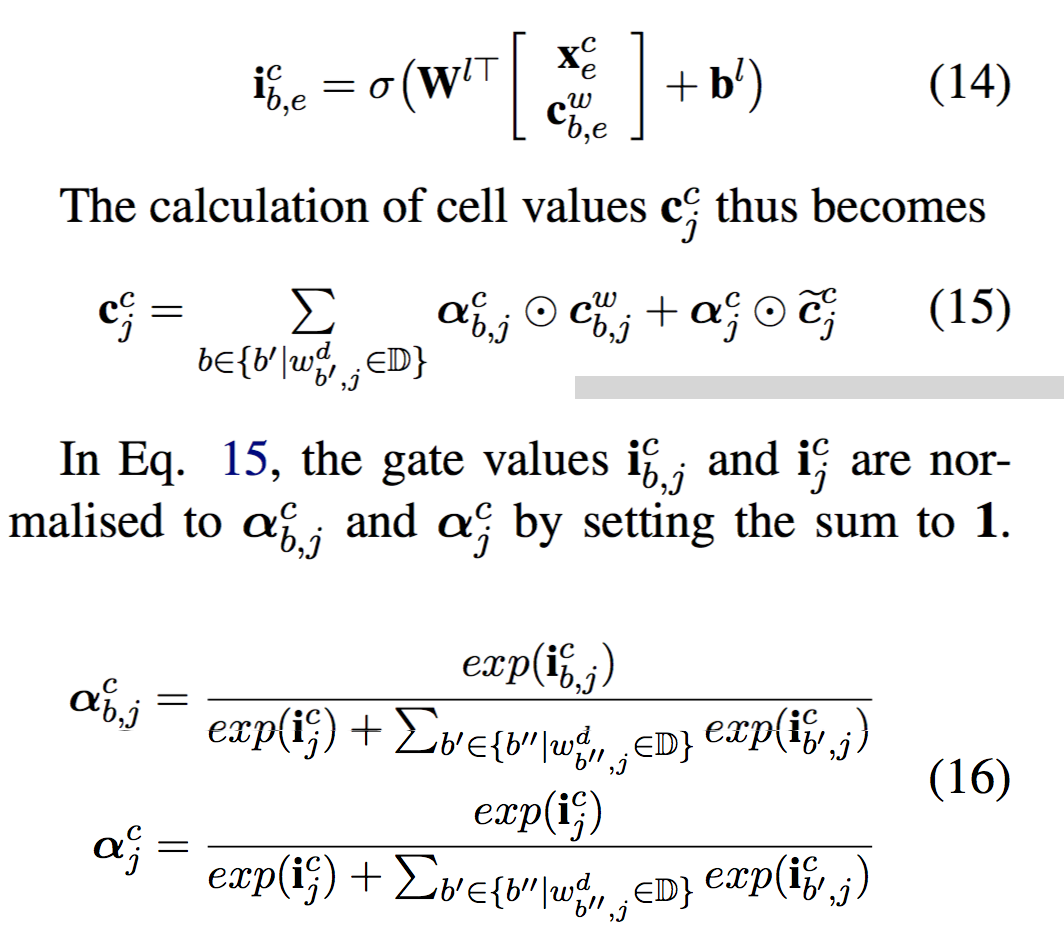paper: https://arxiv.org/pdf/1805.02023.pdf
code:https://github.com/jiesutd/LatticeLSTM
背景介绍:
什么是NER?
NER就是通过序列标注对实体边界和实体类别进行预测,从而识别和提取出相应的命名实体。
NER模型进展:
近5年来,使用 Deep Learning 处理 NER 问题正逐渐成为趋势;
目前英文NER:效果最佳的模型是 LSTM-CRF(Lample et al., 2016; Ma and Hovy, 2016; Chiu and Nichols, 2016; Liu et al., 2018)。
那么对于中文 NER:也可以使用这种模型,但是中文NER和分词相关,基于character-level的LSTM-CRF无法利用句子中的单词word信息,已有研究表明,中文 NER 中,基于字符的方法表现要优于基于词的方法(He and Wang, 2008; Liu et al., 2010; Li et al., 2014)。但是如果基于分词器,NER一旦出现分词错误,就会直接影响实体边界的预测,导致识别错误,这在开放领域是很严重的问题。
论文改进:
综上背景所述,来自新加坡科技设计大学的研究者Yue Zhang∗ and Jie Yang∗在 arXiv 上发布了一篇论文,介绍了一种新型中文命名实体识别方法,该方法利用 网格结构的LSTM(Lattice LSTM),性能优于基于字符和词的方法。与基于字符的方法相比,该模型显性地利用词和词序信息;与基于词的方法相比,lattice LSTM 不会出现分词错误。这篇论文已被 ACL 2018 接收发表。
单刀直入Lattice LSMT模型靶心(不浪费篇幅进行paper翻译):
模型的基本思想: 利用 lattice LSTM 来表征句子中的潜在词汇(南京,南京市,市长。。。) ,从而将潜在词信息(向量表征)整合到基于字符的 LSTM-CRF 中。
模型优势:利用利用显性的词信息而不是字符序列标注,且不会出现分词误差。
观察下图,模型的主干是基于字符(c)的LSTM-CRF,值得注意的是这个LSTM每个Cell内部的信息处理方式与基本的LSTM cell(输入门,遗忘门,输出门,Cell State)不同。
模型中的红色 Cell,是句子中潜在词汇产生的信息,同主干 LSTM 相应的 character Cell 连接。
那么问题来了:这些红色 Cell 是如何动态融合到主干 LSTM 的呢?

论文中的红色cell没有输出门,那么cell state即表示词汇信息。具体cell计算公式见下图:

继续考虑本文的 Lattice LSTM 模型,比如“桥”字,句子中潜在的以它结尾的词汇有:“长江大桥”&“大桥”。因此,当前字符 Cell 除了“桥“字以外,还要考虑这两个词汇。
从图1上看就是两个红色 Cell 引出的两个绿色箭头,代表这两个词汇的信息。这些词汇信息不会全部融入当前“桥”对应的字符 Cell,paper提出addtional control gate(i):根据当前字符和词汇信息来计算词汇信息权重,如下图公式所示:
解释说明:公式14中, x 和 c 分别代表当前字符的字符向量和当前词汇的cell state;
公式15 即为当前字符(桥)在融合了latent word后的最终Cell state计算方式。
公式16是归一化算法:计算当前字符 Cell 各种输入的权重,分母是句子中以当前词结尾的所有词汇的权重以及当前字符输入门的求和。