最近在处理数据量较大的项目时,应用到index索引与HASH对象的结合使用,总结一下对index作为建索引的相关知识点
1.概念
索引:索引是一种辅助的数据结构,通过一个或者多个关键变量来直接指向观测。SAS索引有两类,简单索引:只基于一个变量的值,索引名自动等于关键变量名;复合索引:基于多于一个的关键变量,需自定义唯一的名称
2.什么情况使用索引
虽然索引可以看成指向数据的快捷方式,但是索引的开销相当高,包括磁盘空间的开销及处理等,所以要考虑建立索引的情况:
访问的观测远远小于总体
用于BY语句引用已排序的变量
3.如何建索引
3.1 DATA步
/*简单索引*/
DATA A(INDEX=(age));
SET SASHELP.CLASS;
RUN;
/*复合索引*/
DATA B(INDEX=(A_W=(AGE WEIGHT)));
SET SASHELP.CLASS;
RUN;
3.2 PROC SQL步
PROC SQL;
DROP INDEX AGE FROM A;
CREATE INDEX AGE ON A(AGE);/*简单索引*/
CREATE INDEX A_W ON A(AGE,WEIGHT);/*复合索引*/
QUIT;
3.3 PROC DATASETS
PROC DATASETS LIB=<libname>;
MODIFY <datasetname>;
INDEX CREATE <index_name>/<NOMISS> <UNIQUE>
<UPDATECENTILES=ALWAYS|NEVER|integer>
RUN;
这里:
libname:逻辑库名称
Datasetname:数据集名称
Index_name:索引名,可以是一个关键变量名,也可以是自定义的变量名,但需要指定对应哪几个变量
选项中:
NOMISS:从索引中排除所有索引变量缺失值的观测
UNIQUE:指定索引变量或者变量组合必须是唯一的
UPDATECENTILES:指定数据值更新多少时,索引也随之更新,可以是总是更新|从不更新|设定的百分比10(表示10%),默认是5(percent)
LIBNAME S ‘.’;
/*简单索引;指定对S逻辑库下A数据集,以AGE为关键变量建索引*/
PROC DATASETS LIB=S;
MODIFY A;
INDEX CREATE AGE;
RUN;
/*复合索引:三个关键变量括号里的顺序为关键次序,A_W_H是唯一的索引名*/
PROC DATASETS LIB=S;
MODIFY A;
INDEX DELETE AGE;/*删除索引*/
INDEX CREATE A_W_H=(AGE,WEIGHT,HEIGHT);
RUN;
需要注意的是,如果原有的索引已经存在,必须先删除,再重新建立
4. OPTIONS MSGLEVEL=N|I;查看索引的使用情况
N:仅打印NOTES、WARNING、ERROR信息,系统的默认选项。
I:打印N选项的信息,同时打印附属信息,包括索引的使用、合并处理、排序等附加信息。
5.SAS不使用索引的情况
(1) DATA步使用IF语句取子集
(2)WHERE 表达式只有部分包含关键变量
(3)SAS检测出顺序读取数据更有效率
6.示例:实现对年龄的分组,组内排序
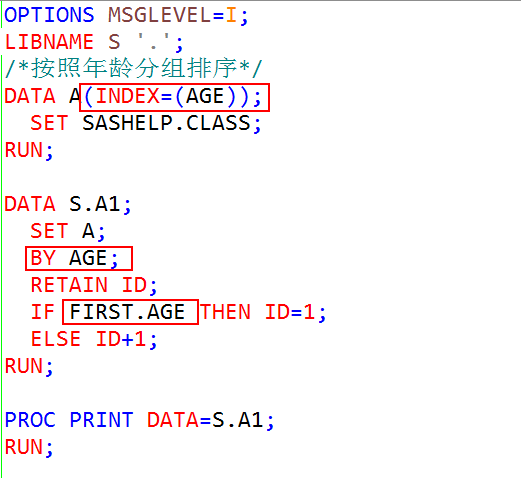
结果:

参考文档:http://blog.163.com/shen_960124/blog/static/6073098420136161844551/和SAS help