Configuring Your Cluster
Kubernetes has configurations that can be tuned to optimize your deployed application.
Cost
- Replicas: you can reduce number of replicas used in Development or Prodcution to reduce cost
- Resouces used: You can fine tuning the EC2 storage, instance type; for micorservice, it doesn't need too powerful resources.
Security
- Configure who has access to the Kubernetes pods and services.
- Developers can access to Developement Pods and Nodes, only Automation can access Production's Pods and Nodes
- Secure traffic for least-privilege
Thinking about Production
Production-ready
Deployed applications for production-use are different than ones we use for development. We have to make additional considerations as the application is no longer running in our isolated environment.
Restrict Access
- Follow properties of least-privilege to secure our application.
- For example, Database should restrict traffic access
- If from own server, they are expected access
- Otherwise, it is unexpected access, even you have username and password, should NOT access Database either.
Scale
- Be able to handle the number and size of user requests.
Availability
- Ensure that the application is responsive and able to be used when needed.
Load testing
Load testing is a common way to simulate a large number of requests to our application. By doing so, we are essentially stress-testing it to preview when it will fail. This helps us set a baseline understanding of the limits of our application.
Reverse Proxy
- A single interface that forwards requests on behalf of the client and appears to the client as the origin of the responses.
- Useful for abstracting multiple microservices to appear as single resource.
You can think about Reverse Proxy as a service desk in a hotel. If you found electricty doesn't work in your room or Internet doesn't work. Instead of looking for electricty engineer and IT engineer. You just need to talk to Service desk, Service desk knows who should ask for.
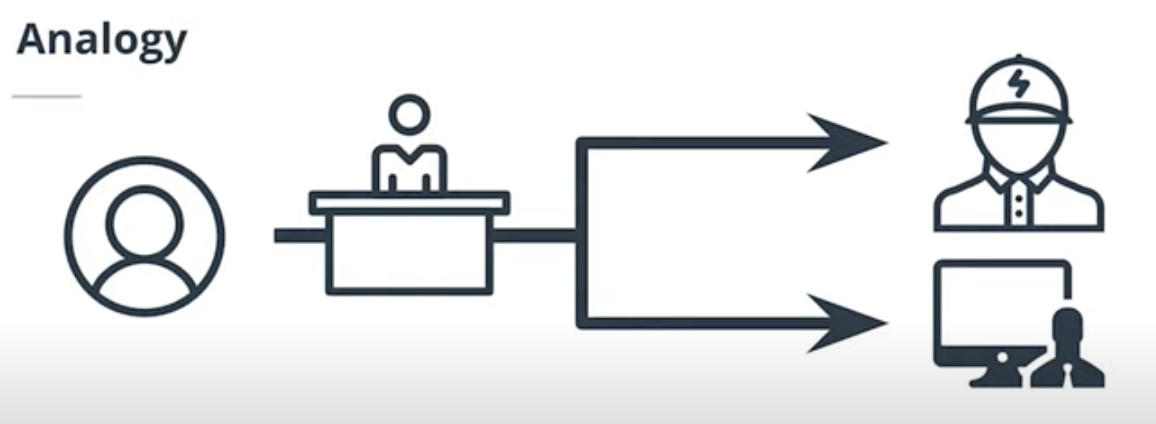
For our web applications, Frontend talks to Reverse Proxy, Reverse Proxy knows which services it should redirect the request to.

API Gateway
A form of a reverse proxy that serves as an abstraction of the interface to other services.
Sample Reverse Proxy
-
Nginx is a web server that can be used as a reverse proxy. Configurations can be specified with an
nginx.conffile. -
Sample bare-bones
nginx.conffile:
events { } http { server { listen <PORT_NUMBER>; location /<PROXY_PATH>/ { proxy_pass http://<REDIRECT_PATH>/; } } }
Example:
events { } http { server { listen 8080; location /api/ { proxy_pass http://my-app-2-svc:8080/; } } }
deployment.yaml
apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: service: reverseproxy name: reverseproxy spec: replicas: 1 template: metadata: labels: service: reverseproxy spec: containers: - image: YOUR_DOCKER_HUB/simple-reverse-proxy name: reverseproxy imagePullPolicy: Always resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "1024Mi" cpu: "500m" ports: - containerPort: 8080 restartPolicy: Always
service.yaml
apiVersion: v1 kind: Service metadata: labels: service: reverseproxy name: reverseproxy-svc spec: ports: - name: "8080" port: 8080 targetPort: 8080 selector: service: reverseproxy
Commands
kubectl apply -f deployment.yaml
kubectl apply -f service.yaml
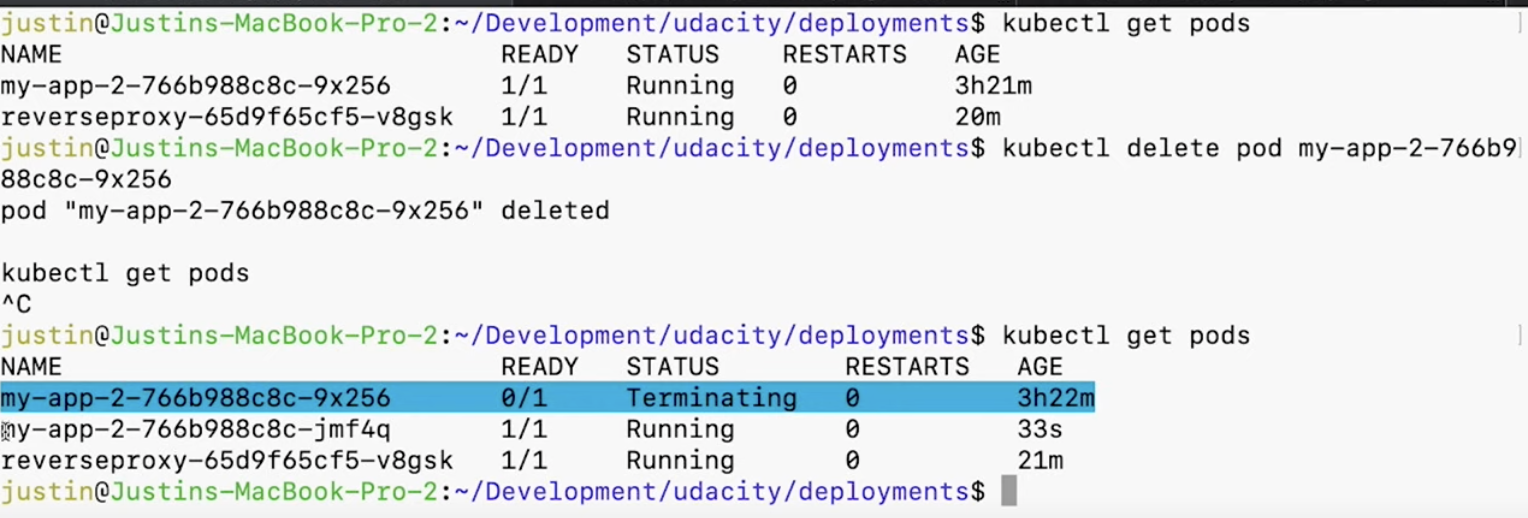
After running those commands, you should see Kubenates bring up a new pod according to defination.
kubectl get pods
kubectl describe services


So now if we curl `http://reverseproxy-svc:8080/api/health`, it wil forwards `/health` endpoint to `http://my-app-2-svc:8080/health`.

Additional Reading
The following are some additional resources for learning more about API Gateways.
API Gateway
An API Gateway and library both help us reduce repeated code by allowing us to abstract common logic. An API Gateway sits in front of the code as a reverse proxy whereas a library is imported into our code. What are some differences between how we abstract common logic with an API Gateway versus a library?
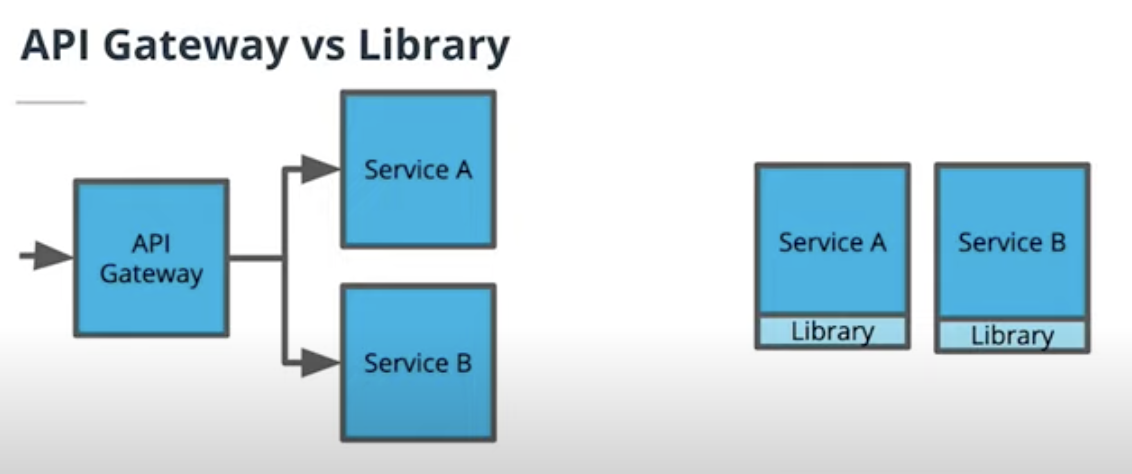
Library
- Library must be imported
- Abstraction of common code in the same programming language
API Gateway
- Abstraction of interface: common code and common logic
- Has its own technology stack
Securing the Microservices
This is not an all-inclusive list of things to do for securing your application. It means that while some of these are best-practice, there's no guarantee that these steps will ensure your application is perfectly secure.
AWS security groups
Enables you to restrict the inbound and outbound traffic for AWS resources.
- Kubernetes Ingress and Egress Enables you to restrict the inbound and outbound traffic for Kubernetes resources.
Key Terms - Securing Microservices
| Term | Definition |
|---|---|
| Ingress | Inbound web traffic |
| Egress | Outbound web traffic |

Given a microservice that is only interfaced through a reverse proxy, what is the best option to securing this microservice?
Answer: Set microservice to only allow ingress traffic from the reverse proxy.
Configuring Scalable and Resilient Applications
Self-Healing
Kubernetes deployments can be set up to recover from failure.
- Health checks - an HTTP endpoint that must return a
200response for a healthy status. Kubernetes will periodically ping this endpoint. - Replicas - Kubernetes will attempt to maintain the number of desired replicas. If a pod is terminated, it will automatically recreate the pod.
Horizontal Scaling with Kubernetes
Horizontal Pod Autoscaler
A deployment feature that allows additional pods to be created when a CPU usage threshold is reached.
Commands
-
Create HPA
kubectl autoscale deployment <NAME> --cpu-percent=<CPU_PERCENTAGE> --min=<MIN_REPLICAS> --max=<MAX_REPLICAS> -
View HPA
kubectl get hpa - Delete HPA
kubectl delete hpa <NAME>

Additional Reading
The following are some additional resources for learning more about how we can make our deployed applications more robust:
Use Logs to Capture Metrics for Debugging
Key Points
-
Software is rarely free of errors so we need to troubleshoot errors when they occur.
-
In production environments we don't have tools like breakpoints that could help us identify bugs
-
Logging can get complicated so we need tools to handle logs and make it easy to search them.
-
System logs used for debugging are sometimes different from error messages returned by API's.
Strategies for Logging
- Use timestamps to know when the activity occurred
- Set a consistent style of logging to make it easier to parse log output
- Use process IDs to trace an activity
- Rotate logs so they don't fill up your storage
- Include stack traces in your logs
- Look at the delta in message timestamps to measure execution time
Additional Resources
For more resources on learning about logs:

Q: If we have multiple pods running in Kubernetes and all of our logs are centralized into a single file, what are some difficulties with determining the execution time of an API request?
A: Replicas will produce similar logs as they execute the same code. Use a unique ID to help us trace logs from the same request.