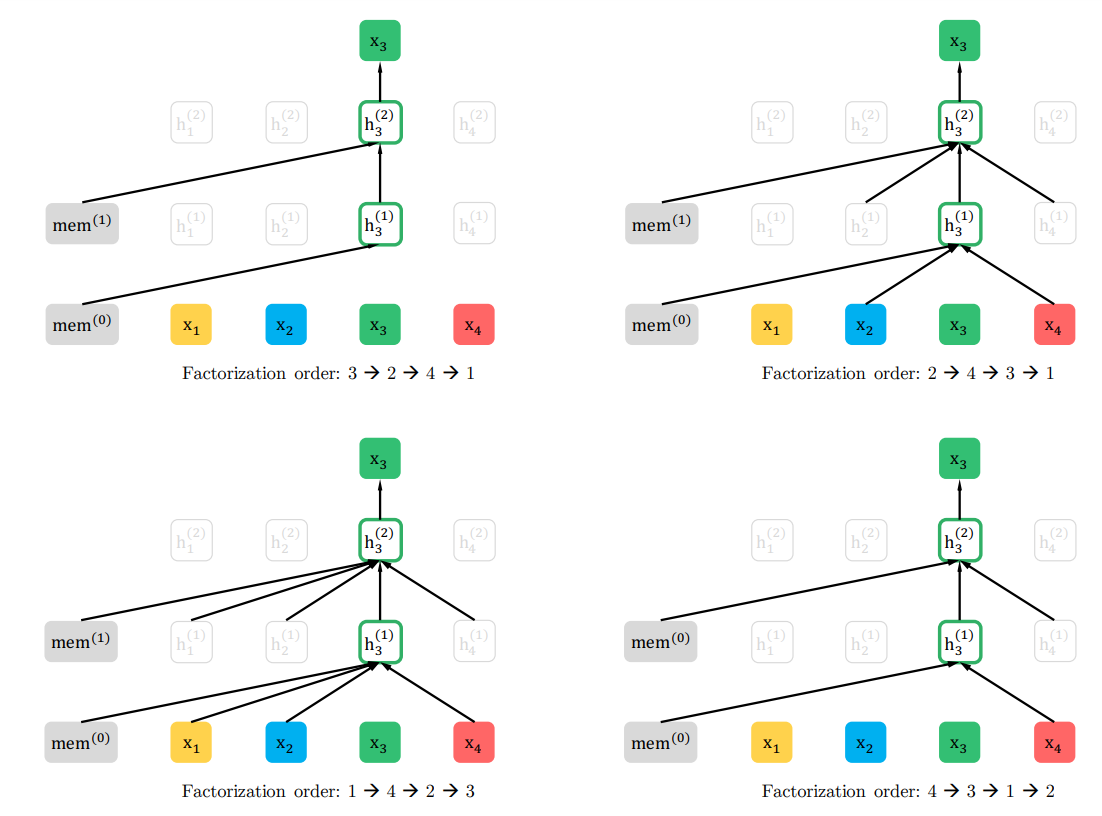
双流自注意力机制 一部分保存有文本和位置信息、一部分保存有位置信息
ALBert
整个模型的结构还是依照了BERT的骨架,采用了Transformer以及GELU激活函数。具体的创新部分应该有三个:一个是将embedding的参数进行了因式分解,然后就是跨层的参数共享,最后是抛弃了原来的NSP任务,现在使用SOP任务。
- Factorized embedding parameterization
原始的BERT模型以及各种依据transformer来搞的预训练语言模型在输入的地方我们会发现它的E是等于H的,其中E就是embedding size,H就是hidden size,也就是transformer的输入输出维度。这就会导致一个问题,当我们的hidden size提升的时候,embedding size也需要提升,这就会导致我们的embedding matrix维度的提升。所以这里作者将E和H进行了解绑,具体的操作其实就是在embedding后面加入一个矩阵进行维度变换。E是永远不变的,后面H提高了后,我们在E的后面进行一个升维操作,让E达到H的维度。这使得embedding参数的维度从O(V×H)到了O(V×E + E×H), 当E远远小于H的时候更加明显。
- Cross-layer parameter sharing
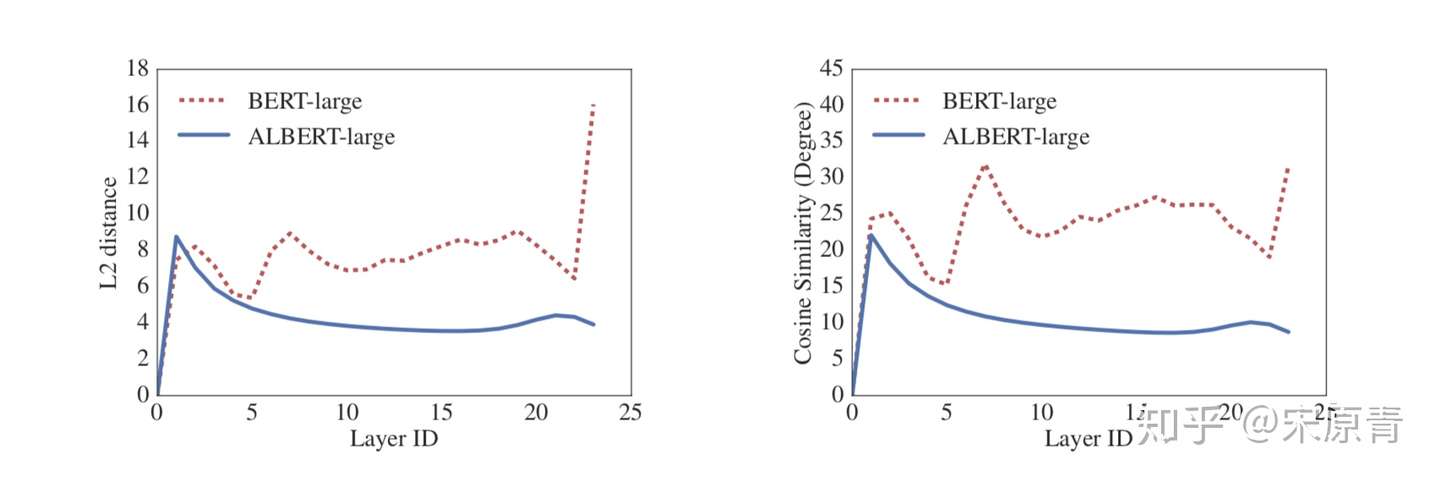
之前transformer的每一层参数都是独立的,包括self-attention 和全连接,这样的话当层数增加的时候,参数就会很明显的上升。之前有工作试过单独的将self-attention或者全连接进行共享,都取得了一些效果。这里作者尝试将所有的参数进行共享,这其实就导致多层的attention其实就是一层attention的叠加。同时作者通过实验还发现了,使用参数共享可以有效地提升模型的稳定程度。实验结果如下图:
- Inter-sentence coherence loss
这里作者使用了一个新的loss,其实就是更改了原来BERT的一个子任务NSP, 原来NSP就是来预测下一个句子的,也就是一个句子是不是另一个句子的下一个句子。这个任务的问题出在训练数据上面,正例就是用的一个文档里面连续的两句话,但是负例使用的是不同文档里面的两句话。这就导致这个任务包含了主题预测在里面,而主题预测又要比两句话连续性的预测简单太多。新的方法使用了sentence-order prediction(SOP), 正例的构建和NSP是一样的,不过负例则是将两句话反过来。实验的结果也证明这种方式要比之前好很多。但是这个这里应该不是首创了,百度的ERNIE貌似也采用了一个这种的。
参考:https://zhuanlan.zhihu.com/p/88099919