感谢tengine团队愿意无私的分享他们所编写的Nginx学习书籍
http://tengine.taobao.org/book/index.html
众所周知,nginx性能高,而nginx的高性能与其架构是分不开的。那么nginx究竟是怎么样的呢?
我们可以看到,nginx是以多进程的方式来工作的,当然nginx也是支持多线程的方式的,只是主流的方式还是多进程的方式,也是nginx的默认方式。nginx的进程模型,可以由下图来表示:
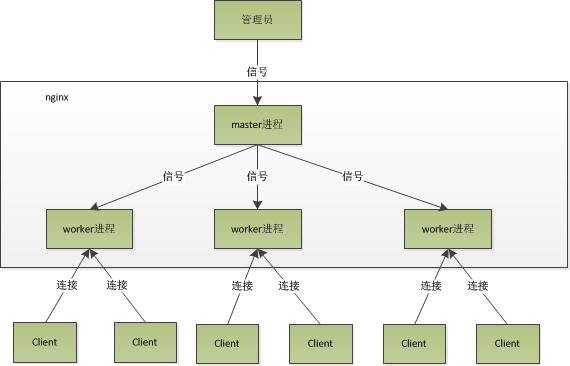
如果我们要操作nginx,只需要与master进程通信就行了。aster进程会接收来自外界发来的信号,再根据信号做不同的事情。
所以我们要控制nginx,只需要通过kill向master进程发送信号就行了。比如kill -HUP pid,则是告诉nginx,从容地重启nginx,我们一般用这个信号来重启nginx,或重新加载配置,因为是从容地重启,因此服务是不中断的。
master进程在接到信号后,会先重新加载配置文件,然后再启动新的worker进程,并向所有老的worker进程发送信号,告诉他们可以光荣退休了。新的worker在启动后,就开始接收新的请求,而老的worker在收到来自master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出。
nginx在0.8版本之后,引入了一系列命令行参数,来方便我们管理。比如,./nginx -s reload,就是来重启nginx,./nginx -s stop,就是来停止nginx的运行。如何做到的呢?我们还是拿reload来说,我们看到,执行命令时,我们是启动一个新的nginx进程,而新的nginx进程在解析到reload参数后,就知道我们的目的是控制nginx来重新加载配置文件了,它会向master进程发送信号,然后接下来的动作,就和我们直接向master进程发送信号一样了。
一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。(跟我们这边的代码很像,我们这边是抓拍时起八个线程抢,这边是八个进程抢)。
nginx采用了异步非阻塞的方式来处理请求,也就是说,nginx是可以同时处理成千上万个请求的。
为什么nginx可以采用异步非阻塞的方式来处理呢,或者异步非阻塞到底是怎么回事呢?
我们先回到原点,看看一个请求的完整过程。首先,请求过来,要建立连接,然后再接收数据,接收数据后,再发送数据。具体到系统底层,就是读写事件,而当读写事件没有准备好时,必然不可操作,如果不用非阻塞的方式来调用,那就得阻塞调用了,事件没有准备好,那就只能等了,等事件准备好了,你再继续吧。阻塞调用会进入内核等待,cpu就会让出去给别人用了,对单线程的worker来说,显然不合适,当网络事件越多时,大家都在等待呢,cpu空闲下来没人用,cpu利用率自然上不去了,更别谈高并发了。好吧,你说加进程数,这跟apache的线程模型有什么区别,注意,别增加无谓的上下文切换。所以,在nginx里面,最忌讳阻塞的系统调用了。不要阻塞,那就非阻塞喽。非阻塞就是,事件没有准备好,马上返回EAGAIN,告诉你,事件还没准备好呢,你慌什么,过会再来吧。好吧,你过一会,再来检查一下事件,直到事件准备好了为止,在这期间,你就可以先去做其它事情,然后再来看看事件好了没。虽然不阻塞了,但你得不时地过来检查一下事件的状态,你可以做更多的事情了,但带来的开销也是不小的。所以,才会有了异步非阻塞的事件处理机制,具体到系统调用就是像select/poll/epoll/kqueue这样的系统调用。它们提供了一种机制,让你可以同时监控多个事件,调用他们是阻塞的,但可以设置超时时间,在超时时间之内,如果有事件准备好了,就返回。
线程只有一个,所以同时能处理的请求当然只有一个了,只是在请求间进行不断地切换而已,切换也是因为异步事件未准备好,而主动让出的。这里的切换是没有任何代价,你可以理解为循环处理多个准备好的事件,事实上就是这样的。与多线程相比,这种事件处理方式是有很大的优势的,不需要创建线程,每个请求占用的内存也很少,没有上下文切换,事件处理非常的轻量级。并发数再多也不会导致无谓的资源浪费(上下文切换)。更多的并发数,只是会占用更多的内存而已。 原文作者之前有对连接数进行过测试,在24G内存的机器上,处理的并发请求数达到过200万。现在的网络服务器基本都采用这种方式,这也是nginx性能高效的主要原因。
由于epoll_wait等函数在调用的时候是可以设置一个超时时间的,所以nginx借助这个超时时间来实现定时器。nginx里面的定时器事件是放在一颗维护定时器的红黑树里面,每次在进入epoll_wait前,先从该红黑树里面拿到所有定时器事件的最小时间,在计算出epoll_wait的超时时间后进入epoll_wait。所以,当没有事件产生,也没有中断信号时,epoll_wait会超时,也就是说,定时器事件到了。这时,nginx会检查所有的超时事件,将他们的状态设置为超时,然后再去处理网络事件。由此可以看出,当我们写nginx代码时,在处理网络事件的回调函数时,通常做的第一个事情就是判断超时,然后再去处理网络事件。
用一段伪代码来总结一下nginx的事件处理模型:
while (true) {
for t in run_tasks:
t.handler();
update_time(&now);
timeout = ETERNITY;
for t in wait_tasks: /* sorted already */
if (t.time <= now) {
t.timeout_handler();
} else {
timeout = t.time - now;
break;
}
nevents = poll_function(events, timeout);
for i in nevents:
task t;
if (events[i].type == READ) {
t.handler = read_handler;
} else { /* events[i].type == WRITE */
t.handler = write_handler;
}
run_tasks_add(t);
}