不相交集合数据结构的概念和操作:
不相交集合数据结构(disjoing-set data structure)保持一组不相交的动态集合S={S1,S2,S3,……Sk}。每个集合通过一个代表来识别,代表即集合中的某个成员。
不相交集合数据结构支持如下操作:
1 . MAKE_SET(x): 建立一个新的集合,其唯一成员就是x,所以其代表也就是自己。因为各集合是不相交的,故要求x没有在其他集合中出现过。
2 . UNION(x,y): 将包含x和y的动态集合(比如说Sx和Sy)合并为一个新的集合(即这两个集合的并集)。假定这个操作之前是不相交的。在经过此操作后,所得集合的代表可以是Sx U Sy中的任何一个成员,但在UNION的很多实现细节中,都选择Sx或Sy的代表作为新的代表。由于要求各集合是不相交的,故我们“消除”集合Sx和Sy,把它们从S中删去。
3 . FIND_SET(x):返回一个指针,指向包含x的(唯一)集合的代表。
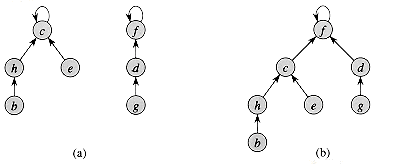
不相交数据集合一般用链表或森林(有根树,如下图)来实现,有根树的速度更快。用有根树来表示集合,树中的每个节点都包含集合的一个成员,每棵树都表示一个集合。从下图中可知,不相交森林中,每个成员仅指向其父节点。每个树的根包含了代表,并且是它自己的父节点。尽管采用了这种表示的直观算法并不比采用链表表示的直观算法并不比采用链表表示的算法更快,但是,通过引入两种启发式策略(“按秩合并”和“路径压缩”),就可以获得目前已知的,渐进意义上最快的不相交集合的数据结构。
改进运行时间的启发式策略:
1.按秩合并,其思想是是用包含较少节点的树的根指向包含较多节点的树的根。我们并不显式地记录以每个节点为根的子树大小,而是采用了一种能够简化分析的方法。对每个节点,用秩表示节点高度的一个上界。在按秩合并中具有较小秩的根在UNION操作中要指向具有较大秩的根。
2.路径压缩,它非常简单而有效。如下图所示,在FIND_SET操作中,利用这种启发式策略,来使查找路径上的每个节点都直接指向根节点。路径压缩并不改变节点的秩。

不相交集合森林的伪代码:

带路径压缩的FIND_SET过程也是相当简单的:
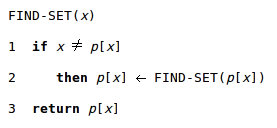
过程FIND_SET是一种两趟方法,也就是说它干了两件事:
1.沿着路径上升,找到代表。
2.修改路径上的元素的p域,使其指向代表。
代码示例:
public void make_set(int x) {/* 创建一个单元集 */
pa[x] = x;
rank[x] = 0;
}
public int find_set(int x) {/*带路径压缩的查找 */
/* 保存待查找的数 */
if(x != pa[x])
pa[x] = find_set(pa[x]);
return pa[x];
}
/* 按秩合并x,y所在的集合 */
public void union_set(int x, int y) {
x = find_set(x);
y = find_set(y);
if (x == y)
return;
if (rank[x] > rank[y])/* 让rank比较高的作为父结点 */
{
pa[y] = x;
} else {
pa[x] = y;
if (rank[x] == rank[y])
rank[y]++;
}
}
不相交集合数据结构的一个应用:
不相交集合数据结构有多种应用,其中之一是用于确定一个无向图中连通子图的个数。在下面给出的过程CONNECTED_COMPONENTS中,利用了不相交集合操作来计算一个图的连通子图。一旦CONNECTED_COMPONENTS作为预处理步骤执行后,过程SAME_COMPONENT回答两个顶点是否在同一连通子图的查询。
参考:http://blog.csdn.net/lalor/article/details/7388524、《算法导论》
版权声明:本文为博主原创文章,未经博主允许不得转载。