在搜索引擎中,数据被爬取后,就会建立index,方便检索。
在工作中经常会听到有人问,你这个index是正排的还是倒排的?那么什么是正排呢?什么又是倒排呢?下面是一些简单的介绍。
网页A中的内容片段:
Tom is a boy.
Tom is a student too.
网页B中的内容片段:
Jon works at school.
Tom's teacher is Jon.
正排索引:
正排索引是指文档ID为key,表中记录每个关键词出现的次数,查找时扫描表中的每个文档中字的信息,直到找到所有包含查询关键字的文档。
假设网页A的局部文档ID是 TA, 网页B的局部文档ID是 TB。那么对TA进行正排索引建立的表结构是下面这样的:
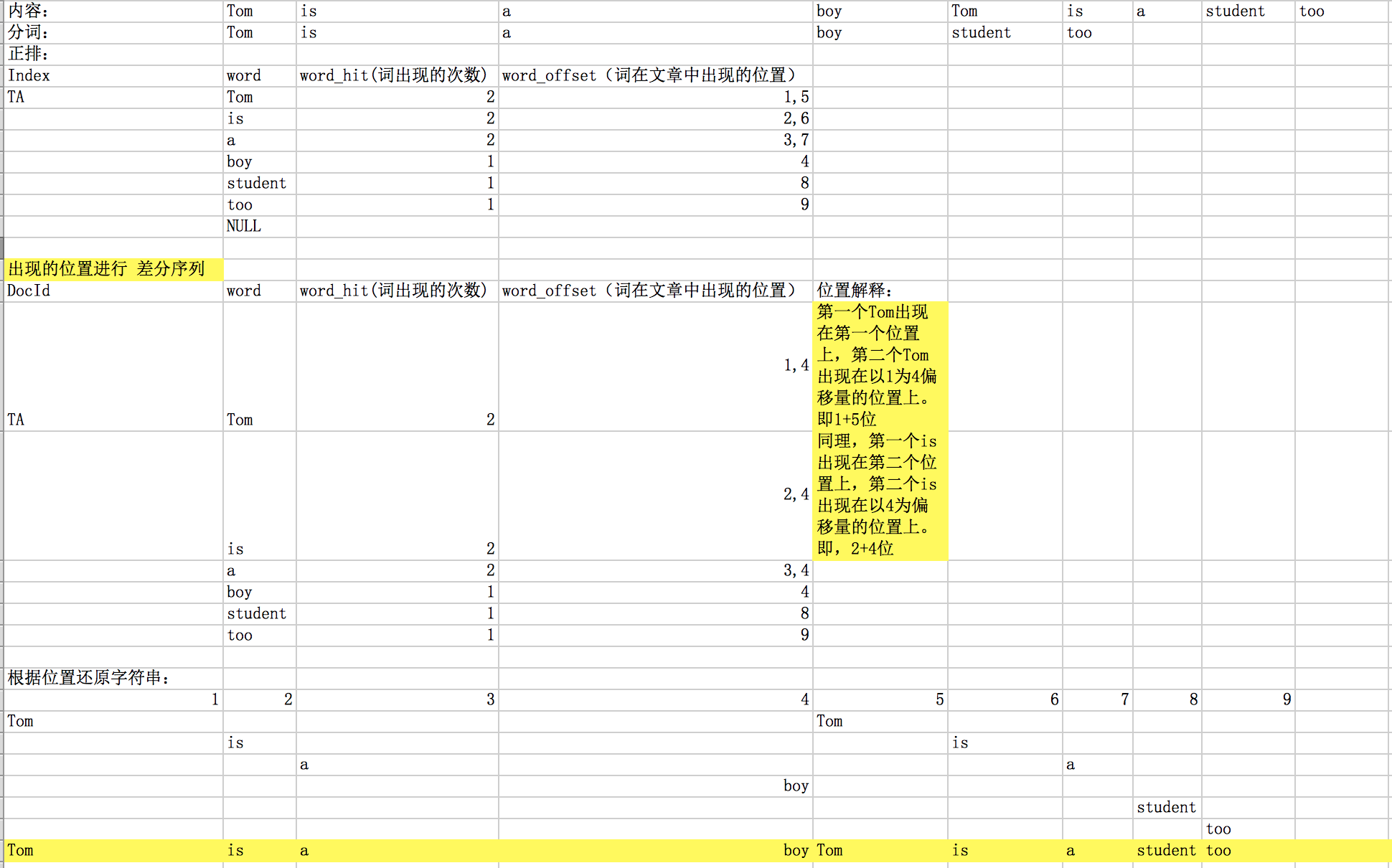
从上面的介绍可以看出,正排是以 docid 作为索引的,但是在搜索的时候我们基本上都是用关键词来搜索。所以,试想一下,我们搜一个关键字(Tom),当100个网页的10个网页含有Tom这个关键字。但是由于是正排是doc id 作为索引的,所以我们不得不把100个网页都扫描一遍,然后找出其中含有Tom的10个网页。然后再进行rank,sort等。效率就比较低了。尤其当现在网络上的网页数已经远远超过亿这个数量后,这种方式现在并不适合作为搜索的依赖。
不过与之相比的是,正排这种模式容易维护。由于是采用doc 作为key来存储的,所以新增网页的时候,只要在末尾新增一个key,然后把词、词出现的频率和位置信息分析完成后就可以使用了。
所有正排的优点是:易维护;缺点是搜索的耗时太长;
倒排索引:
由于正排的耗时太长缺点,倒排就正好相反,是以word作为关键索引。表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
倒排包含两部分:
1、由不同的索引词(index term)组成的索引表,称为“词典”(lexicon)。其中包含了各种词汇,以及这些词汇的统计信息(如出现频率nDocs),这些统计信息可以直接用于各种排名算法。
2、由每个索引词出现过的文档集合,以及命中位置等信息构成。也称为“记录表”。就是正排索引产生的那张表。当然这部分可以没有。具体看自己的业务需求了。
下面是一个简单的倒排索引构建,只包含第一部分的。

倒排的优缺点和正排的优缺点整好相反。倒排在构建索引的时候较为耗时且维护成本较高,但是搜索耗时短。
初步的介绍就先到这。更深入的研究可以自己搜索一些资料。
参考:
https://blog.csdn.net/zhangzeyuaaa/article/details/48676775
https://blog.csdn.net/GarfieldEr007/article/details/50479074
https://zh.wikipedia.org/zh-hans/%E5%80%92%E6%8E%92%E7%B4%A2%E5%BC%95
https://riteme.github.io/blog/2016-11-29/delta-and-stirling.html(差分序列)