首先介绍下全角跟半角之间的区别:
在计算机屏幕上,一个汉字要占两个英文字符的位置,人们把一个英文字符所占的位置称为"半角",相对地把一个汉字所占的位置称为"全角"。在汉字输入时,系统提供"半角"和"全角"两种不同的输入状态,但是对于英文字母、符号和数字这些通用字符就不同于汉字,在半角状态它们被作为英文字符处理;而在全角状态,它们又可作为中文字符处理。半角和全角切换方法:单击输入法工具条上的按钮或按键盘上的Shift+Space键来切换。
1、全角:指一个字符占用两个标准字符位置。
汉字字符和规定了全角的英文字符及国标GB2312-80中的图形符号和特殊字符都是全角字符。一般的系统命令是不用全角字符的,只是在作文字处理时才会使用全角字符。
2、半角:指一字符占用一个标准的字符位置。
通常的英文字母、数字键、符号键都是半角的,半角的显示内码都是一个字节。在系统内部,以上三种字符是作为基本代码处理的,所以用户输入命令和参数时一般都使用半角。
3、全角与半角各在什么情况下使用?
全角占两个字节,半角占一个字节。
半角全角主要是针对标点符号来说的,全角标点占两个字节,半角占一个字节,而不管是半角还是全角,汉字都还是要占两个字节。
在编程序的源代码中只能使用半角标点(不包括字符串内部的数据)
在不支持汉字等语言的计算机上只能使用半角标点(其实这种情况根本就不存在半角全角的概念)
对于大多数字体来说,全角看起来比半角大,当然这不是本质区别了。
4、全角和半角的区别
全角就是字母和数字等与汉字占等宽位置的字。半角就是ASCII方式的字符,在没有汉字输入法起做用的时候输入的字母数字和字符都是半角的。
在汉字输入法出现的时候,输入的字母数字默认为半角,但是标点则是默认为全角,可以通过鼠标点击输入法工具条上的相应按钮来改变。
5、关于“全角”和“半角”:
全角:是指中GB2312-80(《信息交换用汉字编码字符集·基本集》)中的各种符号。
半角:是指英文件ASCII码中的各种符号。
全角状态下字母、数字符号等都会占两个字节的位置,也就是一个汉字那么宽,半角状态下,字母数字符号一般会占一个字节,也就是半个汉字的位置,全角半角对汉字没有影响。
说了那么多,我们就看下在java编程语言中如何来判断字符串中的全角半角符号。
有两种方式可以判断:
1:通过正则表达式来进行判断 [^\x00-\xff]
2: 通过字符编码的范围进行判断.
有关字符编码的范围介绍如下:
我们可以编写一个测试用例输出所有的字符编码。
public static void main(String[] args) {
for (int i = Character.MIN_VALUE; i <= Character.MAX_VALUE; ++i) {
System.out.println(i + " " + (char)i);
}
}
测试结果如下:(截取部分图)

经过测试发现:
1.半角字符是从33开始到126结束
2.与半角字符对应的全角字符是从65281开始到65374结束
3.其中半角的空格是32.对应的全角空格是12288
半角和全角的关系很明显,除空格外的字符偏移量是65248(65281-33 = 65248)
// 测试用例1----------使用正则表达式
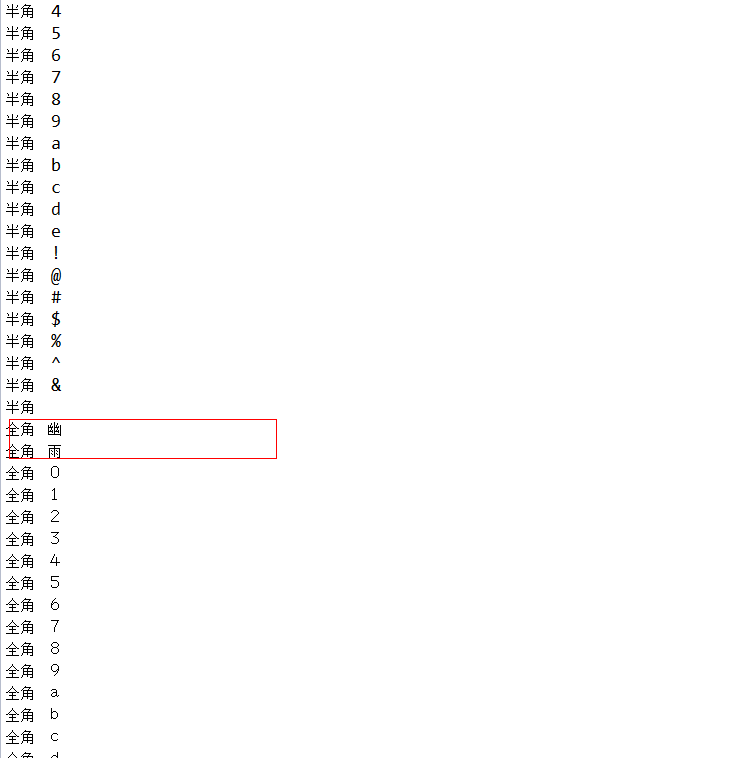
// 纯半角,包含有数字,字母,特殊符号,空格,汉字
String test1 = "0123456789abcde!@#$%^& 幽雨";
char[] chars_test1 = test1.toCharArray();
for (int i = 0; i < chars_test1.length; i++) {
String temp = String.valueOf(chars_test1[i]);
// 判断是全角字符
if (temp.matches("[^\x00-\xff]")) {
System.out.println("全角 " + temp);
}
// 判断是半角字符
else {
System.out.println("半角 " + temp);
}
}
测试结果如下:

// 测试用例2----------使用正则表达式
// 纯全角,包含有数字,字母,特殊符号,空格,汉字
String test2 = "0123456789abcde!@#$%^& 幽雨";
char[] chars_test2 = test2.toCharArray();
for (int i = 0; i < chars_test2.length; i++) {
String temp = String.valueOf(chars_test2[i]);
// 判断是全角字符
if (temp.matches("[^\x00-\xff]")) {
System.out.println("全角 " + temp);
}
// 判断是半角字符
else {
System.out.println("半角 " + temp);
}
}
测试结果如下:

// 测试用例3----------使用正则表达式
// 混合,包含有数字,字母,特殊符号,空格,汉字
String test3 = "0123456789abcde!@#$%^& 幽雨0123456789abcde!@#$%^& 幽雨";
char[] chars_test3 = test3.toCharArray();
for (int i = 0; i < chars_test3.length; i++) {
String temp = String.valueOf(chars_test3[i]);
// 判断是全角字符
if (temp.matches("[^\x00-\xff]")) {
System.out.println("全角 " + temp);
}
// 判断是半角字符
else {
System.out.println("半角 " + temp);
}
}
测试结果如下:
这里介绍下如果不想要字符串中的汉字的话,可以使用正则表达式将之去除: [u4e00-u9fa5]
测试用例4:
去除字符串中汉字
String ss = "waeaeaea我们women在这里";
System.out.println(ss.replaceAll("[u4e00-u9fa5]", ""));
测试结果如下:不管是全角还是半角下的汉字

或者是截取出字符串中的汉字
String ss = "waeaeaea我们women在这里";
char[] chars_ss = ss.toCharArray();
String test = "";
for (int i = 0; i < chars_ss.length; i++) {
String temp = String.valueOf(chars_ss[i]);
// 判断是汉字
if (temp.matches("[u4e00-u9fa5]")) {
test += temp;
}
}
System.out.println(test);
测试结果如下:

测试用例5--------使用字符的unicode码进行判断
// 纯半角,包含有数字,字母,特殊符号,空格,汉字
String test1 = "0123456789abcde!@#$%^& 幽雨";
// 首先将汉字用空格替换掉
test1 = test1.replaceAll("[u4e00-u9fa5]", "");
char[] chars_test1 = test1.toCharArray();
for (int i = 0; i < chars_test1.length; i++) {
int charValue = (int) chars_test1[i];
// 判断是全角字符
if (charValue >= 65281 && charValue <= 65374 || charValue == 12288) {
System.out.println("全角 " + (char) charValue);
}
// 判断是半角字符
else if (charValue >= 33 && charValue <= 126 || charValue == 32) {
System.out.println("半角 " + (char) charValue);
}
}
测试结果如下:

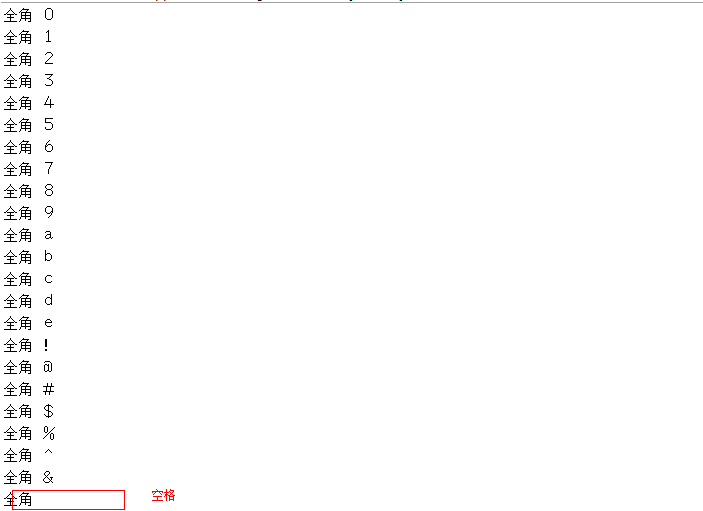
测试用例6--------使用字符的unicode码进行判断
// 纯全角,包含有数字,字母,特殊符号,空格,汉字
String test2 = "0123456789abcde!@#$%^& 幽雨";
// 首先将汉字用空格替换掉
test2 = test2.replaceAll("[u4e00-u9fa5]", "");
char[] chars_test2 = test2.toCharArray();
for (int i = 0; i < chars_test2.length; i++) {
int charValue = (int) chars_test2[i];
// 判断是全角字符
if (charValue >= 65281 && charValue <= 65374 || charValue == 12288) {
System.out.println("全角 " + (char) charValue);
}
// 判断是半角字符
else if (charValue >= 33 && charValue <= 126 || charValue == 32) {
System.out.println("半角 " + (char) charValue);
}
}
测试结果如下:
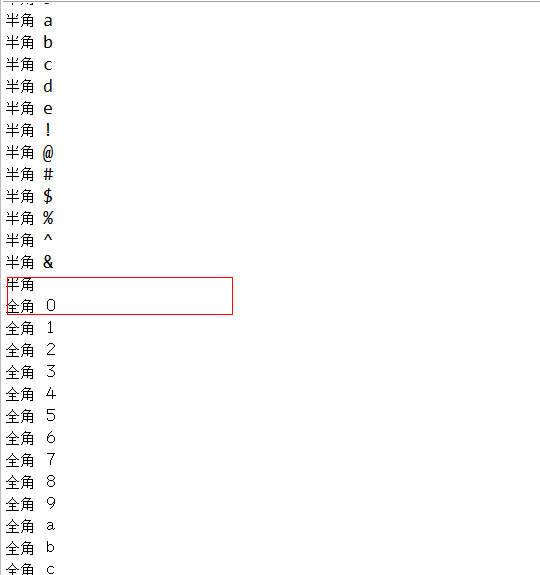
测试用例7--------使用字符的unicode码进行判断
// 混合,包含有数字,字母,特殊符号,空格,汉字
String test3 = "0123456789abcde!@#$%^& 幽雨0123456789abcde!@#$%^& 幽雨";
// 首先将汉字用空格替换掉
test3 = test3.replaceAll("[u4e00-u9fa5]", "");
char[] chars_test3 = test3.toCharArray();
for (int i = 0; i < chars_test3.length; i++) {
int charValue = (int) chars_test3[i];
// 判断是全角字符
if (charValue >= 65281 && charValue <= 65374 || charValue == 12288) {
System.out.println("全角 " + (char) charValue);
}
// 判断是半角字符
else if (charValue >= 33 && charValue <= 126 || charValue == 32) {
System.out.println("半角 " + (char) charValue);
}
}
测试结果如下:
参考链接是:
1.http://blog.csdn.net/liming0931/article/details/22384559/
2.http://www.jb51.net/article/43718.htm