The gola of an Auto Scaling Group (ASG) is to:
- Scale out (add EC2 instances) to match an increased load
- Scale in (remove EC2 instances) to match a decreased load
- Ensure we have a minimum and maximum number of machines running
- Automatically Register new instances to a load balancer
Atttributes
- A launch configuration
- AMI + Instance Type
- EC2 User Data
- EBS Volumes
- Security Groups
- SSH Key Pair
- Min Size / Max Size / Initial Capacity
- Network + Subnets information
- Load Balancer Information
- Scaling Policies
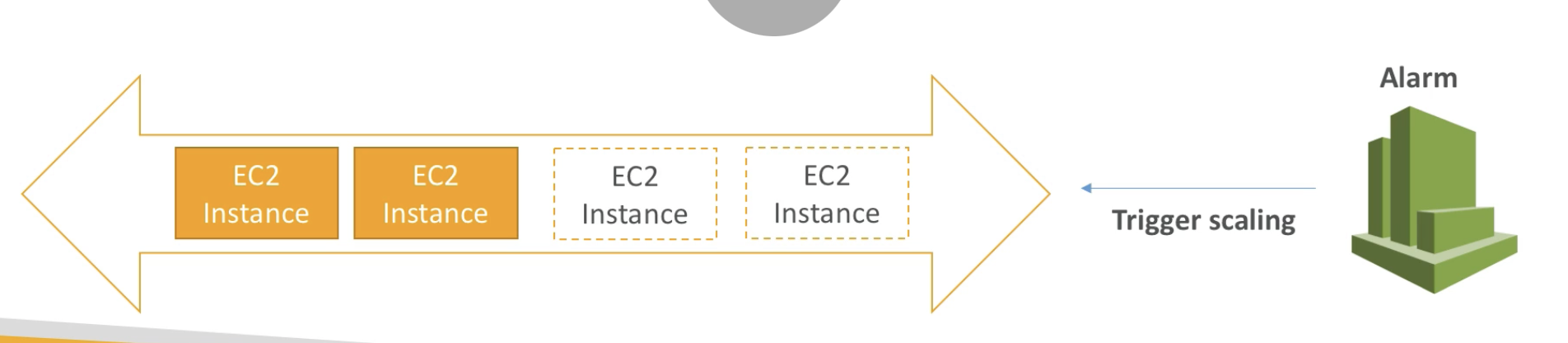
Auto Scaling Alarms
- It is possible to scale an ASG based on CloudWatch alarms
- An Alarm monitors a metric (Such as Average CPU)
- Metrics are computed for the overall ASG instances
- Based on the alarm:
- We can create scale-out policies (increase the number of instances)
- We can create scale-in policies (decrease the number of instances)
Auto Scaling New Rules
- It is possible to define "better" auto scaling rules that are directly managed by EC2
- Target Average CPU usage
- Number of requests on the ELB per instance
- Average Network In
- Average Network Out
- There rules are easier to set up and can make more sense
Auto Scaling Custom Metric
- We can auto scale based on custom metric (ex: number of connected users)
- Send Custom metric from application to EC2 to CloudWatch (PutMetric API)
- Create CloudWatch alaram to react to low / high values
- Use CloudWatch alaram as the scaling policy for ASG
ASG Brain Dump
- Scaling policies can be on CPU, Network... and can even be on custom metrics based on schedule (if you know your visitor patterns)
- ASGs use Launch configurations or Launch Templates (newer)
- To update an ASG, you must provide a new launch configuration / launch template
- IAM role attached to an ASG will get assigned to EC2 instances
- Having instances under an ASG means that if they get terminated for whatever reason, the ASG will automatically create new ones as a replacement.
- ASG can terminate instances marked as unhealthy by an LB (and hence replace them)
Scaling Policies
Target Tracking Scaling
- Most simple and easy to set-up
- Example: Iwant the average ASG cup to stay at around 40%
Simple / Step Scaling
- When a CloudWatch alarm is triggered (CPU > 70%), then add 2 units
- When a CloudWatch alarm is triggered (CPU < 30%), then remove 1 unit
Scheduled Actions
- Anticipate a scaling based on known usage patterns
- Example: increase the min capacity to 10 at 5 pm on Fridays


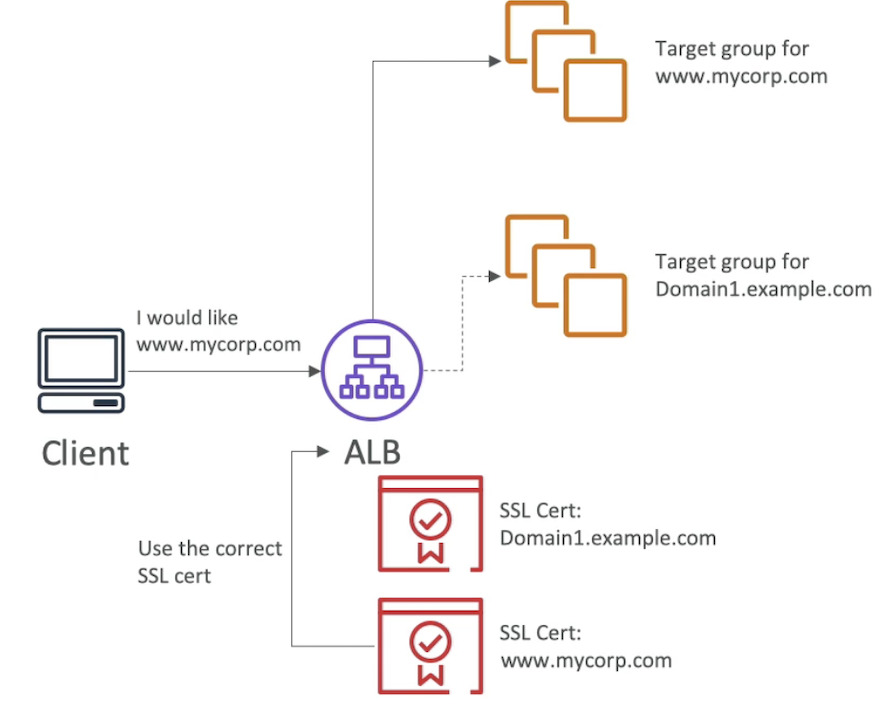
Server Name Indication
- SNI solves the problem of loading multiple SSL cerificates onto one web server (to serve multiple websites)
- It's a newer protocol and requires the client to indicate the hostname of the target server in the initial SSL hadshake
- The server will then find the correct certifcate, or return the default one
- Only works for ALB & NLB, CloudFront
- Doesn't work for CLB
ELB - Connection Draining
- Deregistration Delay for ALB & NLB
- TIme to complete "in-fight requests" while the instnace is de-registering or unhealth
- Stops sending new request to the instance which is de-regsitering
- Between 1 to 3600 seconds, default is 300 seconds
- Can be disabled (set value to 0)
- Set to a low value if your requests are short

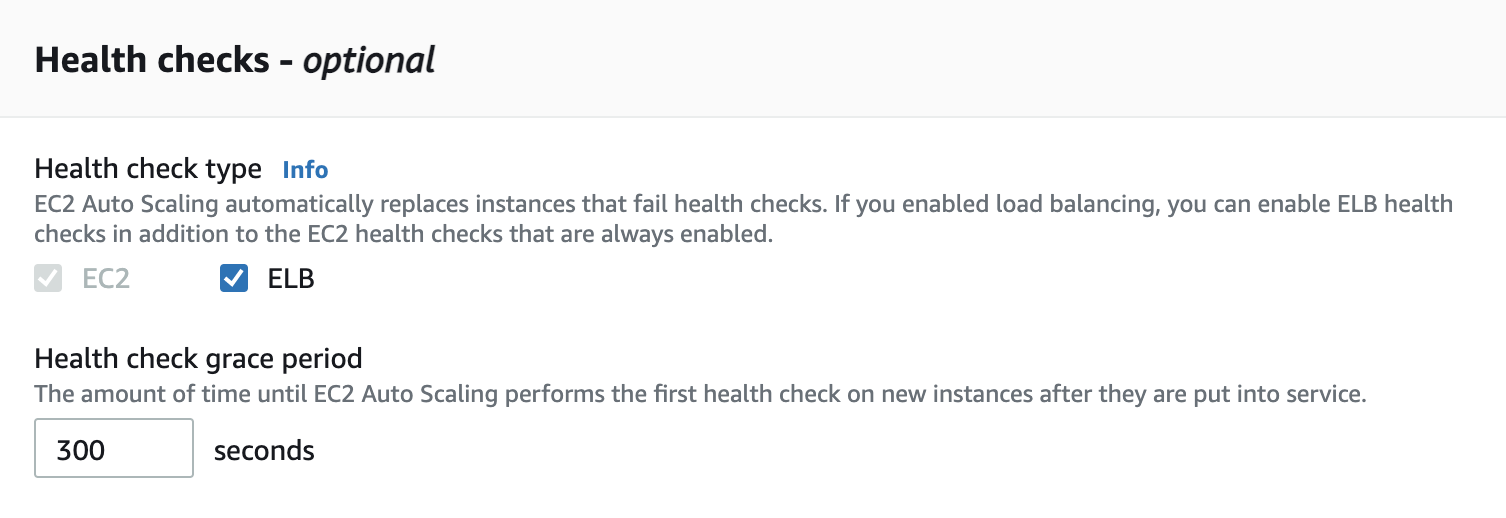
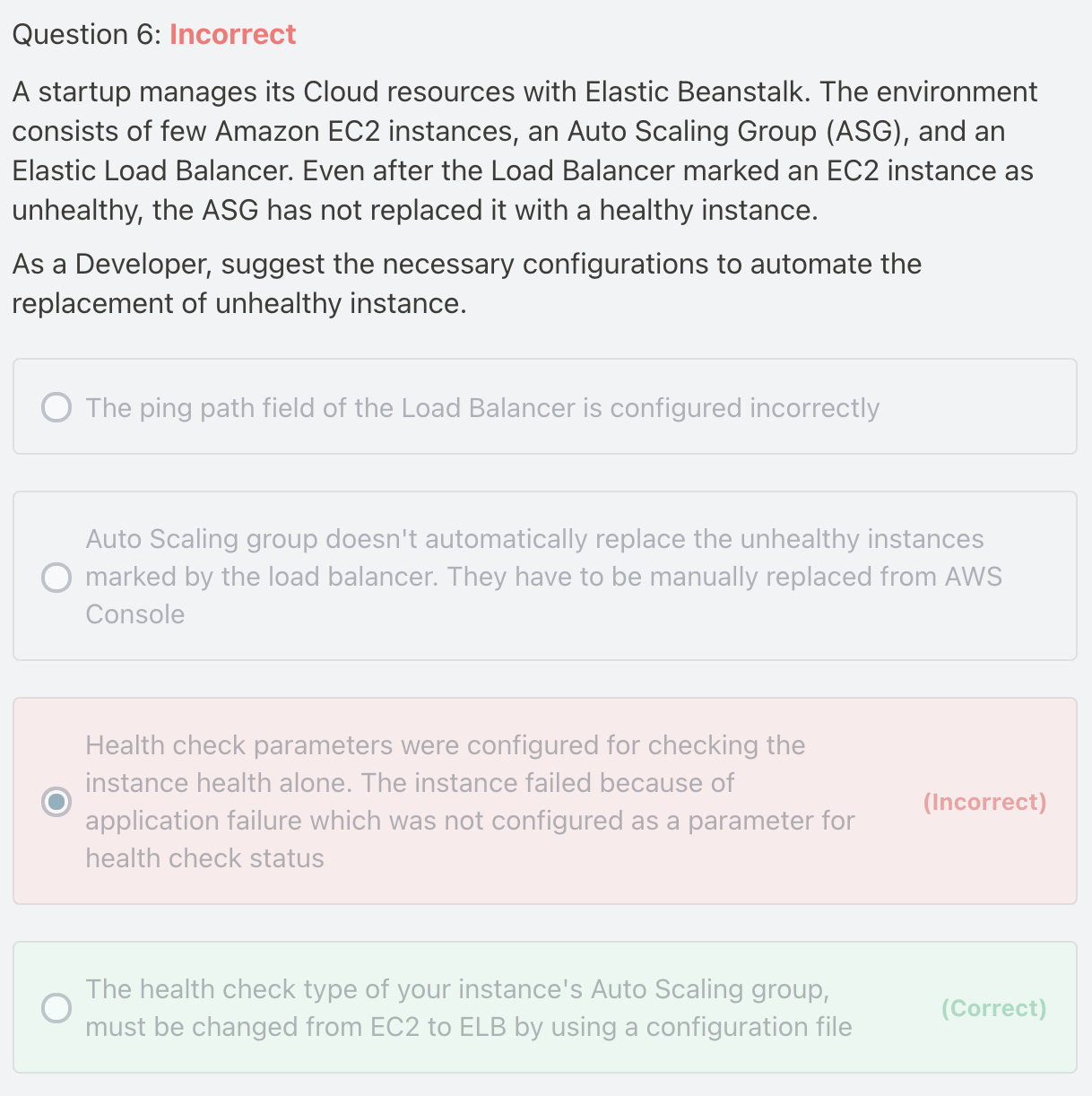
- Status checks cover only an EC2 instance's health, and not the health of your application, serer, or any Docker containers, running on the instnace.
- If you application craches, the load balancer removes the unhealth instances from its target. However, your AutoScaling group doesn't automatically replace the unhealthy instnaces marked by the load balancer.
- By Changing the health check typf from EC2 to ELB, you enabled the Auto Scaling group to automatically replae the unhealthy intnaces. The unhealthy instances are replaced when the health check fails.


ASG doesn't create new AMI
ASG doesn't add new volume.
EC2 ASG groups are regional constructs. They can span AZs, but not AWS regions.